










上一篇博客简单梳理了NLP的技术架构、NLP语言模型的演化,以及最基本的语言模型Bag-of-Word词袋模型及基于词袋模型的重要模型和算法。本文将继续探讨NLP中重要的语言模型N元语言模型,并探究其变形。
根据上文公式1
P(w1w2...wT)=∏ni=1P(w1)P(w2|w1)P(wi|w1w2...wi−1)
,词w出现的在序列位置T的概率取决于序列前面1~T-1所有词,而这样的模型参数空间巨大,训练计算量惊人且数据稀疏。而BOW(unigram)中,每维特征信息量过少。 依据著名马尔科夫假设(Markov Assumption),在N-gram中词T的概率仅仅受前N-1个词影响。N元模型公式
p(S)=p(w1w2...wm)=p(w1)∗p(w2)...∗p(wm|wm−N+1wm−N+2...wm−1)
举个经典的二元语言模型(Bi-gram)例子:
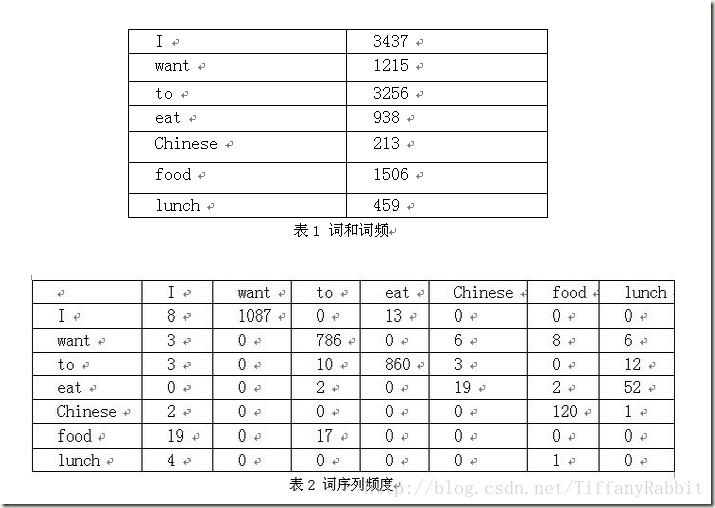
图1: 二元语言模型实例(左为语料库中词频和词序列,右为“I want to eat Chinese food”概率计算过程)

图2:二元LM中句子概率计算
N-gram对中文词性标注(part of speech, POS)、中文分词(Word Segmentation)有很好的效果。中文分词和POS是中文文本分析中非常重要的一环,因此在此作为N-gram的应用简要介绍。此外,基于N-gram还出现了更多有价值的语言模型,如NNLM、CBOW等。
1.中文词性标注 - NGram应用
词性标注(POS tagging)是个典型的多分类问题,将每个词标注为名词、动词、形容词、副词、代词等(可能更细分)。举个例子,在“我/爱/北京”这句中,“爱”有很多词性,比如名词、动词。最简单的标注其语义的方案就是,看语料库中“爱”出现的次数。即
P(POSi|爱)=Count(爱asPOSi)Count(爱);i=1,2...k,k为总词性种类)
。
然而这种极简POS Tagging的方案依赖人工,且尚未考虑上下文。考虑到词性与前一两个词关系较大,因此我们引入N-Gram模型,最简单的比如前文提到的bi-gram模型,即在考虑“爱”的POS时考虑“我”的词性。则当前这个“爱”的词性概率分布为
P(POSi|我,爱)=P(POSi|Pron.,爱)=Count(前面被“副词”修饰的“爱"作为“POSi”)Count(前面被“副词”修饰的“爱");i=1,2,3...
计算这个概率需要对语料库进行统计。但前提是你得先判断好“我”的词性,因为采用2-gram模型,由于“我”已经是第一个词,在二元模型中只需要用极简的方案判断即可。利用NLTK的POS Tagger,可以轻松进行中文词性标注。在下一节分词中将po出代码。
2.中文分词 - NGram应用
中文分词在中文语义分析中有着绝对重要核心的地位。根据从朴素贝叶斯到N-gram语言模型的介绍, 中文分词,重要到某搜索引擎厂有专门的team在集中精力优化这一项工作,重要到能影响双语翻译10%的准确度,能影响某些query下搜索引擎几分之一的广告收入。
对于X = “我爱北京”这样一句话,有N中分词方案,对于
Yi
这种分词方案,如
Y0
=(“我”“爱”“北京”)、
Y1
=(“我”“爱北”“京”)、(“我爱”“北京”)…, 套用贝叶斯公式有:
而无论在哪种 Yi 下,最终都能生成句子X。因此 P(X|Yi) 为1。 P(Yi|S)∝P(Yi),i=1,2,3... 。则只需要最大化 P(Yi) 即可。例如,在bi-gram语言模型中, P(Y0|X)∝P(Y0)=P(我)P(爱|我)P(北京|爱) , P(Y1|X)=P(Y1)=P(我)P(爱北|我)P(京|爱北) 。根据语料库,P(京|爱北)的概率接近0, P(Y0) 较大,则采用这种分词策略。利用python的jieba库可以进行中文分词和词性标注,示例如下。
import jieba
import jieba.posseg
#中文分词
s = '我爱北京'
seg = jieba.cut(s)
for i in seg:
print(i)
#中文词性标注
seg_pos = jieba.posseg.cut(s)
for i in seg_pos:
print(i.word, i.flag)
Output:
我
爱
北京
(u'\u6211', u'r')
(u'\u7231', u'v')
(u'\u5317\u4eac', u'ns')
3.从N-gram到NNLM
对N-gram的训练也产生了其他一些语言模型。著名的神经网络语言模型(NNLM)就是其中的典型代表。说高大上的NNLM是由N-gram演化而来的,这种理解的逻辑依据是——考虑前后文的量。下一篇中会讲到RNNLM及其延伸,其考虑前后文的量理论上将扩展为全文(
∞
)。在此篇我们只考虑固定个(N)上下文的情况。
Bengio《A Neural Probabilistic Language Model》NNLM经典之作,他提出利用三层神经网络构建语言模型。结构如图三。
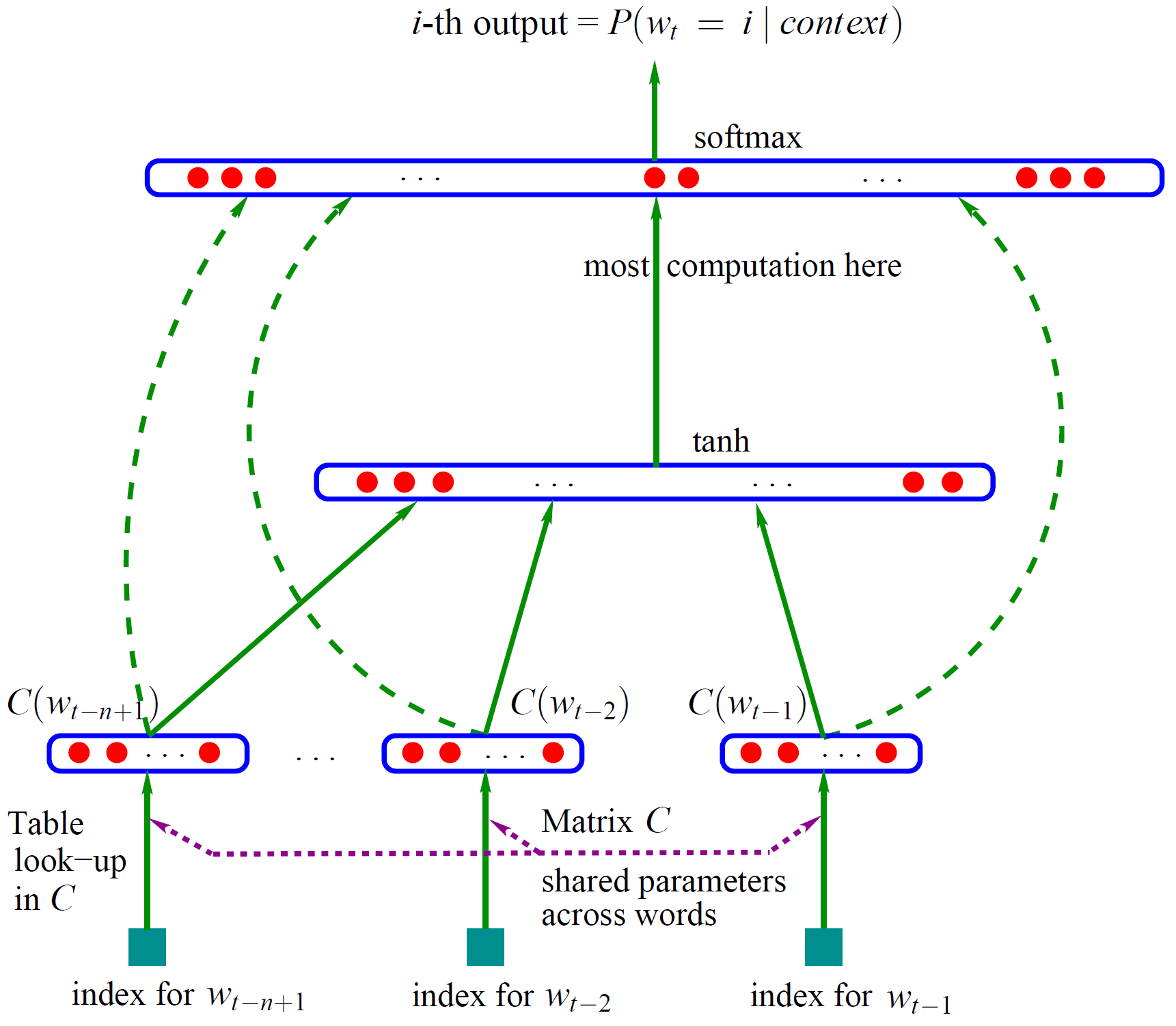
图三:神经网络语言模型 by Bengio
图三中,C(w)为词w对应的词向量,为V*m维矩阵(V为总词数,m为词向量维度)。
神经网络(NN)的输入层为当前词
wt
的前n-1个词
wt−n+1,...,wt−1
各自的词向量(即word embedding)相拼接,合计共
(n−1)m
维。
NN的隐藏层与普通NN无异,以tanh双曲正切函数作为激活函数。
NN的输出层共V个节点,对应每个词作为
wt
的log概率。可通过softmax函数对输出值y进行归一化为概率。
输入层直连输出层注意,存在权重矩阵
WV∗(n−1)m
, 直接关联了输入层与输出层。
故神经网络输出表达式如下:
V中每个词的词向量(word embedding)都存在于权重矩阵C中。故NLPM除了学习Weight和bias,还同时对输入层的词向量进行训练。模型的参数为C, U, H, W, b, d.模型对 wt 的损失函数即为:
通过梯度下降训练参数更新过程如下:
详细更新过程、数学原理及简要实现可以参考这篇《Feedforward Neural Network Language Model(NNLM)原理及数学推导》。NPLM的python实现可以参考yuriyfilonov的NPLM_theono实现或者greninja的实现版本NPLM_tensorflow。
4.CBOW & Skip-gram
在NNLM的基础上,CBOW和Skip-gram可以理解为其两个特殊的变种,区别在于去掉了NPLM的隐藏层,而着重突出了输入层one-hot到word embedding这一步(毕竟,大家听说CBOW&Skip-gram都是从word2vec开始的嘛哈哈,别说你不是,大神受小妹一跪!)。与以上模型相似的是,它们同样考虑前后文,依然逃脱不了N-Gram语言模型的基因。只不过,CBOW通过上下文预测中心词概率,而Skip-gram模型则通过中心词预测上下文的概率。如图所示,模型与大体无异,这里着重介绍CBOW模型。
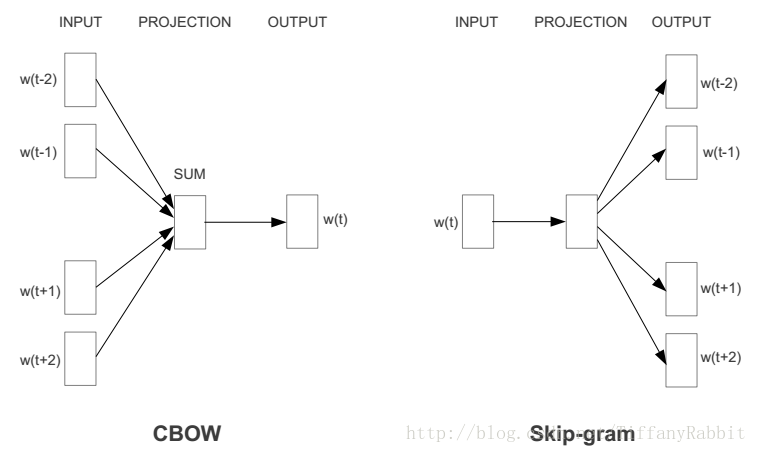
本文介绍的是一个经典且简单的CBOW模型,是来自Google的Tomas Mikolov 2013年论文[3]中的版本。图片推导参考[4]。
下图展示了一个多词上下文(context=multi_words)的CBOW模型。前面提过CBOW模型与NPLM的主要区别再去去掉了隐藏层,而图中提到的Hidden Layer实际并没有涉及任何非线性激活操作(如上文NPLM中的tanh),而仅仅是对输入层通过权重矩阵得到的词向量求平均。因此图中我将其标记成映射层(Projection Layer)。
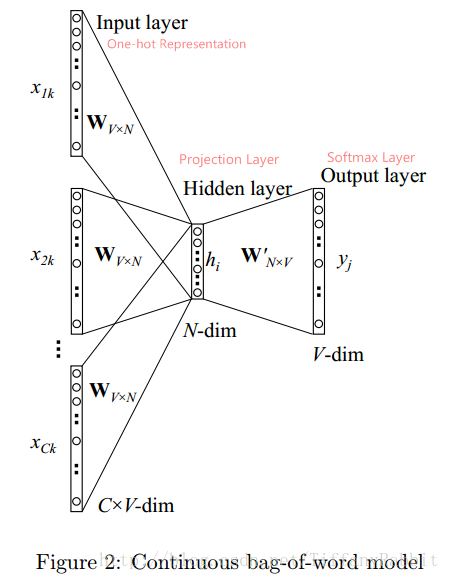
符号定义: 语料库为D,词汇总数V;考虑上下文词语数C个,分别表示为
w1k,w2k,...,wCk
;映射层/词向量维度为N;
xw
为词汇w的One-hot Representation,V维;
vw
为词汇w的词向量,N维。
输入层: 输入层的节点为C个上下文词语的one-hot表示,共C*V输入节点。
映射层: 将输入层节点乘上权重矩阵
WV∗N
得到的词向量(word embedding)求平均得到h。公式如下。
输出层: 映射层经过 W′N∗V(而后即为UN∗V) 权重矩阵后,得到V维z, 再对z进行softmax操作得到中心词为某个词j的概率分布。公式如下。
故该模型对于中心词w_t的损失为:
加和得到模型总损失函数为
故从映射层到输出层的权重更新如下(详细推导参考[4]):
输入层到映射层的权重更新如下:
以上是CBOW模型的结构及简单推导,sam-iitj/CBOW提供了CBOW模型的实现,仅供大家参考学习。
虽然CBOW模型对NPLM模型进行了简化,但由于仍然包含softmax操作而耗时严重。[4]文中给出了层次softmax+负采样的方式对训练进行加速,[5]文对其进行了深化和整理,在此不再展开。
5.副产品Word2vec
不管是NPLM还是CBOW、Skip-gram,除了训练得到语言模型,还得到了副产品词向量,可以将语料库中的词通过权重矩阵得到更make sense且非稀疏的向量表达,同时还能将语义甚至语法通过空间距离的方式进行呈现,比如NLPer们熟知的“king-man+woman=queen”和“queen+kings-king=queens”的例子。这就是的词向量不仅在更多复杂语言模型中发挥作用,还有更多奇妙的应用,比如相似度度量,进而进行文本分类聚类,完成情感分析、关系挖掘等有趣的任务。
Python中的gensim库提供了word2vec的API,可以对词向量进行创建、训练、保存、重训练等操作,并利用其进行相似性度量等。
model = Word2Vec(docs, size=100, window=5, min_count=5, workers=2) #利用sentences构建词向量
model.save(file_path) #将训练好的词向量进行保存
model = Word2Vec.load(file_path) #从文件载入模型,重训练或使用
model.wv['computer'] #查找computer的词向量
output:
array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
model.wv.most_similar(positive=['woman', 'king'], negative=['man']) #利用词向量计算词语间的空间关系
Output:
[('queen', 0.50882536), ...]
model.wv.similarity('woman', 'man') #计算两个词的相似度
Output:
0.73723527附:Word2Vec参数说明
Class gensim.models.word2vec.Word2Vec(sentences=None,size=100,alpha=0.025,window=5, min_count=5, max_vocab_size=None, sample=0.001,seed=1, workers=3,min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=<built-in function hash>,iter=5,null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000)
· sentences:可以是一个list,也可以直接大语料集Wikipedia、Reuter等构建。
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
· window:表示当前词与预测词在一个句子中的最大距离是多少
· alpha: 是学习速率
· seed:用于随机数发生器。与初始化词向量有关。
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
· workers参数控制训练的并行数。
· hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
· negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
· hashfxn: hash函数来初始化权重。默认使用python的hash函数
· iter: 迭代次数,默认为5
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
· sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
· batch_words:每一批的传递给线程的单词的数量,默认为10000本文承接上文的词袋模型,串联了考虑有限个上下文的各类语言模型,以N-Gram模型开始,引出了神经网络语言模型NPLM及其变形CBOW、skip-gram以及副产品word2vec,并介绍了word2vec的应用。在写一篇文章中,将在有限上下文的基础上进一步突破,考虑全文档/Sequence的语言模型。
P.S. 文中若有错误,敬请指出,蟹蟹!
参考
[1] 从朴素贝叶斯到N-GRAM
[2] 概率语言模型及其变形系列
[3] Efficient Estimation of Word Representations in Vector Space
[4] PDF: word2vec Parameter Learning Explained
[5] Word2vec的加速:Hierarchical softmax与Negative Sampling














 27
27











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









