






本文转载自公众号知识工场,整理自 2017 年 10 月 13 日肖仰华教授在 CIIS2017 中国智能产业高峰论坛上所做的报告。

肖仰华:很高兴有机会跟大家一起分享《基于知识图谱的可解释人工智能:机遇与挑战》。
刚才刘总的报告中提到了机器和人类将来要互相拥抱,互相拥抱的前提是互信,机器要相信我们,我们要相信机器。这个相信指的是,比如机器给我们做一个决策案或者治疗方案,我们能够相信机器给出的结果。当前,机器显然还不能给出合理的解释, AI系统作出的决策仍然缺乏可解释性。正因为可解释性的缺乏,导致人类对机器产生的结果无法采信。可以设想一下,如果我们都不相信机器的行为和决策,那么机器为人类生活提供的服务将大打折扣。所以需要增强人工智能的可信性和可解释性。
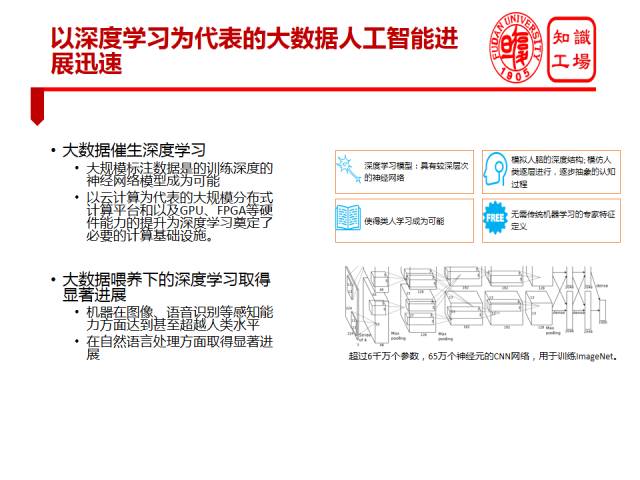
AI的可解释性问题要从深度学习谈起。这几年我们见证了深度学习的一系列突破。深度学习的进展本质上是由大数据喂养出来的。大数据时代,海量高质量的带标注数据,使深度学习模型可以学习到非常有效的层次化特征表示,从而使得深度学习成为可能。以云计算为代表的大规模分布式计算平台以及GPU、FPGA等硬件能力的提升为深度学习提供了必要的计算基础设施。大数据喂养下的深度学习取得了显著进展,机器在图像、语音识别等感知能力方面甚至超越人类。在深度学习的推动下,自然语言处理方面也取得了显著进展。

然而,深度学习的一个广为诟病的问题是其不透明性,不可解释性。深度学习模型是一种端到端的学习,接受大样本作为训练输入,所习得的模型本质上是神经网络结构的参数。其预测过程,是相应参数下的计算过程,比如说输入一张狗的图片,机器做出是否是狗的判断。深度学习的学习和预测过程是不透明的,模型究竟学到了什么有效特征,使得它做出这样一个判断,这个过程缺乏可解释性。深度学习的不透明性问题,有时又被称为深度学习的黑盒(“Black box”)问题,最近受到了广泛关注。《Nature》、《Science》以及《MIT Technology Review》最近都有文章讨论这一问题,都指出深度学习的发展需要打开这个黑盒。乔治亚理工的Mark Riedl认为如果AI系统不能回答Why问题,解释这些系统何以产生特定的结果,这些AI系统就只能束之高阁。

深度学习的黑盒问题吸引了各界人士广泛的研究兴趣,学术界与工业界都在努力打开深度学习或者AI系统的黑盒子。这些工作都可以被视作是可解释人工智能的研究范畴,也就是Explainable AI或者简称为XAI。XAI吸引了很多学术团体和政府的关注,最有代表性的就是David Gunning所领导的美国军方DAPRA可解释AI项目,他们旨在建设一套全新的且具有更好可解释性、以及更易为人所理解的机器学习模型。比如在猫的识别任务中,新模型不仅仅告诉你这是一只猫,而且还告诉你模型是因为观察到了猫所特有的爪子和耳朵等做出这是猫的判断。
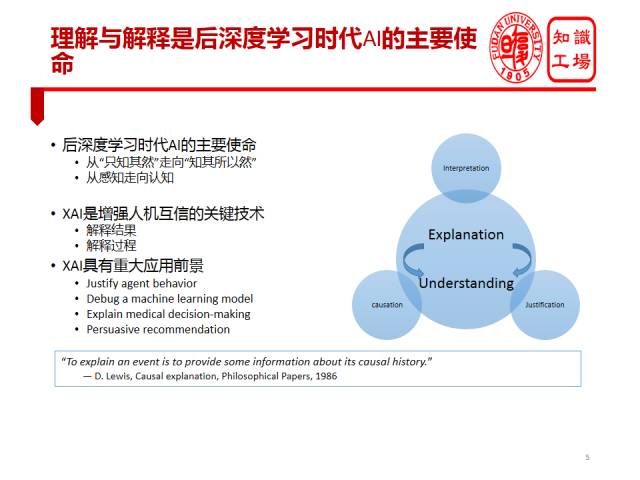
XAI在我看来,不单单是对于解决深度学习可解释性问题具有重要意义,它将在整个AI里都扮演着非常重要的角色。因为,我个人认为理解和解释将来会是整个后深度学习时代人工智能最为核心的使命。在深度学习时代,我们的模型某种程度上只“知其然”而不知其“所以然”。这就好比中医看病,根据以往的经验做诊断。当然,无论是现代中医还是传统中医也都在寻求理论解释,但是仍然很难全面达到西医的解释水平。很显然,我们不可能对只知其然而不知其所以然的AI系统完全采信。所以AI势必要从只“知其然”走向“知其所以然”。我们希望XAI能够解释过程,也能够解释结果。只有能够解释过程和结果,才能使人类信任它。还有很多机器学习模型,我们知道任何模型都不可能100%准确,一定会产生错误,对于产生这些特定错误的原因,我们也在寻求解释。更重要的是,未来我们的AI医生所做的任何治疗方案,都必须配备解释,否则人类不可能为它的诊断买单。在电商以及更多商业场景下,可解释的推荐显得尤为重要,我们相信,将来如果电商不只是给用户推荐一个商品,而且还能告诉用户为什么推荐这个商品,这样的推荐更有说服力。比如说用户去订酒店的时候,可以告诉用户推荐这个酒店的理由,或是离用户会场较近,或是价格便宜。再比如说用户搜索“二段奶粉”,平台可以告诉用户喝此段奶粉的婴儿每天需要饮用多少水,用多大容量的水杯保证每天用水量,从而推荐水杯给用户,如果平台做到有解释的推荐,相信销量肯定会大有提升。
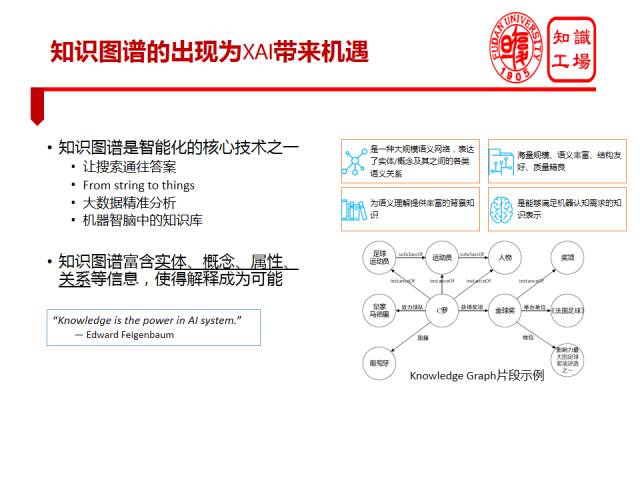
可解释人工智能非常重要,很多人都在尝试解决这一问题,不同的学术团体根据各自的特长在做相应的努力。比如最近刚过学者提出Information Bottleneck的理论,这实质上是信息论的学者,尝试从信息论角度解决这个问题。我本人是从事知识库和知识图谱研究的,所以我的出发点是阐述从知识图谱的角度看XAI有什么机会。我的基本观点是,知识图谱为XAI带来重大机遇。首先要了解知识图谱是什么?刚才也有学者提过,知识图谱是一种语义网络,包含大量实体和概念及其之间的语义关系。相对于传统的知识表示,知识图谱具有海量规模、语义丰富、结构友好、质量精良等优点。知识图谱的这些优点使其成为机器理解语言的重要的背景知识,使机器语言认知成为可能。当前,自然语言“理解”仍是个很遥远的目标,现在只能谈得上是处理。为什么谈不上理解,就是因为没有背景知识。正是在知识图谱的支撑下,机器才能理解搜索关键字,从而实现从搜索直接通往答案,我们才能做到大数据的精准分析,未来我们才可能实现机器智脑。
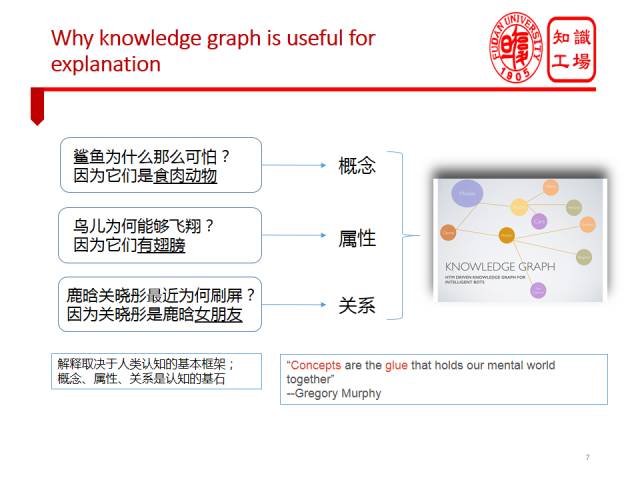
知识图谱对于XAI的重要作用可以套用Edward Feigenbaum的一句话名言来阐述。图灵奖获得者,知识工程创始人Edward Feigenbaum有个观念:“Knowledge is the power in AI system”。我认为Knowledge is thepower in XAI system。知识图谱中所富含的实体、概念、属性、关系等信息,使解释成为可能。比如C罗是一个实体,运动员是他的一个概念,他曾经获得“金球奖”这个奖项,这就是知识图谱的基本构成。为什么知识图谱对可解释AI有帮助?我们先来看一下人是怎么解释的。对于问题,“鲨鱼为什么那么可怕”?人类给出的解释可能是“鲨鱼是食肉动物”,这实质是用概念在解释。而“为什么鸟儿会飞翔?” 人类的解释则可能是“鸟儿有翅膀”,这实质上使用属性在解释。还有最近的热门问题,“为什么鹿晗和关晓彤刷屏了”,因为“关晓彤是鹿晗女朋友”,大家都知道是因为他们公开了恋爱关系,引得鹿晗粉丝一片哗然。这里的解释实质上是用关系在解释。我们或许会进一步追问,为什么人类倾向于用概念、关系和属性做解释?这是因为任何解释都是在认知基本框架下进行的。人类认识世界理解事物的过程,其实就是在用概念、属性和关系去认知世界的过程。概念、属性、关系是理解和认知的基石。

基于上面的认识,我们开始利用知识图谱进行解释的一些探索性研究工作。首先简单介绍一下我们即将用到的两类知识图谱。

一是Probase和Probase+。Probase是一个大规模isA知识库,是从大规模web语料中通过pattern抽取得到的。比如针对“Domestic animals such as cats and dogs”,通过such as模式,可以抽取出Cat is a domesticanimal以及Dog is a domesticanimal这样的isA知识。Probase+是在Probase基础之上,通过补全和纠错,进而得到了一个更大规模的isA知识库。

第二我们将用到的知识库是DBpedia和CN-DBpedia。它们都是关于实体的结构化知识库,比如<复旦大学,位于,上海市杨浦区>这样的三元组事实。CN-DBpedia是DBpedia的中文版本,是由我所在的复旦大学知识工场实验室研发并且维护的。后续我将介绍的解释研究,主要就是基于这两类知识库。
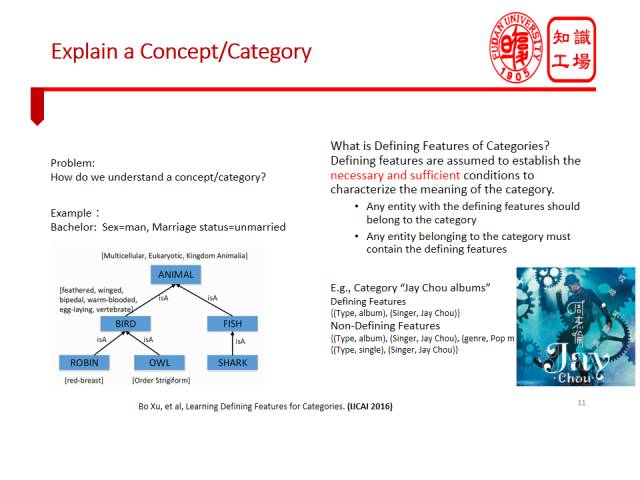
先介绍如何利用Probase/Probase+让机器理解和解释概念。在互联网上有很多新概念(Concept)、新品类(Category)。通常机器仍难以理解或解释这些概念或者类别。比如对于Bachelor(单身汉)这个概念,我们人是怎么解释的呢?我们可能会用一组属性来解释,比如{未婚、男性}。

我们在这个任务中的基本目标就是为每个概念和类别自动产生这样的属性解释。利用DBpedia这样的知识库,为每个概念或类别自动生成一组属性加以解释。最终我们为DBpedia中的6万多个概念自动生成了它们的属性解释。

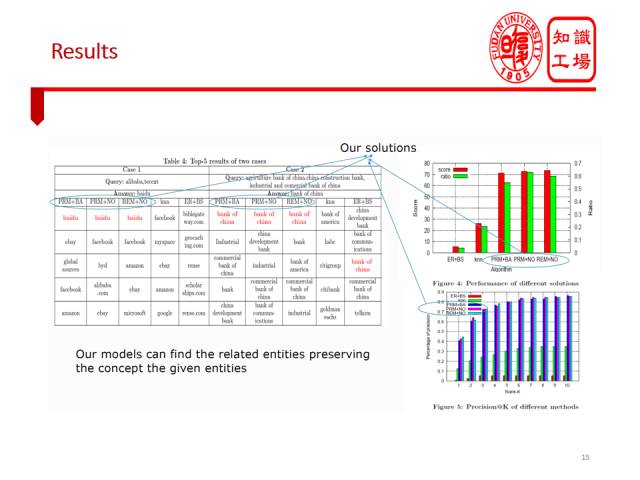
我们紧接着看看如何利用知识图谱让机器理解一组实体,并进而做出推荐。如果我跟你说百度和阿里,你自然会想到腾讯,因为它们俗称BAT,都是中国的互联网巨头,都是IT大公司。假如我们先在亚马逊上搜索iphone8,紧接着搜索三星S8,那么亚马逊应该给我推荐什么呢?最好是推荐华为P10一类的手机。因为根据用户的搜索,我们能够推断出用户大致是在搜索高端智能手机,如果平台推荐一些中低端廉价手机,用户可能就会不满意。

这种推荐是建立在实体理解基础上,我们希望用概念去解释实体,从而准确把握用户搜索意图。通过显式地给出概念,系统可以展示对于搜索实体的理解。比如说搜索阿里和腾讯,系统不仅推荐百度,还可以给出因为它们都是互联网巨头这样的解释。我们利用Probase知识库提供背景知识,提出了一个基于相对熵的模型来产生概念解释以及寻找最佳推荐实体。

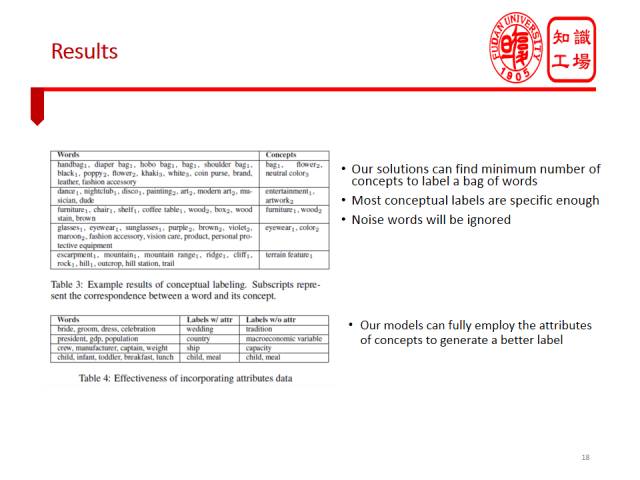
接下来介绍如何利用知识库让机器解释词袋(Bag of words)。在进行文本处理,特别是主题模型时,我们经常碰到词袋。一个主题往往表达为一组词,我们经常困惑于不知道这组词说明了什么。在社交媒体上也大量存在各类词袋,比如Flickr上图片的tag,微博用户的标签等等都是词袋。我们通过一个真实的例子来说明让机器解释词袋的任务,比如一个图片的标签是“新郎”、“新娘”、“婚纱”、“庆典”这些词,很显然我们人对于这组标签的理解是婚礼,我们希望机器也能自动为这组词产生“婚礼”这样的解释。

这里忽略方法细节。我们利用Probase等知识库,提出了一个基于最小描述长度的模型,来为输入词袋产生一组易于理解的概念标签,用以解释这个词袋。

最后一个任务是解释维基百科中的链接实体。我们知道百科数据很重要,百科中每个词条的解释文本中会提及大量相关实体,这些实体通过超链接连接到相应词条。我们的基本任务是能否解释每个百科实体与其链接实体之间的关系。比如在有关SQL的词条中,往往会提到E. F. Codd。事实上E.F.Codd是关系数据库理论的奠基人,是SQL发明的关键人物。我们能否产生一个解释来说明为何E. F. Codd出现在SQL的链接实体中?
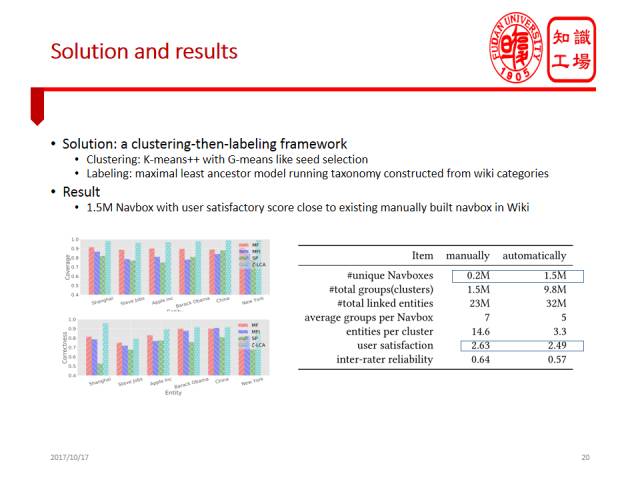
我们将这个问题建模成可解释的聚类问题,我们先将所有链接实体聚类,并自动生成一个概念标签解释每个类,从而解释为何一个链接实体出现在某个特定实体的描述页面中。

虽然我们在基于知识图谱的可解释人工智能方面开展了初步研究,但仍然面临巨大挑战。总体来说,可解释人工智能的路还非常遥远,具体要面临哪些挑战呢?我认为有这几个挑战:一是对于解释和理解的认知仍然很匮乏。我们如果想把解释和理解的能力赋予机器,我们首先要反思自身,理解人是怎么解释现象,人是如何理解世界的。但是,我们在哲学、心理学、认知科学等层面,对于人类的理解和解释的认知十分有限,尤其是对于日常生活中的理解和解释机制更为有限。当前哲学领域理解和解释的研究主要还是聚焦在科学研究过程中的理解和解释,而人类日常生活的理解和解释对于人工智能技术而言则具有更重要的参考意义,对于服务机器人融入人类的生活具有重要意义。但遗憾的是,我们对日常生活中的理解与解释仍知之甚少。
第二个挑战就是,大规模常识的获取及其在XAI中的应用。常识就是大家都知道的知识,比如说人会走、鱼会游等等。我们的解释通常会用到一些常识,当问题涉及到常识的时候,这个问题的解释就会变得非常困难。因为目前对机器而言,常识仍然十分缺乏。常识缺乏的根本原因在于我们很少会提及常识。正因为大家都知道常识,故而没必要提及,以至于语料中也不会显式提及常识。这样一来,所有基于文本抽取的方法就会失效。常识获取仍是当前知识库构建的瓶颈问题。但是常识获取也不是真的一点办法也没有,在大数据的某些角落里,还是会提及常识的。总体而言,常识的获取以及在XAI里怎么用是有很大难度的。
XAI的第三个挑战是数据驱动与知识引导深度融合的新型机器学习模型,或者说是如何将符号化知识有机融入基于数据的统计学习模型中。这不仅是XAI的核心问题,也是当前整个人工智能研究的重大问题之一。要想对于机器学习,特别是深度学习的过程,进行显式解释,我们需要将符号化知识植入到数值化表示的神经网络中去,用符号化知识解释习得深度神经网络的中间表示与最终结果。符号化知识与深度学习模型的有机融合是降低深度学习模型的样本依赖,突破深度学习模型效果的天花板的关键所在。目前这一问题虽然受到了普遍关注,但仍然缺乏有效手段。

总结一下,在这次报告中我想表达的观点包括:一、以深度学习为代表的大数据人工智能获得巨大进展。二、深度学习的不透明性、不可解释性已经成为制约其发展的巨大障碍。三、理解与解释是后深度学习时代AI的核心任务。四、知识图谱为可解释人工智能提供全新机遇。五、“解释”难以定义,常识获取与应用,深度学习和符号主义的融合对XAI提出巨大挑战。
最后把亚里士多德的一句名言“Knowing yourself is the beginning of all wisdom”送给大家。研究可解释人工智能的前提是梳理清晰人类自身的认知机制。认清我们自己,才能将人类的能力赋予机器。我相信重新审视人类自我将是在未来人工智能研究过程中经常遇到的情形。
谢谢大家!
关注“知识工场”微信公众号,回复“20171013”获取下载链接。
以上就是肖仰华教授在CIIS2017 中国智能产业高峰论坛上为大家带来的全部内容。知识工场实验室后续将为大家带来更精彩的文章,请大家关注。

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。














 2612
2612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









