







我们先来看看需要采集的网站:
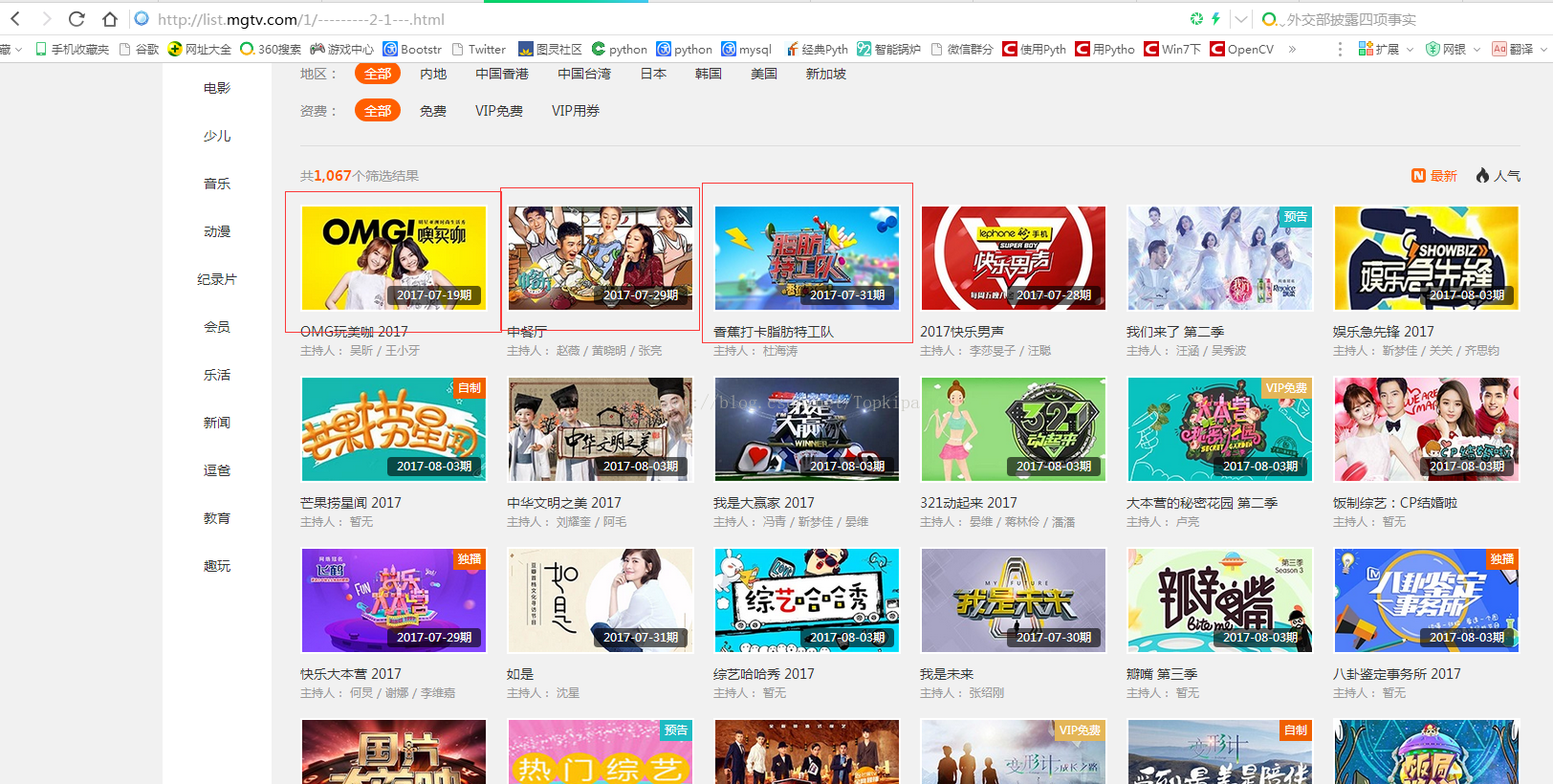
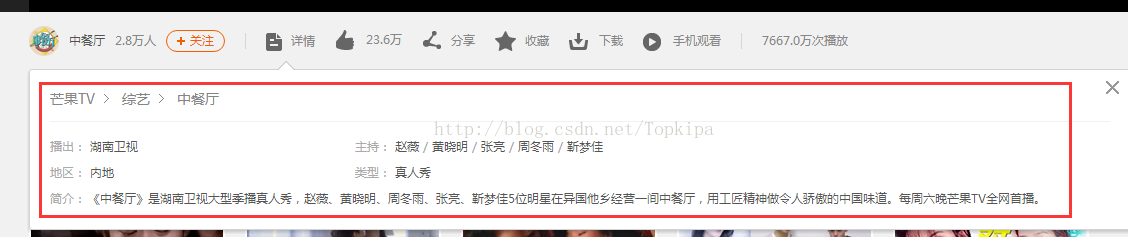
以综艺类搜索页第一页为例子:http://list.mgtv.com/1/---------2-1---.html,其中一页有60部综艺信息
信息:
教程:
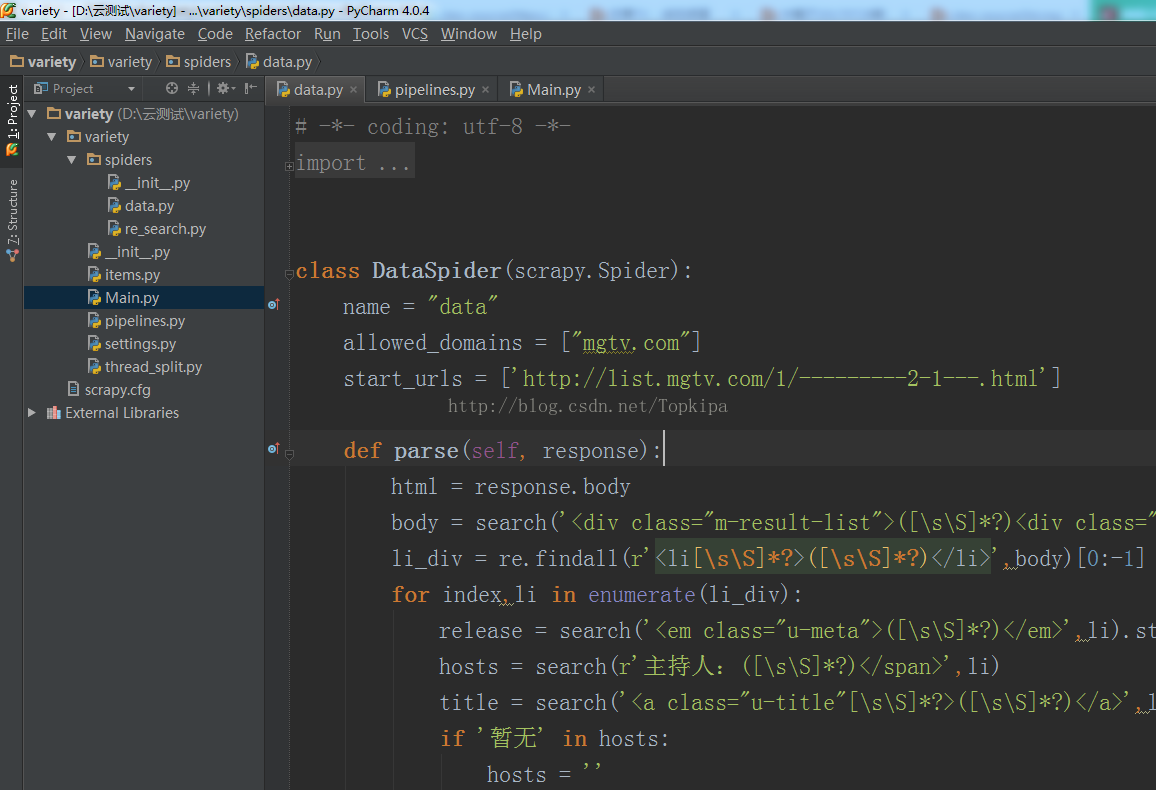
创建工程:具体方法前面教程都有,创建完了之后,整体大概如下图:
data.py为主
我们先来看看需要采集的网站:
以综艺类搜索页第一页为例子:http://list.mgtv.com/1/---------2-1---.html,其中一页有60部综艺信息
信息:
教程:
创建工程:具体方法前面教程都有,创建完了之后,整体大概如下图:
data.py为主
 713
3473
4298
713
3473
4298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















