







本节使用Jsoup获取网页源码,并且解析数据。
使用JSoup 解析网页,语法使用 JS,css,Jquery 选择器语法,方便易懂
抓取网站:http://www.oschina.net/news/list 开源中国-新闻资讯模块
基本工作:
1.创建好Java工程,包等基本工作。
2.导入Jsoup所依赖的jar包。官网下载地址如下:
http://jsoup.org/packages/jsoup-1.8.1.jar
3.创建JsoupDemo类。(类名自己随意,java基础,没必要多说吧)
核心内容
1.在main函数中使用Jsoup获取网页源码
String url = "http://www.oschina.net/news/list";
Document document = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/30.0")
.get();
此段代码意思为使用Jsoup链接url地址,并且返回封装该网页的html源码的Document树,userAgent为模拟浏览器头,get为使用get方式提交,关于connect的参数还有很多,请自行查看API学习。
2.分析网页源码
在目标网页上点击右键,火狐有使用FireBug查看元素,谷歌有审查元素,然后可以看到相应的源码和网页的对应情况。如下图(以后都以谷歌浏览器为例):
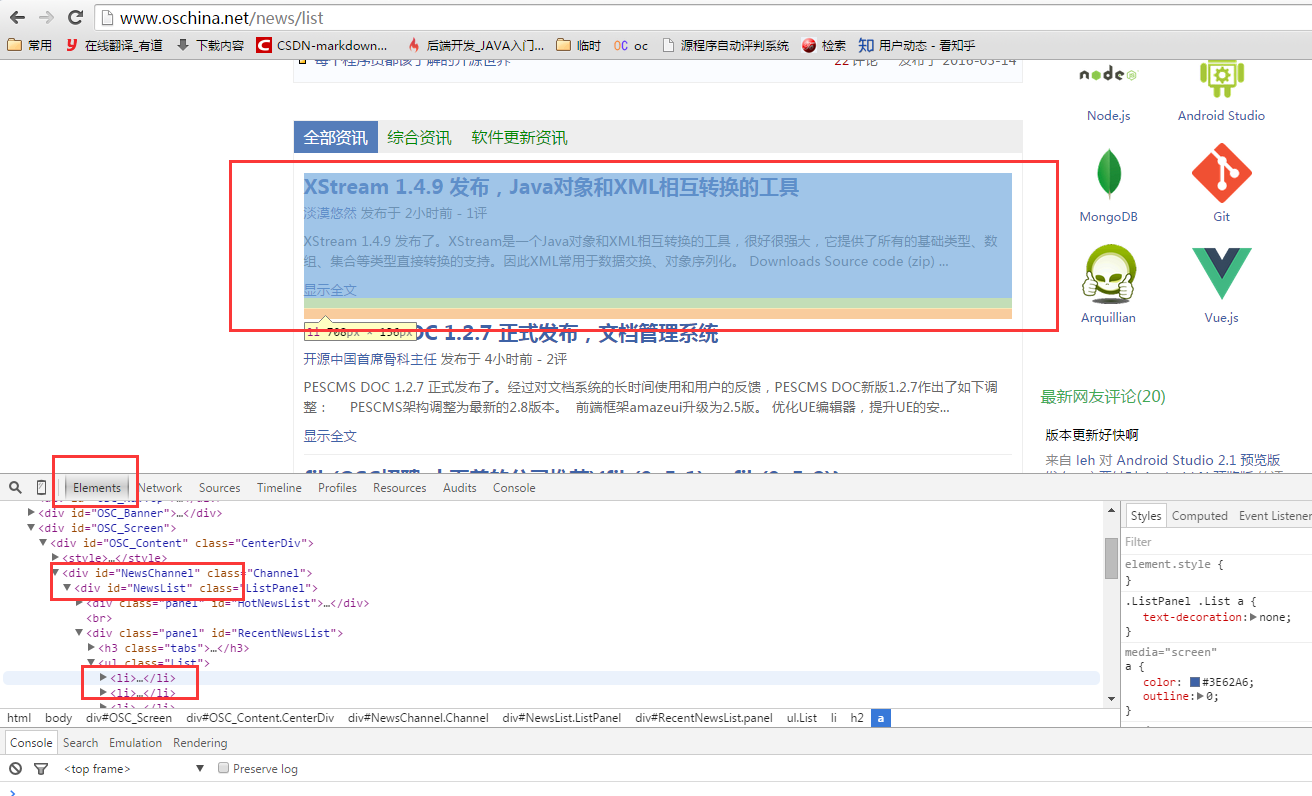
可以看到我们所需要的数据都在id="RecentNewsList "的div下的class="List"的ul下,并且每一条都对应一个li标签,那么我们只需要找到class=”List”的ul,并且遍历它的li标签就可以获取到所有的信息的源码。代码如下:
Elements elements = document.select("#RecentNewsList .List > li");这里说一下常用的选择器:
**#RecentNewsList 代表选择id="RecentNewsList "的标签 #为id选择器
.List 代表选择class="List"的标签 .为class选择器
li 表示li标签
‘>’ 只能选择子标签,直接为父元素后代的直系子元素,比如儿子,孙子关系,只能选择儿子。下一级的。**
select中可以写多个,注意使用空格隔开,也可以连续使用select。
3.遍历操作元素集(Elements)
for (Element element : elements) {
Elements titleElement = element.select("h2 a");
String title = titleElement.text();
String link = titleElement.attr("href").trim();
Elements dataElement = element.select(".date");
Elements autherElement = dataElement.select("a");
String auther = autherElement.text();
autherElement.remove();
String date = dataElement.text();
String detail = element.select(".detail").text();
System.out.println("链接: " + "http://www.oschina.net"+link);
System.out.println("标题: " + title);
System.out.println("作者: " + auther);
System.out.println("发布时间: " + date);
System.out.println("详细信息: " + detail);
System.out.println();
System.out.println();
}程序运行结果如下:
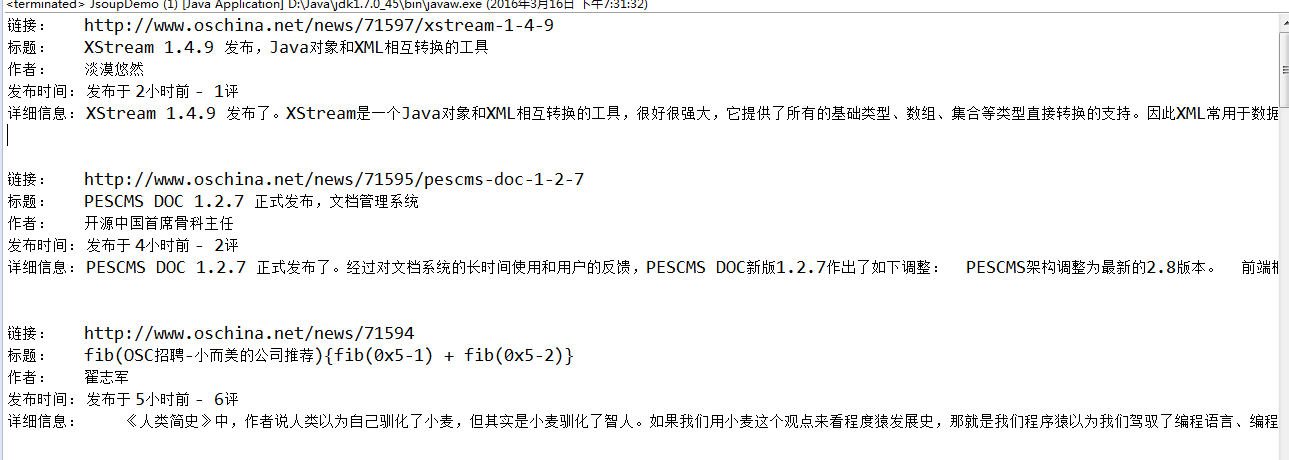
也可以输出元素集的长度System.out.println(elements.size());
完整代码如下:
package demo;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
*
* 使用JSoup 解析网页,语法使用 JS,css,Jquery 选择器语法,方便易懂
*
* Jsoup教程网:http://www.open-open.com/jsoup/
*
* @author geekfly
*
*/
public class JsoupDemo {
public static void main(String[] args) throws IOException {
String url = "http://www.oschina.net/news/list";
Document document = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/30.0")
.get();
Elements elements = document.select("#RecentNewsList .List > li");
for (Element element : elements) {
Elements titleElement = element.select("h2 a");
String title = titleElement.text();
String link = titleElement.attr("href").trim();
Elements dataElement = element.select(".date");
Elements autherElement = dataElement.select("a");
String auther = autherElement.text();
autherElement.remove();
String date = dataElement.text();
String detail = element.select(".detail").text();
System.out.println("链接: " + "http://www.oschina.net"+link);
System.out.println("标题: " + title);
System.out.println("作者: " + auther);
System.out.println("发布时间: " + date);
System.out.println("详细信息: " + detail);
System.out.println();
System.out.println();
}
System.out.println(elements.size());
}
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









