







今天下午闲来无事,索性打开LeetCode继续打怪升级。没想到却整整耗费了2个小时在这道题上面。题目如下:
-------------------------------------------------------------我是题目描述开始标记-------------------------------------------------------------------
Given a string, find the length of the longest substring without repeating characters.
Examples:
Given "abcabcbb", the answer is "abc", which the length is 3.
Given "bbbbb", the answer is "b", with the length of 1.
Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer must be a substring,
"pwke" is a subsequence and not a substring.
是字符串处理问题。对于字符串的操作处理向来是各大公司面试考察的常客。
拿到题目后,第一反应想到的就是直接暴力破解法,具体思考过程为:
1、如何判断当前字符是否在前面的字符串中?
想到了使用vector来保存前面无重复字符的字符串,然后通过使用find函数来判断当前字符是否在vector中来判断字符是否重复。
2、若发现有重复字符之后,该如何处理呢?
当发现当前字符在前面的字符串子串中出现过,则以前面与当前字符相同的字符的下一位作为字符串起始,对新的字符串做与之前相同的操作。因此,此处采用递归对字符串进行处理。对于所要获得的长度,则通过将当前获得的无重复字符的字符串长度,同递归返回的作为参数传入的子串的最大不重复子串长度进行比较,取其中较大者。
具体的实现代码如下:
int lengthOfLongestSubstring(std::string s) {
if(s == "")
{
return 0;
}
else if(s.size() == 1)
{
return 1;
}
int max_len = 0;
std::vector<char> without_repeating_substr;
without_repeating_substr.push_back(s[0]);
int current_max = 1;
std::vector<char>::iterator iter;
for (int i = 1; i < s.size(); ++i)
{
iter = find(without_repeating_substr.begin(), without_repeating_substr.end(), s[i]);
if (iter != without_repeating_substr.end())
{
max_len = lengthOfLongestSubstring(s.substr(i));
break;
}
without_repeating_substr.push_back(s[i]);
current_max += 1;
}
if (current_max > max_len)
{
max_len = current_max;
}
return max_len;
}将上述代码提交LeetCode,结果在运行到第982个测试用例,即最后一个测试用例时,会报出Time Limit Exceeded的错误,于是乎,不得不重新思考程序执行效率及时间复杂度的问题。
既然要解决时间问题,首先就要分析下上面程序的执行效率问题到底出现在哪里。显然,递归调用是影响效率的第一大原因,另外,find操作因为涉及到频繁的遍历,所以也会对程序的执行效率有所影响。因此,要从这两方面入手,去解决执行效率问题。
找到了问题所在,就要开始解决问题了。
1、find函数是用来确定当前字符是否与前面子串中的字符重复的,要舍弃find函数,找到一个效率更高的处理方法,我首先想到了hash表。此处可以使用hash表来记录字符在字符串中出现的索引位置。当后面遇到相同的字符,在向hash表中插入时,会引发冲突,以此来对字符重复做判断。
2、递归调用则是用于在发现重复字符后,对后面的子串进行处理的。其实我们完全可以舍去递归操作,具体处理方法为
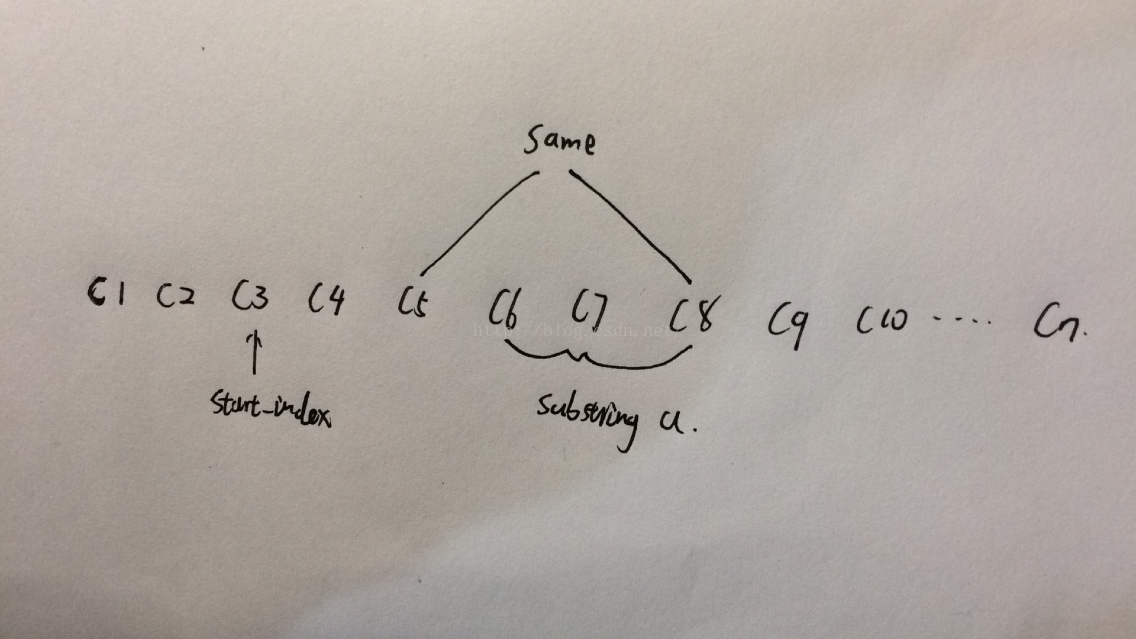
使用一个变量start_index来记录当前检测的子串的起始索引,结合上面的hash表处理方式,会有下面两种情况:
1)、当发现有重复字符时,重复字符在hash表中记录的索引位置在start_index之前,也就是说,该重复的字符已不在我们所要检测的字符子串的范围内,此时我们只需要将该字符在hash表中所记录的索引位置更新为当前该字符的索引位置即可;
2)、当发现有重复字符时,重复字符在hash表中记录的索引位置在start_index之后,也就是说,该重复的字符在我们所要检测的字符子串的范围内,如上图中,字符C5和C8相同,但从C5的后一个字符,即C6,到当前字符C8是无重复字符的,所以,此时我们只需要在start_index中记录hash表中重复字符索引的下一个元素的索引,然后继续刚才遍历到的位置,继续遍历即可,结合上图就是,在start_index中记录C6的索引,然后接着从C9继续向后遍历即可。
有了上面的想法,具体处理代码如下:
int lengthOfLongestSubstring(string s) {
if(s == "")
{
return 0;
}
else if (s.size() == 1)
{
return 1;
}
int max_len = 0;
int hash_table[256];
memset(hash_table, -1, sizeof(hash_table));
int current_max = 0;
int start_index = 0;
for (int i = 0; i < s.size(); ++i)
{
if (hash_table[s[i]] == -1)
{
current_max += 1;
hash_table[s[i]] = i;
}
else
{
if (start_index <= hash_table[s[i]])
{
start_index = hash_table[s[i]] + 1;
if (max_len < current_max)
{
max_len = current_max;
}
current_max = i - hash_table[s[i]];
hash_table[s[i]] = i;
}
else
{
current_max += 1;
hash_table[s[i]] = i;
}
}
}
if (current_max > max_len)
{
max_len = current_max;
}
return max_len;
}上面程序的时间复杂度为O(N),提交到LeetCode,果然通过了。
经验教训:若程序对处理效率有所要求,千万要避免频繁使用递归调用。切记切记。














 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









