







本文首发在我简书的账号上,原文地址:http://www.jianshu.com/p/7a875e09d4e1
《易经·系辞》有云:“形而上者谓之道,形而下者谓之器”。同理,任何技术都可以从道和器的角度去解读,一门技术,只知道器不知道道,走不远,只知道道而不知道器,啥也干不了,只能空口吹牛逼!谈及大数据时亦如此,本文着重道的层面。
总览
国内大数据这词比较火是从2012年左右开始的,从那时起,各大媒体、公司开始疯狂吹棒大数据、云计算,很多大数据、云计算八杆子打不着的产品也给自己起了个响当当的名字叫某某云,逼格可不小!
国外大数据在0几年就有应用了。03年,Google发表了一篇名为The Google File System的论文,论文中提出了一种分布式文件系统,可见人家早已有研究。可巧的是,当时有个叫Doug Cutting的大叔正在开发一个开源搜索引擎Nutch,受此论文启发,大叔瞬间获得了洪荒之力,一口气写了一个开源的分布式文件系统—Nutch Distributed File System。
04年,Google再次放大招,发表了MapReduce,Simplified DataProcessing on Large Clusters的论文,那位大叔再次将MapReduce计算模型实现了。
06年1月,Yahoo启动Hadoop项目,Nutch Cutting大叔也加入了雅虎,就这样Nutch项目变成了Hadoop他爹,Hadoop从他爹那里继承了两样重量级的东西,一个是分布式文件系统NDFS,Hadoop重命名为HDFS,另一个就是MapReduce计算模型。
06年2月,Apache Hadoop项目正式启动,至此,第一个开源的大数据计算平台诞生了。
Hadoop主要解决了大数据处理的2个问题,其一是海量数据的存储,其二是海量数据的计算。有了Hadoop,大数据处理问题是不是都解决了呢?程序员们同意,但是现实需求不同意啊!有了新需求,你不去解决,总有人解决!于是,大数据计算平台在和现实需求赛跑的这场马拉松中,跑到了现在,在决战现实需求的过程中,他们演化成了四支队伍,分别应对不同的需求,目前这四支队伍及其代表如图1所示。
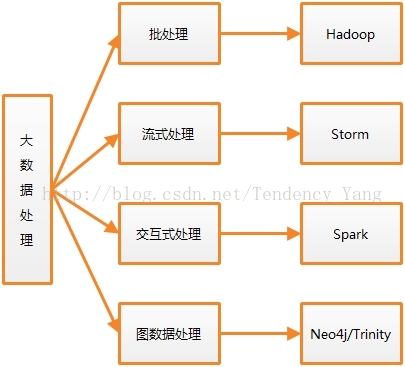
图1 大数据计算平台的四支队伍
从图1中,我们可以看出这四支队伍分别是以Hadoop为代表大数据批处理平台、以Storm为代表的大数据流式处理平台、以Spark为代表的大数据交互式处理平台和以黑客帝国里男女主角命名的大图数据处理平台。下面分别去拜访一下他们。
Hadoop
前面提到,Hadoop早在06年2月的时候就在Apache开源了,发展到今天,其稳定版本已经到2.8版本了,本文写作时,Hadoop3.0已开始了Alpha测试。目前Hadoop包括的模块如图2所示。
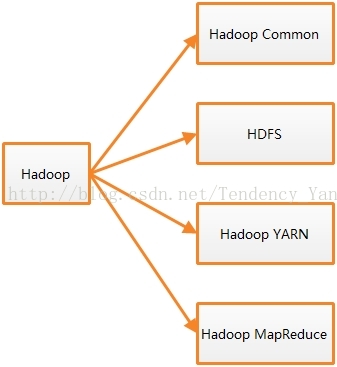
图2 Hadoop模块一览
从图2中可以看出,目前Hadoop包括四大模块。Hadoop Common,Hadoop里的雷锋同志,专为大家提供公共服务的。HDFS,专治海量数据存储的。Hadoop YARN(Yet AnotherResource Negotiator),Hadoop2.X新成员,主管集群资源协调,集群资源利用率低就找他麻烦了(哈哈)。Hadoop MapReduce,海量数据计算编程模型,使用MapReduce编程处理大数据,主要分两步,首先实现Mapper接口的map方法,将输入的key-value键值对转化为中间状态的key-value键值对输出,比如,在wordCount中,输入的key-value键值对中key是该行文本首字符在文本中的偏移量,value自然就是文本行,经过map方法转换后,key值是文本行经过分割后的单词,value是1。之后再实现Reducer接口的reduce方法,对输入的键值对按照key进行规约输出即可,在wordCount中,输入的key就是单词,value是这个单词出现次数的迭代器(iterator),reduce方法累加迭代器中的值,最后输出每个单词及其出现次数的key-value对。
那么,在变化无穷的现实需求面前,Hadoop是不是无懈可击呢?或者说他强大的背后有哪些缺点呢?
现实需求和程序员们发现,Hadoop有两个大“缺点”,其一,延迟高,无法进行实时处理。这没什么奇怪的,Hadoop计算的数据主要存放在磁盘上,需要不断访问磁盘,速度不慢才怪,再者,Hadoop的基因是批处理,追求的是高吞吐量,不是低延迟。其二,Hadoop MapReduce编程模型为大数据计算带来简单的同时也带来了复杂。简单是实现了map、reduce方法即可,复杂是现实需求不是wordCount那么简单的(都是需求惹的祸),往往需要多重map、reduce。这就麻烦了,map来reduce去的,最后不知道reduce到哪去了,高层的需求逻辑被深深地掩埋在各种低层的map、reduce中!这就好比C/C++中的指针,指来指去,最后不知道飞哪儿去了,不是谁都可以驾驭好的。
大牛们在躺了Hadoop的那些坑后,决定自己填一下这些坑,于是有了新的大数据计算平台,Storm就是为填Hadoop高延迟的坑而诞生的。
Storm
Storm填了Hadoop高延迟的坑,而且填得平平整整,使大数据实时计算触手可及。Storm采用内存来存计算的数据,计算速度那是相当的快,其在官方公布的数据中,1秒钟可以处理百万条元组。Storm对一个计算的高级抽象叫Topology(拓扑),其结构如图3所示。
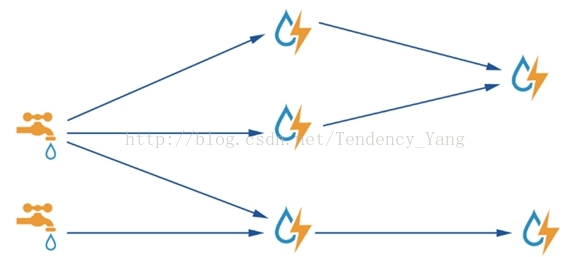
在图3中,长得像水龙头那样的叫Spout,是Storm拓扑中的数据源,负责向拓扑发射数据。长得像闪电那样的叫Bolt,负责处理上游来的数据,将处理结果持久化或者发射到下游Bolt。整个Storm拓扑就是一个有向无环图(DAG),显然其是一种基于图进行计算的思想,后面还会遇到这种计算思想。
在集群中运行时,Storm借助Zookeeper对各个组件进行协调,集群环境下的Storm如图4 所示。
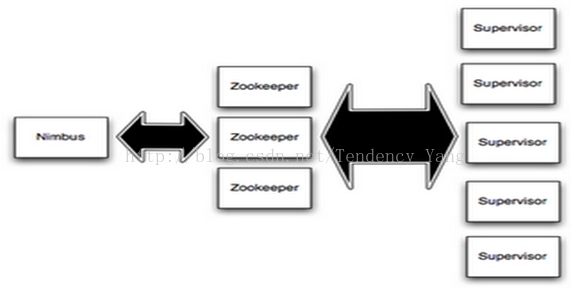
图4 集群中的Storm
从图4可以看出,和Hadoop一样,集群中的Storm也是主从架构。主控节点运行Nimbus守护进程,负责任务分发和监听从节点的状态,各个从节点运行Supervisor守护进程,负责执行任务并向主节点报告状态信息。Zookeeper本身就是一个集群管理器,当然干它本职的工作了。
Storm已经填好了Hadoop高延迟的坑,但是没有填MapReduce的坑,Storm采用的是和MapReduce不一样的计算模型,这个坑Spark来填。
Spark
在Hadoop里面map来reduce去,最后不知道reduce到哪去了,Spark把这个坑给填了,而且填得非常完美!Spark继承了MapReduce的很多思想,当然也有很多自己的创新,这才是关键。Spark的编程API抽象层次相当高,把底层的各种map、reduce给屏蔽了,甚至把集群中可以屏蔽的细节一并屏蔽掉,这些东西对开发人员是透明的。在Spark中,直接面向高层的业务逻辑编程,具体底层是怎么map、reduce的,Spark帮我们做好了,不会存在map、reduce迷路的现象了。Spark还有一大突破是大数据交互式处理,Spark提供了Python和Scala的shell,在shell环境下,对大数据的计算,输入命令回车即可得结果(Spark也是基于内存计算的,相当快!),这一点是整个大数据处理的一大突破,不得不给Spark点赞!Spark的架构如图5所示。

图5 Spark架构
图5展示了Spark的各个方面。SparkCore是Spark的内核部分,Spark SQL是Spark的结构化数据操作组件。Spark Streaming是Spark流式大数据处理的组件,对!不只是Storm能够进行流式大数据处理,Spark也可以,而且Spark的流式计算API抽象层次更高,当然编程也就更简单。MLib是Spark的机器学习库,GraphX则是Spark针对大图数据提供的计算库。以上是Spark的主要编程库,Spark要在集群中运行,还需要一个东西,集群管理器。这块Spark也做得很好,提供了自己的集群管理器(Standalone),不需要依赖第三方集群管理器就可以轻松部署Spark集群。当然,Spark也支持第三方集群管理器,Spark的集群管理器设计为可插拔的。目前,Spark支持比较好的集群管理器是YARN和Mesos。
集群中的Spark同样是主从架构,主控节点运行Spark驱动器程序,负责任务分发、协调和监听各从节点状态,从节点负责任务执行和状态汇报。
大图数据计算
图是由若干结点和边组成的数据结构,这个大学数据结构课里就学过了。当图有成千上万个结点,再加上成千上万条边时,对图数据的快速计算无疑是有挑战的,比如实时规划最短路径。针对这一需求,Google、Microsoft等公司提出了自己的解决方案,Google有Pregel,微软则一不做二不休,搞了两个,还生怕名气不大,干脆用the Matrix里的男女主角来命名,分别叫做Neo4j和Trinity。
“知之为知之,不知为不知”,关于大图数据计算,我目前还没有遇到这样的场景,当然也没有基于Neo4j和Trinity编程过,本节到此为止。
入门建议
本节专为想入门大数据处理的新人而写,大神请跳过!
“我想入门大数据处理,但是看到这些五花八门的技术,心生恐惧,无从下手,怎么办?”,一位学弟这样问我。是的,学大数据处理是有门槛的,各种大数据计算框架都是分布式的,集群来集群去的,我哪有那么多硬件资源可用?可是这已经成为过去时了,Hadoop时代是这样的,现在不是了!这或许也是Hadoop的不足吧。Storm和Spark这些后出来的技术都在变得对程序员越来越友好,开发、运行Storm和Spark应用程序不需要什么集群支持,你现在写代码的PC机就够了,因为Storm和Spark都支持本地模式运行。在Maven里面加入相应依赖后,即可基于它们的API编程了。
所以,我推荐的学习路径不是从Hadoop开始,而是从Storm或者Spark开始,先把那个经典的wordCount跑起来,再去考虑集群环境部署之类的,有一定的积累后,再去部署Hadoop进行开发,当然在之前是可以看Hadoop的编程思想的,必究后来者从它哪里继承了不少东西。
总结
至此,本文啰嗦了半天,终于介绍完了到目前为止,在与变化无穷的现实需求赛跑中成长起来的四支优秀的大数据计算队伍。都说是队伍,每支队伍里面还有很多队员,本文只是抛砖引玉。
最后再啰嗦一句,大数据计算与现实需求在进行的是一场没有终点的马拉松赛跑,随着需求的变化,大数据计算的队伍也会不断地革新。














 8873
8873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









