







一、一个方法引发的奇葩现象
在实际工作中,我们经常会遇到读取文本或网络中的内容,但是由于编码格式的不统一,往往得到的结果总是一团乱码,这就需要将文本按照它原本保存的编码解析成正确的内容。下面这段代码使用了字节按照指定字符编码获取字符串,可能很多人也使用过它,其实呢这段代码是错误的,如果读取的内容很多的话,会发现只有个别的字符乱码,而大部分的字符都能正确显示。
private String inputStreamToString(InputStream is, String encoding) {
try {
byte[] b = new byte[1024];
String res = "";
if (is == null) {
return "";
}
int bytesRead = 0;
while (true) {
bytesRead = is.read(b, 0, 1024); // return final read bytes counts
if (bytesRead == -1) {// end of InputStream
return res;
}
res += new String(b, 0, bytesRead, encoding); // convert to string using bytes
}
} catch (Exception e) {
e.printStackTrace();
System.out.print("Exception: " + e);
return "";
}
}
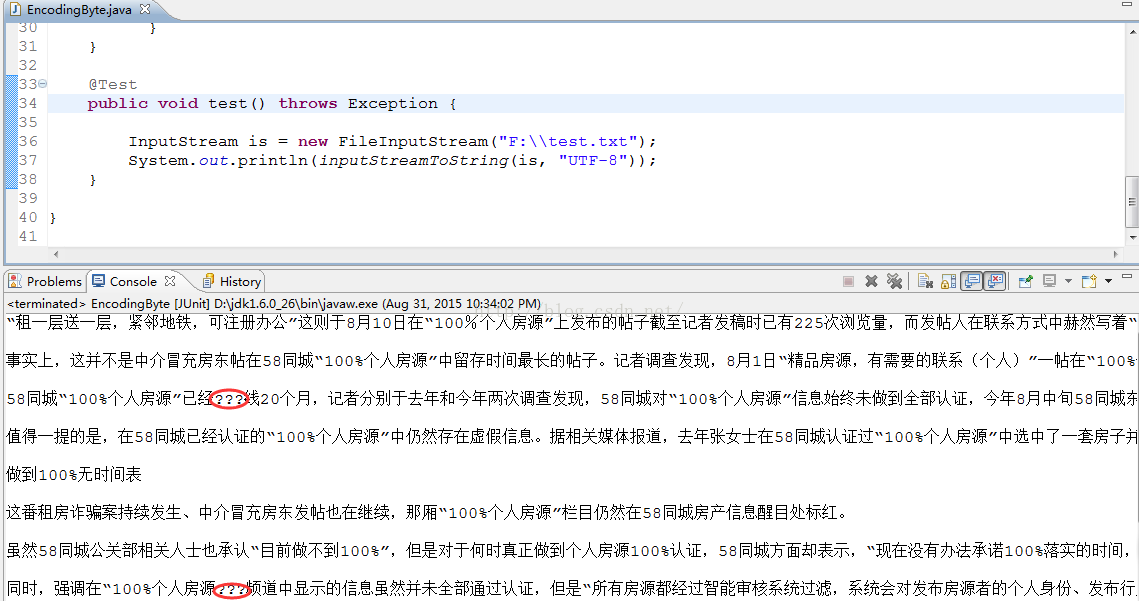
之所以会出现如此奇葩的现象,是因为这个方法没有正确理解字符编码和字节的关系。
二、字符编码和字节的关系
世界上存在着很多编码,比如ASCII码,unicode编码等。ASCII码只能表示英文字符和其他诸如空格等特殊字符,占用八位二进制位,最前面以为统一设为0,后面的7位根据ASCII码表对应表示128个字符;而unicode编码的野心最大,它理论上包含了世界上所有的字符,它和ASCII一样,设置了字符的对应位置编号,比如1表示A,2表示B,10001表示“好”(这里只是打个比方,并不是真实的编码与字符对应),但是这样编号计算机是看不懂的,计算机只知道用二进制位来表示字符,但是我们不可能只简单的用二进制表示字符,比如用1表示A,用10表示B...,计算机无法知道10表示是一个整体还是1和0的组合,所以需要设计让计算机能读懂的unicode编码,担当此重任的就包括UTF8、UTF16和UTF32等。
UTF-8是一种变长的编码方式,字节长度从1到4不等;UTF-16要么是2个字节,那么是4个字节;UTF-32使用4个字节。(具体编码原理点击阮一峰的博客)
三、奇葩现象的大揭秘
开篇的方法将字节流(InputStream是以字节为单位的输入流)以1024个字节为单位按照UTF-8编码为字符串的,最后将所有的字符串拼接起来。而UTF-8是变长的字节编码方式,编码成一个字符需要1至4个不等的字节,1024个字节想要编码成正确的字符时,可能会多出字节或缺少字节,往往导致1024字节中的最后几个字节无法正常识别成为乱码(字符和编码的对应关系根据编码方式的不同,采取了标志位和编号对应等算法得出正确字符,否则就会乱码,具体原理请看 阮一峰的博客)。
要想使用1024个字节读取字节流而永不乱码,只能是读取使用UTF-32编码的字节流,因为UTF-32使用了4个字节编码,恰好1024是4的倍数,所以编码时所有的字节都能正确的被编码成字符。
四、如何远离奇葩现象
既然无法像开篇方法中使用固定长度字节编码字符串再拼接的方式,那么只能取得字节流中的全部字节,再将全部字节编码成字符串,才不会导致编码时多出字节和缺少字节的情况,请看下面的正确方法。
private static String inputStreamToString(InputStream is, String encoding) throws IOException{
int count = is.available(); // 字节流的字节数
/** 由于InputStream.read(byte[] b)方法并不能一次性读取太多字节,所以需要判断是否已读取完毕 **/
byte[] b = new byte[count]; //
int readCount = 0; // 已经成功读取的字节的个数
while (readCount < count) {
readCount += is.read(b, readCount, count - readCount);
}
return new String(b, 0, count, encoding);
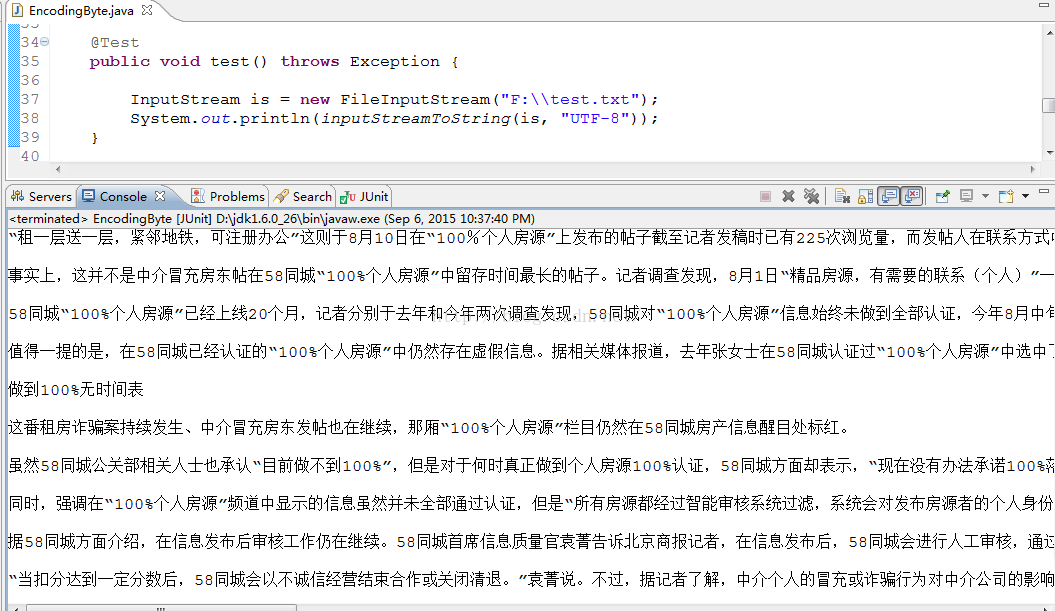
}测试编码结果正常
👉👉👉 自己搭建的租房网站:全网租房助手,m.kuairent.com,每天新增 500+房源














 6001
6001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









