






百度最近发表的一篇论文提出使用生成对抗网络(GAN)目标来实现鲁棒的语音识别系统,作者表示新框架不依赖信号处理中经常需要的领域专业知识或简化假设,直接鼓励以数据驱动的方式产生鲁棒性。更多细节内容,请查看论文原文。
自动语音识别(ASR)支持的语音助手、智能音箱等逐渐成为我们日常生活的一部分,例如 Siri、Google Now、Cortana、Amazon Echo、Google Home、Apple HomePod、微软 Invoke、百度 Duer 等等。虽然最近的一些研究突破极大地改进了 ASR 技术,但这些模对混响、环境噪声、口音等人类无障碍就能识别合理变化,都有着相当大的性能衰减。
这些问题中的大部分都可通过在大量数据上进行训练来减轻。但是,在流程不稳定的情况下,例如口音、精确的数据增强不行的情况下,收集高质量的数据集会非常费时、昂贵。以往 ASR 相关文献都有着细致的手动工程前端-后端和数据驱动方法,从而尝试提升质量差的数据价值。虽然这些技术在各自的环境中相当有效,但在实际中因为前面提到的原因,泛化到其他形态时并不好。也就是,从基本原则上,很难在混响与背景噪声下建模。已有的技术没有直接诱导出 ASR 的变体或者不可扩展。同时,也因为语音的时序特性,同一文本的两种不同发音需要对比校准。
本论文中,研究者使用生成对抗网络(GAN)框架,以可扩展、端到端的方式提高序列到序列模型的鲁棒性。编码器组件作为 GAN 的生成器,训练以输出噪声音频样本和干净音频样本之间不可分辨的嵌入。由于没有限制假设,这种新型鲁棒训练方法理论上能够在没有对齐或复杂的推断流程,甚至没有增强的情况下提高鲁棒性。研究者还使用编码器距离目标函数进行实验,以明确限制嵌入空间,展示了获取隐藏表征级别的不变性是鲁棒性自动语音识别有前途的方向。
论文:ROBUST SPEECH RECOGNITION USING GENERATIVE ADVERSARIAL NETWORKS

论文链接:https://arxiv.org/abs/1711.01567
本论文描述了一个通用、可扩展且端到端的框架,使用生成对抗网络(GAN)目标来实现鲁棒的语音识别。编码器经过经过将噪声音频映射到与干净音频相同的嵌入空间的学习方法训练后提升了不变性。与此前的方法不同,新的框架不依赖信号处理中经常需要的领域专业知识或简化假设,直接鼓励以数据驱动的方式产生鲁棒性。我们通过实验展示了新方法可以在 vanilla 序列-序列模型中提升远场语音识别性能,而无需专门的前端或预处理过程。
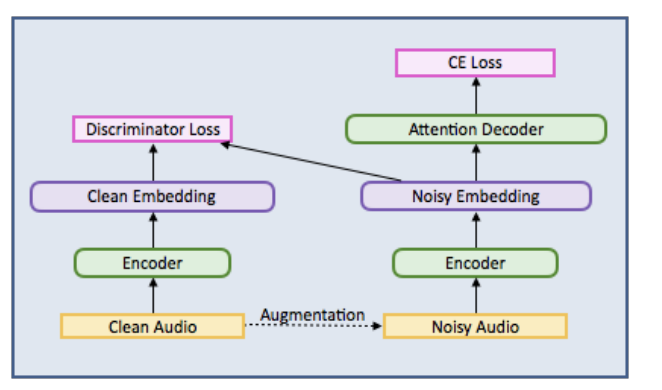
表 1. 百度论文中增强器模型(enhancer model)的架构。其中,鉴别器的损失可以是 L1-distance 或 WGAN 损失。整个模型使用鉴别器损失和交叉熵损失进行端到端训练。研究人员使用 RIR 卷积来模拟远场音频。我们也可以使用不同条件下记录的相同语音来训练这个模型。

算法 1. WGAN 增强训练。在百度的实验里,序列到序列模型在训练中使用了 Adam 优化器。如果 x 可以生成 x tilde,序列到序列模型就也可以使用数据增强。

表 1. 编码器架构

表 2. 评论的架构(特征)×(次数)

表 3. 语音识别系统在华尔街日报语料库上的表现















 66
66











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









