






动机
用关系模型描述XML数据
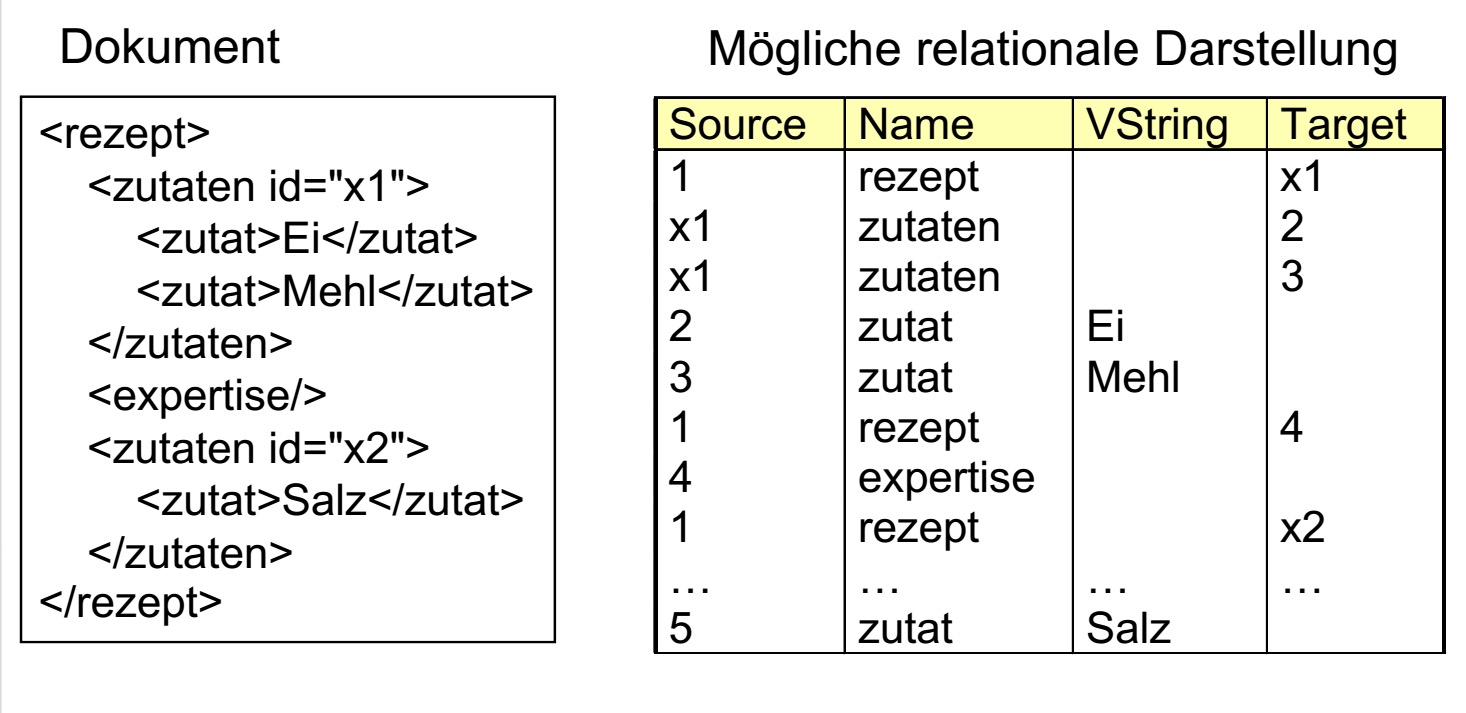
//感觉有点像是先把XML文件先变换成对应的树结构,然后再在关系表中逐条路径进行描述(感觉就是对XML文件的数据路径的描述)。每个内部阶段出现的次数,为以其位根的子树的叶子数。但如果这样看得化,其实也可以不用像这样,感觉有点像链的方式进行排列,直接逐层往下写也是可以的。
这是一个XML文档具体化的(关系的)视图的例子(Beispiel für (relationale) materialisierte Sicht auf das XML Dokument.)
//转化成关系模型,这个可以看出来,但是具体化是指什么???
能否使用关系模型来进行描述,和文档原本的类型并没有关系。
(Relationale Darstellung ist Dokumenttyp-unabhängeig)
//这也说得太满了吧!!
/*不知道在这里说这些是什么意思
relationale Sicht auf XML-Dokument:XML文档的关系视图
XQuery-Statement formulierbar, das aus Dokument Relation generiert.??
materialisierte relationale Sicht:具体化关系视图
*/
另外,说是上图中的关系表不符合EDGE Modell???可是我连这个Modell是啥东西都不知道??
除此之外还有有上图也可以看出这个关系表并不是标准化的(normalisiert)(比如第二和第三项),那么应该怎么是他标准化呢??标准化之后由会有什么优势呢??
我们可以把上面的一个关系表分裂成三个。每个关系表只包含有两个属性(Source+XXX)。
但这样做也是存在一些缺点的,比如,重这三个关系表要重新生成对应的树结构的时候,他对应的时间消耗会高很多。
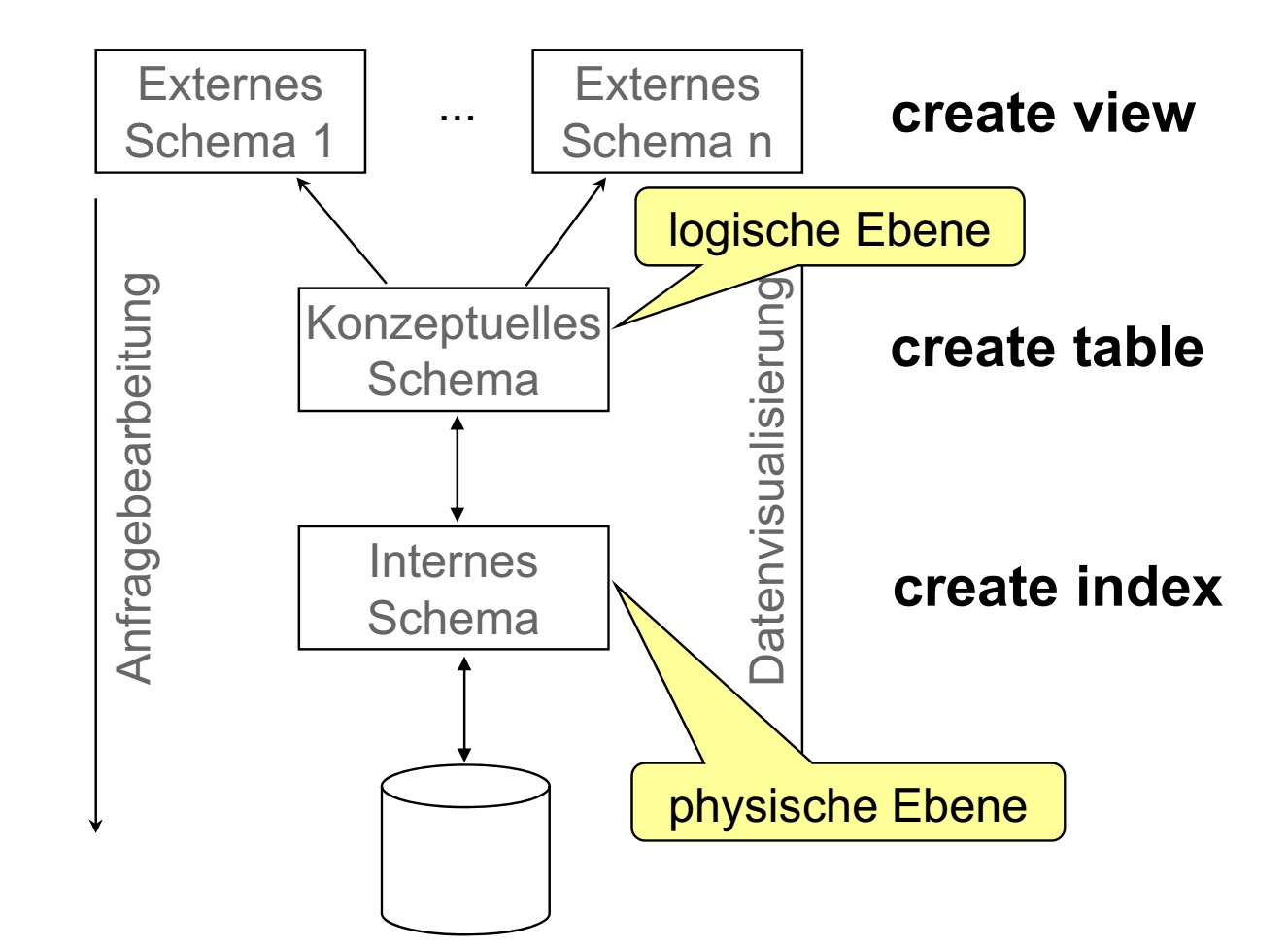
数据库的三层结构两层映像
这个就不说了,图解
局限(Abgrenzung)
- 这里将不会讨论Native XML Database的情况。(NXD可以保留数据的物理结构。他可以在不知道DTD的情况下,对一个XML文件进行存储。而且对NXD的访问是通过基于XML的技术实现的,比如XQuery,XPath或DOM等)
- 实现一个完整的XML-DBMS(包括)开销是很大的(Implementierung eines vollständigen XML-DBMS(inkl. Nebenläufigkeit, Recovery, usw.) aufwendig.)//暂时理解不能
- 因此取而代之的,我们使用半结构化数据的具体化的关系视图(Stattdessen materialisierte relationale Sichten auf semistrukturierte Daten. Sichten indexierbar.??)
- 数据库的功能性:比如并行控制等。就是执行效果可能不是很好//这个其实没懂,不知是指啥??(Datenbank-Funktionalität, z.B. Concurrency Control, Indices, “umsonst”. Wenn auch i.d.R. mit nicht besonders guter Performance.)
继续看动机
德语看的懂,但是就是体会不到
Viele interessante Ansätze verwenden: Schema(gemeint ist: XML-Schema bzw.DTD) oder nachträgliche Zusammenfassung des Datenbestands.
Unterscheidung zwischen ‘generisch’ und ‘dokumentspezifisch’/’Dokumenttyp-spezifisch’
能识别文档结构的系统的优势(Was hat man davon, dass System die Dokument-Struktur kennt)
- 加速访问(Beschleunigung der Queryevaluierung)
- 更好的存储(Bessere Speicherung, d.h. tendenziell weniger Seitenzugriffe für das Lesen)
- 定义索引(Definition von Indices)
- 有利于访问的表达(Unterstützung bei der Formulierung von Anfragen)
- 有利于进行更新(bessere Kontrolle über Updates)
//又是又看没懂系列???
Schema信息对访问的优化
这个在半结构化数据的声明性访问语言中已经解释过了,所以。。。继续吧
例子:
select Order.Company
where Order.OrderPerson = “Weber”
这个Query只有在Order.Company存在的条件下,才会有输出。因此如果能够在执行上述操作之前迅速的了解一下,对应的路径是否存在,将会有很大的帮助。
在存储的时候充分的利用结构
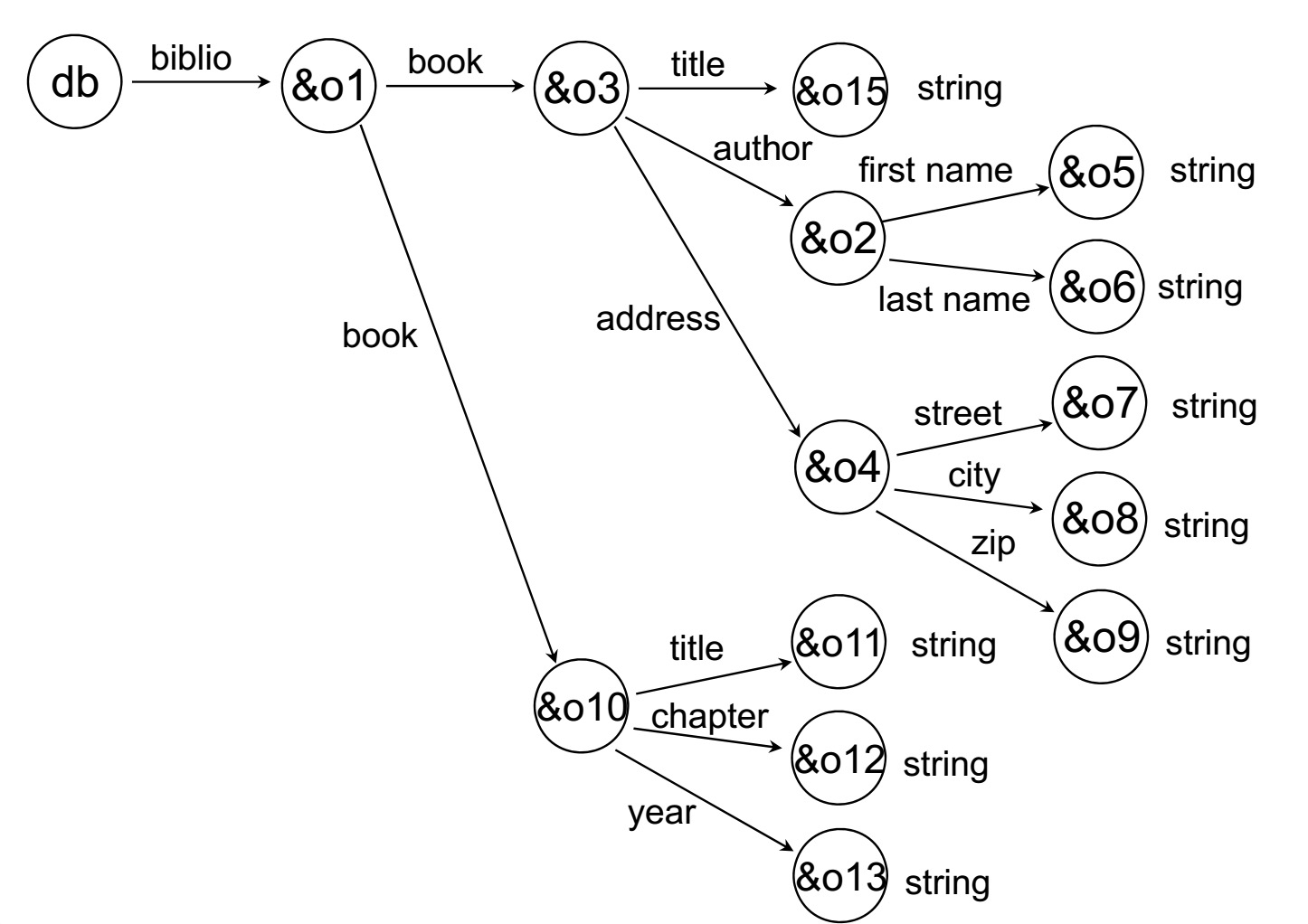
可能的Schema(也是一般情况下都适用的):
ref(source:oid, label:dom, destination: oid)
val(obj:oid, value:dom)
//和前面的例子一样
同样的用这个在描述这个树结构的时候,需要用到很多的Join来实现。显然这花费是很高的。
另外他在逻辑上有关联的数据,一般在物理上式分散的(这是好?还是不好??)(Daten, die logisch zusammengehören, sind i.d.R. Physisch verteilt.)
假如在有很多不同的书的情况下,我们希望得到下面这些信息很怎么样呢??
1. 输出所有的1900年的书的title
2. title叫Y得书是在哪一年出版的
现在假如我们使用一个特定的Chapter关系:
chapter(source:oid, title:string, text:string, year:string)
现在,我们再来处理前面的俩个问题,这次会有什么优势呢??
(Vorteil:Ein Zugriff für alle Daten eines Kapitels)
多层访问处理(Mehrstufiges Query Processing)
//这个真心半点没懂
∃
immer Queries,
die mit Hilfe des Index allein nicht evaluierbar.
(仅通过索引,不能实现存在性的查询??)
Ansatz:
1. Index, um Menge der Dokumente einzuschränken,(索引,用于限定文档的数量??)
2. Inspektion der verbleibenden Dokumente(Kandidaten)(d.h. ohne Zuhilfenahme eines Index)(在没有使用索引的情况下检索保留的文档??)
总结动机
- Motivation relationale Speicherung(EDGE-Modell wurde vorgestellt, zur Illustration)
- 在存储和访问时能充分的利用文档的结构
DataGuide
Volltext-Engine与Volltext-Indices
Volltext-Engine:
通过Volltext-Engine可以寻找文档中的特定字符串序列的。(Ermöglicht Suche nach Dokument, die bestimmte Zeichenfolge enthalten, unabhängig davon, wie genau sie vorkommen(z.B. im Text im Markup))
Volltext-Index:
Volltext-Index是一个基本的物理结构;像后缀树(Suffix-Baum)//所以上面这两个其实就是一个东西了,只不过一个是接口,一个是物理存储??
//Grundlage:Bestellungen, als XML这句什么意思???
举个例子,比如我们要找所有包含有Weber字符的文档。
Volltextindex解决不了的问题:
还是上面的例子,Weber可能出现在不同的Markup或Text中,比如公司或产品的名字都可以包含有Weber,而我们只想找出对应公司名包含有Weber的文档。而这是Volltextindex无法做到的。
如果index可以识别域(Feld)或甚至是每条路径上得文本,那则是极好的(Feldweiser Index wäre besser(‘Besteller’).Am besten:Index für Text unter jedem Pfad.
select Order.Company
where Order.Person = “Weber”
这点不理解???
)

这是index的一个例子。其中Schema为:
Student(name,age,gpa,major); t(Student)=16
//其实不知道前面说得那么多和这个由什么关系??前面说得不是找固定字符串吗??不是后缀树吗??为什么变成这了??
结构
Data Guide:是指数据库内容的一个具体的总结(Konkrete Zusammenfassung des Datenbankinhaltes)
另外需要说明的是,在这节中;
数据库
≡
文档的集合(Dokument-Kollektion)(包括单个文档)
此外数据库还是一个有向图(OEM的实例)
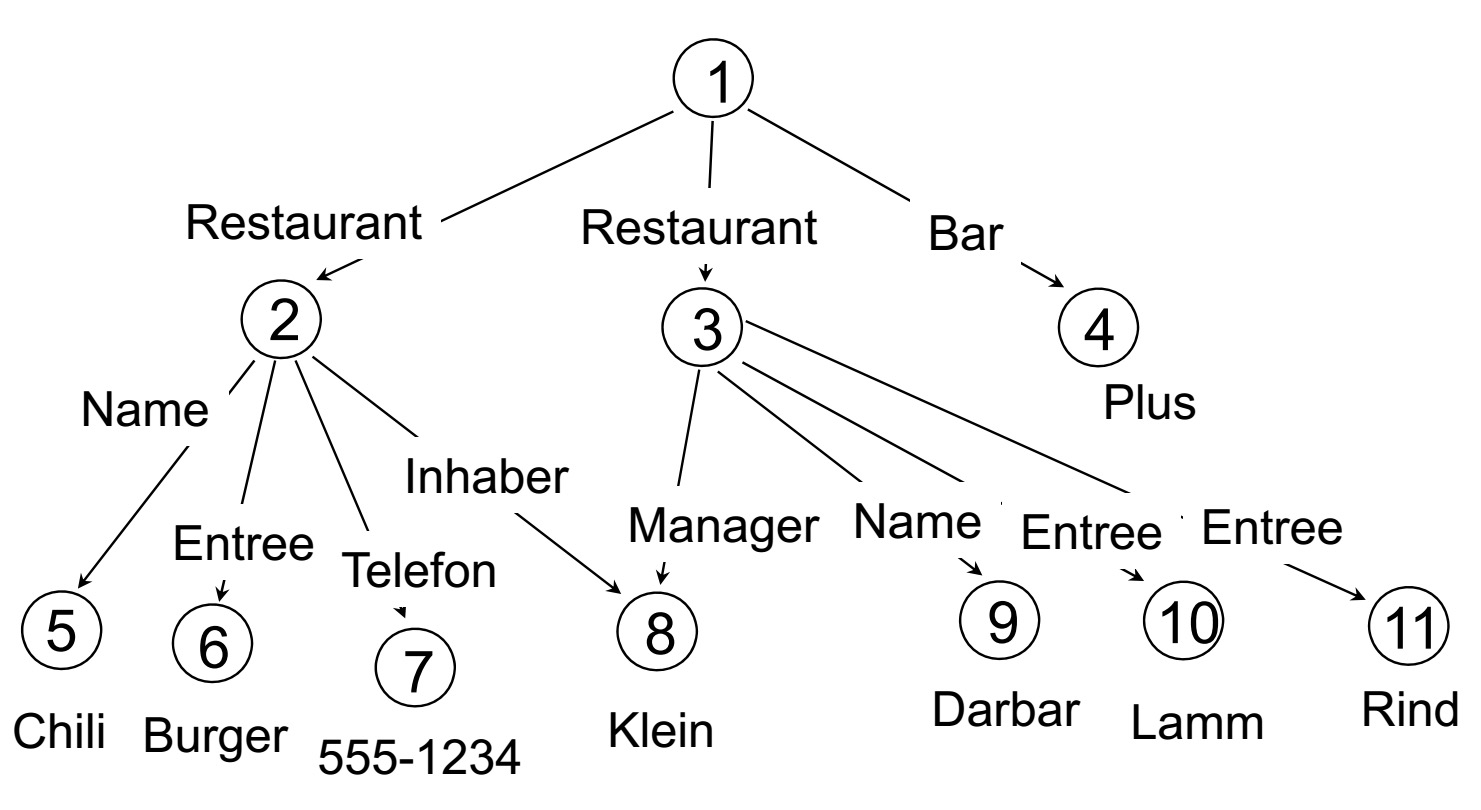
Data Guide:
一个数据库s的DataGuide d同时也是一个数据库,不过他应该满足以下条件:
1. s中的每一条路径对应着d中的一个数据路径实例(jeder label path in s genau eine data path-Instanz in d hat.)//见上上个图
2. d中的每一个标签路径(label path)同时也是s的标签路径。//也就是一一对应的关系了??标签路径不懂的话,就只能回去看一下声明性访问了。
通过DataGuide我们就能够很明显的看到,数据库中存在有哪些路径。
可以这么说DataGuide就是对数据库结构的一个简短的(kurze)精炼的(akkurate)同时是合适的(geeignet)总结。
说简短,是因为DataGuide对数据库中的每个路径只描述一次。
说精炼,是因为DataGuide不会描述不存在于数据库中的路径。
说合适,是因为DataGuide本身也是一个数据库,因此可以通过同样的方法进行访问。
//那么在执行Query的时候,DataGuide对我们有什么帮助呢??
DataGuide和Schema的区别:
DataGuide 是根据Datenbank生成的,反过来则是不成立的。而Schema恰好与DataGuide相反,是先生成的Schema然后数据库按照Schema进行生成的。(Unterschied zwischen DataGuide und Schema: DataGuide ist konform zur Datenbank, nicht umgekehrt.)
想想可否出现这种情况,也就是DataGuide和Schema存在不同(也就是说不是所有的属性都是一样的)。答案是肯定得,但为什么??(Denkbar, dass DataGuide und Schema nicht übereinstimmen- nicht alle Varianten, die Schema erlaubt, kommen tatsächlich vor.)
构建DataGuide
和从NEA生成DEA的方法相同(NEA指非确定性有限自动机,DEA指确定性有限自动机)
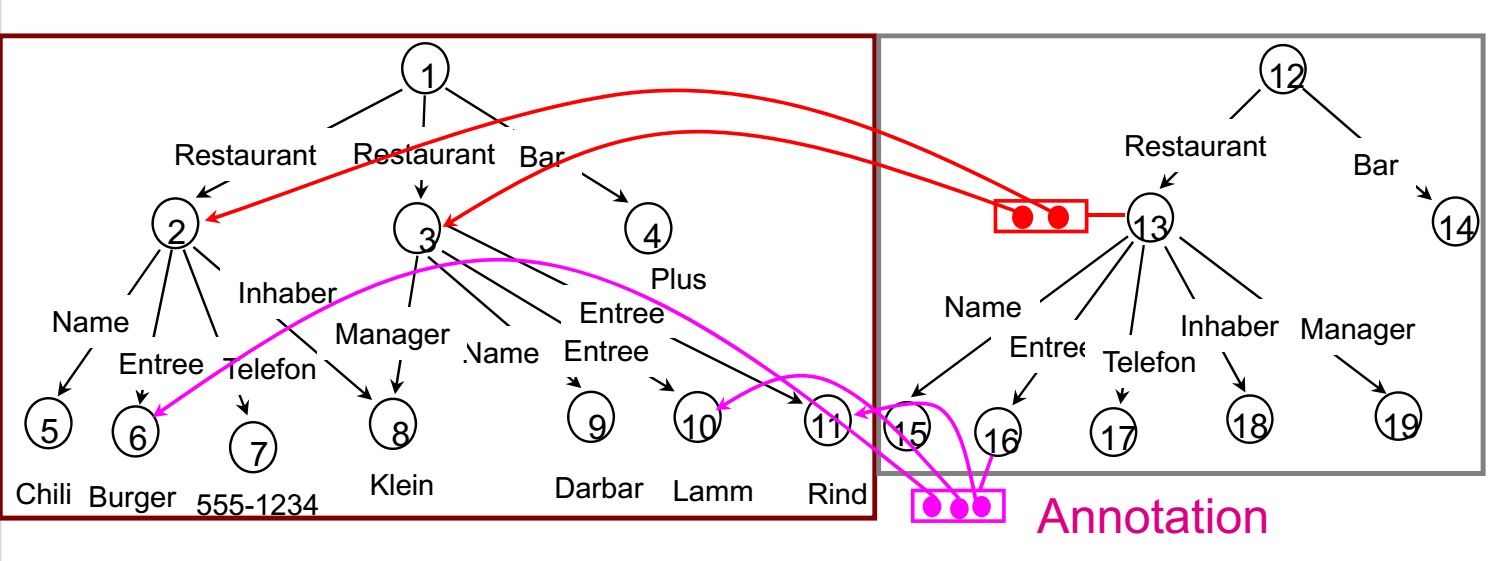
//箭头表示DataGuide的节点的Annotation??
由图可得,DataGuide 的存储结构的格式为:
||Label Path
→
{Objekt}||
(Annotationen der DataGuide-Knoten)
DataGuide的这种对节点的解释,对Query的操作很有帮助。//在哪??
Query操作
首先看几个例子:
1. 选择拥有一个Inhaber的restaurants
2. 选择所有的restaurants,要求他们或者Entree为Rind或者Entree为Lamm。
/*
Erstes Bullt-Kritisch, wenn ich nur in Richtung der Pfeile navigieren kann.
Grundlegenderes problem, das sich von diesem unterscheidet:
I. Allg. will ich nicht nur nach Pfaden, sondern nach Baum-Mustern suchen.??
*/
strong DGs
针对同一个数据库,可以构建不同的DataGuides
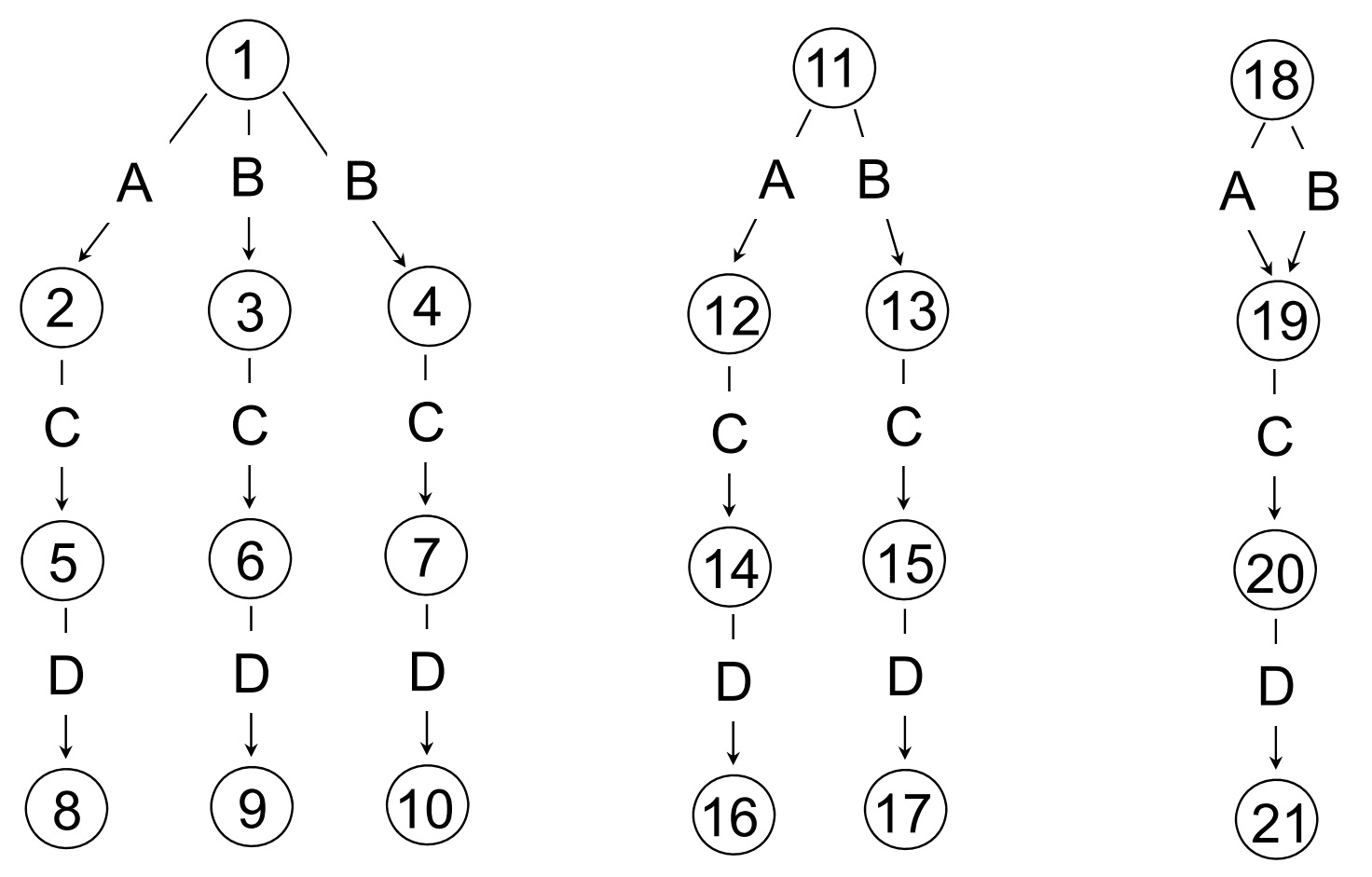
对于最左边的数据库存在右边两种DGs
存在最小化DGs的方法。
但这样坐存在一定的劣势:
1. 改变数据库需要很多工作
2. Annotationen weniger aussagerkräftig//这点不理解??是指模糊的意思吗??
strong DataGuides:
动机:使其Annotationen拥有最高的精度(Charakterisierung der DataGuides, deren Annotationen maximal präzise sind)
idea:DataGuide中拥有相同目标集的标签路径,在数据库中也总是拥有相同的目标集(Intuition: Label paths mit dem gleichen(singleton) Target Set im DataGuide haben stets das gleichen Target Set in der Datenbank.)
定义Strong DataGuides:
s,d为OEM对象,其中d为s的DataGuide
Ts(l)
表示s中l的目标集
Td(l)
表示d中l的目标集
Ls(l)={m|Ts(m)=Ts(l)}
表示s中目标集和
Ts(l)
相同的路径
Ld(l)={m|Td(m)=Td(l)}
表示d中目标集和
Td(l)
相同的路径
我们说一个DataGuides s是一个 Strong DataGuides,当对于s中的每一条路径都符合下面的条件时候:
Ls(l)=Ld(l)
拿上面最右边的DGs做为例子,当l=A,C的时候
Ls(l)={A,C}
,
Ld(l)
={A,C,B,C}所以他并不是Strong的
Einordnung DataGuides(翻译不能,感觉名字和内容没关系)
DataGuides即支持在路径上加入text的索引,同时也可以用于对路径的检查(DataGuides unterstützen sowohl Indexierung von Text für einzelne Pfade als auch das Nachschauen von Pfaden)
前面已经说过了,DataGuide是从一个数据库中总结而来的。但是其实,把DataGuide当作Schema,用于生成数据库也是可行的。(我记得前面否定得很干脆啊)(DataGuide- nachträgliche Zusammenfassung des Datenbestands, DataGuide als Schema, d.h. als apriori Festlegung, wäre auch denkbar.)
另外更加精炼的(akkurater)描述数据库总的来说也是可能做到的(前面明明说的akkurater就不是这个意思啊??)(Noch akkuratere Beschreibung der Datenbank grundsätzlich möglich, z.B. um festzulegen, welche Kombination von Labels von ausgehenden Kanten vorkommen. Geht mit der Syntax von XML-DTDs)
问题:
关系数据库和DataGuides有哪些关联(Welcher Zusammenhand zwischen relationalen Datenbanken einerseits und DataGuides andererseits??)
如何在关系数据库上使用DataGuides(Wie Kann man relationale Datenbank bei der Implementierung von DataGuides verwenden??)
/*老师的观点:
DataGuide selbst entweder im Hauptspeicher oder (gemäß EDGE-Modell) auf Relatioin abbilden
Annotationen als Relation(en)
*/
DataGuide的讨论
- Was ist es?
- Welche Unterschiede gibt es?(ohne/mit Annotationen, unterschiedliche Annotationen; minimaler, strong DataGuide)
- Wie verwenden für das Query Processing??
多层次的情况
关于索引的一些补充
- 可以同时对多个属性进行索引(Index für mehrere Attribute möglich)
- 对(gpa,name)的索引和对(name,gpa)索引是不一样的
- 有多于n!种索引方式
- 索引是属于物理层,而索引的定义则是属于内模式的(Index ist Bestandteil der physischen Ebene. Index-Definition ist Bestandteil des Internen Schemas.)
- 在使用的时候,用户不用自己去找这些索引,DBMS应该实现这类的功能。
另外需要对索引和索引项进行区分(Unterscheidung zwischen Index und Index-Eintrag.Weglassen einzelner Indexeinträge grundsätzlich möglich.)
Subsuming Query 和 Filter Query
Subsuming就是包括的意思。当且仅当
<QS> ⊇ <Q>
<script id="MathJax-Element-67" type="math/tex">
\ \ \ \supseteq\ \ \
</script>时我们说Query
Qs
subsumiert(包括) Q或 Query
QS
是Q的Subsuming Query。
举个例子:
select * from Person where salary > 50.000
包括了(subsumiert)
select * from Person where salary > 100.000
Filter与前面干好相反,就是加约束了。但除此之外还有一个条件(不知是不是必须的)
Q的Filter Query 为
QF
。
QS
为Q的Subsuming Query,那么就有:
<QF>(<QS>)=<Q>
<script id="MathJax-Element-72" type="math/tex">
(
)=
</script>
举个例子:
Q: select * from Person where salary > 50.000 and name=”Boehm”
QS
:select * from Person where salary > 50.000
QF
:select * from QS where name = “Boehm”
那么什么时候把一个Query转换成对应的Filter Query或Subsuming Query才是有意义的呢??
/*为什么总是说Query Evaluation究竟这个Evaluation表达的是什么意思,表示完全不懂啊。
Ein System kann nur Subsuming Query, nicht aber Filter Query evaluieren, und ist sehr schnell.
Ergebnis der Subsuming Query ist relativ klein
*/
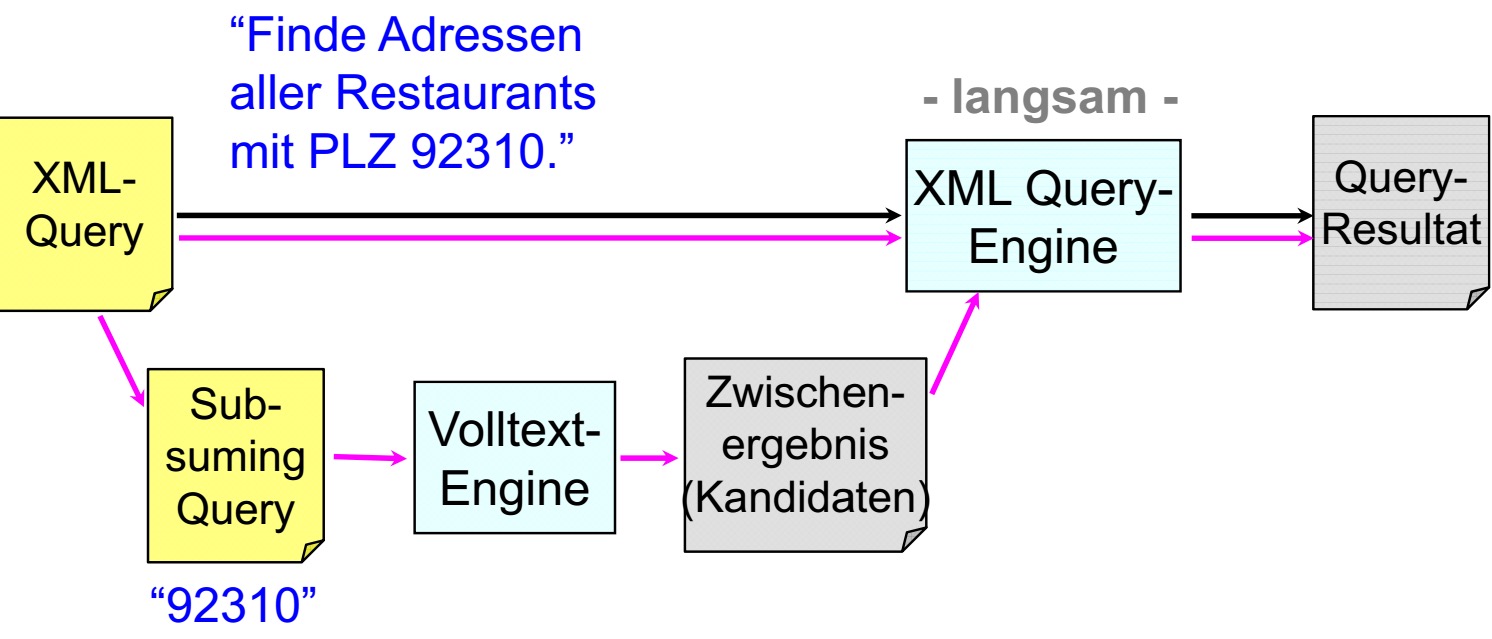
这是Subsuming Query应用的一个例子,他的优势在于
1. Volltext Engine比XML Query Engine要快得多。
2. 候选明显比较下(Zwischenergebnis deutlich keinler als Ausgangskollektion)
Combined Indices
与组合的访问是一样的(如通过
∧
进行组合),组合的索引就是针对组合的属性的索引。组合的可能性很多,他随着属性的数量呈指数级增长。
相对的他的存储空间的需求很多,因此我们经常关心的问题是,能不能删去某个索引项(好了我晕了Index-Eintrag和Indice的区别是什么??)
//好吧,有点清楚了这里的索引项是
组合的数量
进行索引项删除的基础是,我们必须彻底的分清,什么是索引,什么是索引项(Unterscheidung zwischen ‘Index’ und ‘Index-Eintrag’.)
现在假设关系的Schema为:{Name, Vorname, Beruf, Alter, Büro-Nummer}
一般情况下单项索引是有意义的,比如我们的索引项可以是{‘Frodo’}对应所有的名字叫Frodo的数据
组合的情况实在太多,那么应该怎么办呢???
1. 当Vorname ‘Frodo’ 出现的次数很多的时候,那么这个索引项的帮助就显得不大了,因为他同样要进行那么多得遍历。
2. 当Frodo只在数据库中出现一次,那么索引项(‘Frodo’,Beutlin’),(‘Frodo’,25),(‘Frodo’,’301c’)本质上是没有必要的。
3. 假设Vorname ‘Frodo’在数据库中出现n次,同样的Vorname ‘Frodo’和Nachname ‘Beutlin’的组合也出现n次;那么索引项(‘Frodo’,’Beutlin’)可以删去。删去后再搜索(‘Frodo’,’Beutlin’),则不会有对应的(‘Frodo’,’Beutlin’)索引项,这可能有两种解释:或者(‘Frodo’,’Beutlin’)在数据库中不存在,又或者(‘Frodo’,’Beutlin’)出现的次数和Frodo相同。因此我们应该继续检查对应的Frodo,来弄清楚究竟是属于那种情况。(Verursacht aber nur konstante zusätzliche Kosten. Im zweiten Fall: Entsprechende Indexeinträge verwenden)
4. 假设Vorname ‘Fordo’ 在数据库中出现了1000次,然而Frodo和Beutlin的组合在数据库中,只出现了999次。在这种情况下,同样的,我们会直接把(‘Frodo’,’Beutlin’)给删了。与前面类似,当找不到(‘Frodo’,’Beutlin’)的时候,他表示木或他出现的次数几乎和Frodo的一样。继续检查的时候至少要拿两个Tupel。(Mindestens zwei Tupel mit Vorname ‘Forbo’ mit Hilfe des Index holen, Überprüfung, ob Nachname ‘Beutlin’, dann weiter)
4.5. 用q代表4中两者的比例(999/1000),当q越小时代表,1.节省了越多得空间;2.使用Index带来的加速越小(这个有点不懂??)
一般化text和半结构化的数据(Verallgemeinerung für Text und semistrukturierte Daten)
这里使用的技术,最开始,是为了n-Grams而开发的。(估计是指声音识别那个)
目标是:为Text中出现的单词添加索引
同样的操作我们也可以用于半结构数据的路径上(Gleiches Vorgehen möglich für Pfade(im XML-Dokument). Man kann Technik verallgemeinern für Indexierung Pfadfragment-Dokumenttext)














 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









