






hadoop_MapReduce处理topKey程序
实例1
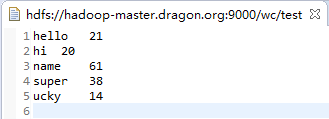
输入文本:
需求分析:得出此文本中单词数的最大值,仅输出一行,如:name 61
代码分析:本实例中,只用到了一个map并没有用到reduce,因为输入文件只有一个,所以没有必要再写一个reduce(稍后会列出,多个输入文件,reduce处理)
代码如下:
package com.ucky.topkMapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class topkMapreduce { /** * @author UCKY.Kit * 因为输入文件为一个文件所有已个map任务执行即可,不再需要Reduce处理 * 输入的文件,为已经被WordConut技术过的文本 */ static class Map extends Mapper<LongWritable, Text, Text, LongWritable> { private LongWritable mapOutputValue = new LongWritable(); private Text mapOutputKey = new Text(); //记录最大值并赋初始值 private long num = Long.MIN_VALUE; @Override public void setup( Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { super.setup(context); } @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //获取VALUE String strValue = value.toString(); //切割 String strs[] = strValue.split("\t"); long temp = Long.valueOf(strs[1]); //比较最大值并记录 if (num < temp) { num = temp; mapOutputKey.set(strs[0]); } } @Override public void cleanup(Context context) throws IOException, InterruptedException { //设置输出VALUE mapOutputValue.set(num); context.write(mapOutputKey, mapOutputValue); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, topkMapreduce.class.getSimpleName()); job.setJarByClass(topkMapreduce.class); job.setMapperClass(Map.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); //将REDUCE数设置为0,默认为1 job.setNumReduceTasks(0); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }<strong> </strong>
实例2
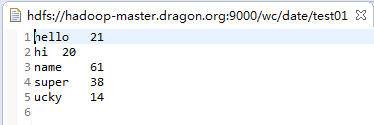
输入文本:
需求分析:得出此文本中单词数的最大值,仅输出最大数的前3行
代码分析:本实例中,只用到了一个map并没有用到reduce,因为输入文件只有一个,所以没有必要再写一个reduce(稍后会列出,多个输入文件,reduce处理)
代码如下:
package com.ucky.topkMapreduce; import java.io.IOException; import java.util.TreeSet; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class topkMapreduce2 { static class Map extends Mapper<LongWritable, Text, NullWritable, LongWritable> { public static final int KEY = 3; private LongWritable mapOutputValue = new LongWritable(); private Text mapOutputKey = new Text(); private long num = Long.MIN_VALUE; private TreeSet<Long> topSet = new TreeSet<Long>(); @Override public void setup( Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context) throws IOException, InterruptedException { super.setup(context); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // get value String strValue = value.toString(); // split String strs[] = strValue.split("\t"); long temp = Long.valueOf(strs[1]); topSet.add(temp); if (KEY < topSet.size()) { topSet.remove(topSet.first()); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { for(Long l :topSet){ mapOutputValue.set(l); context.write(NullWritable.get(), mapOutputValue); } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, topkMapreduce2.class.getSimpleName()); job.setJarByClass(topkMapreduce2.class); job.setMapperClass(Map.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); job.setNumReduceTasks(0); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
实例3
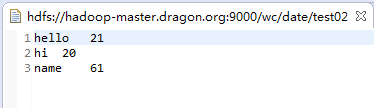
输入文本:
需求分析:得出此文本中单词数的最大值,仅输出最大数的前3行(优化)
代码分析:本实例中,只用到了一个map并没有用到reduce,因为输入文件只有一个,所以没有必要再写一个reduce(稍后会列出,多个输入文件,reduce处理)
代码如下:
自定义数据类型TopWritable
package com.ucky.topkMapreduce; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class TopWritable implements WritableComparable<TopWritable> { private String word; private Long num; public TopWritable(){} public TopWritable(String word,long num){ set(word, num); } public String getWord() { return word; } public void set(String word, long num) { this.word = word; this.num = num; } public Long getNum() { return num; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(word); out.writeLong(num); } @Override public void readFields(DataInput in) throws IOException { this.word = in.readUTF(); this.num = in.readLong(); } @Override public int compareTo(TopWritable o) { int cmp = this.word.compareTo(o.getWord()); if(0!=cmp){//不同 return cmp; } return this.num.compareTo(o.getNum()); } @Override public String toString() { return word + "\t" + num; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((num == null) ? 0 : num.hashCode()); result = prime * result + ((word == null) ? 0 : word.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; TopWritable other = (TopWritable) obj; if (num == null) { if (other.num != null) return false; } else if (!num.equals(other.num)) return false; if (word == null) { if (other.word != null) return false; } else if (!word.equals(other.word)) return false; return true; } }
topkMapreduce3:
package com.ucky.topkMapreduce; import java.io.IOException; import java.util.Comparator; import java.util.TreeSet; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class topkMapreduce3 { static class Map extends Mapper<LongWritable, Text, Text, LongWritable> { public static final int KEY = 3; private long num = Long.MIN_VALUE; private TreeSet<TopWritable> topSet = new TreeSet<TopWritable>( new Comparator<TopWritable>() { @Override public int compare(TopWritable o1, TopWritable o2) { return o1.getNum().compareTo(o2.getNum()); } }); @Override public void setup( Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { super.setup(context); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // get value String strValue = value.toString(); // split String strs[] = strValue.split("\t"); long temp = Long.valueOf(strs[1]); topSet.add(new TopWritable(strs[0], temp)); if (KEY < topSet.size()) { topSet.remove(topSet.first()); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { for (TopWritable l : topSet) { context.write(new Text(l.getWord()),new LongWritable(l.getNum())); } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, topkMapreduce3.class.getSimpleName()); job.setJarByClass(topkMapreduce3.class); job.setMapperClass(Map.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); job.setNumReduceTasks(0); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
实例4
输入文本:
需求分析:得出此文本中单词数的最大值,仅输出最大数的前3行
代码分析:本实例中,为多个文件输入,一个map处理不过来,需要reduce来处理,看完代码,会发现,实际上map就是一个分割字符串传递的工作,前几个例子中,map处理topKey的工作被转移到了,reduce上去做了(自定义数据类型在上面不在此处贴出相应代码)
代码如下:
package com.ucky.topkMapreduce; import java.io.IOException; import java.util.Comparator; import java.util.TreeSet; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class topkMapreduce4 { static class Map extends Mapper<LongWritable, Text, Text, LongWritable> { private Text mapKey = new Text(); private LongWritable mapValue = new LongWritable(); @Override public void setup( Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { super.setup(context); } @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // get value String strValue = value.toString(); // split String strs[] = strValue.split("\t"); mapKey.set(strs[0]); mapValue.set(Long.valueOf(strs[1])); context.write(mapKey, mapValue); } @Override public void cleanup(Context context) throws IOException, InterruptedException { super.cleanup(context); } } static class Reduce extends Reducer<Text, LongWritable, Text, LongWritable> { public static final int KEY = 3; private TreeSet<TopWritable> topSet = new TreeSet<TopWritable>( new Comparator<TopWritable>() { @Override public int compare(TopWritable o1, TopWritable o2) { return o1.getNum().compareTo(o2.getNum()); } }); @Override public void setup( Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { super.setup(context); } @Override public void reduce(Text key, Iterable<LongWritable> value, Context context) throws IOException, InterruptedException { long count = 0L; for (LongWritable t : value) { count += t.get(); } topSet.add(new TopWritable(key.toString(), count)); if (KEY < topSet.size()) { topSet.remove(topSet.first()); } } @Override public void cleanup(Context context) throws IOException, InterruptedException { for (TopWritable l : topSet) { context.write(new Text(l.getWord()), new LongWritable(l.getNum())); } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, topkMapreduce4.class.getSimpleName()); job.setJarByClass(topkMapreduce4.class); job.setMapperClass(Map.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }














 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









