Deep Forest 优点
1. 性能高度接近深度神经网络
2. gcForest 的参数数量较少,训练更简单,森林层次自适应
3. 训练速度更快
4. gcForest能在小数据集上表现良好
5. 树结构在理论上更容易分析和理解
Deep Learning 缺点
1. 需要更大的训练数据才能有更好的结果
2. DNN结构复杂,需要的计算量大(为了要利用大的训练数据,学习模型需要更大的容量,会更复杂)
3. DNN有大量参数,且训练性能严重依赖于 hyper parametor 的微调
Deep Forest 结构
说明:本文中插图全部来自原论文 ”Deep Forest: Towards An Alternative to Deep Neural Network”
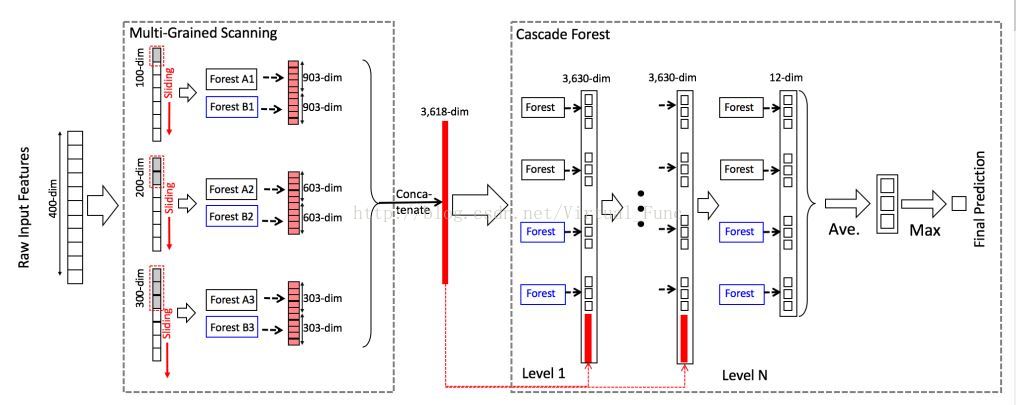
Deep Forest 的结构分为两个大部分,其中
第一个部分是Multi-Grained Scanning,作用类似于卷积神经网络,即将多个相邻特征进行分组处理,考虑了特征之间的相互关系,示例中将一个400维的特征扩展到了3618维。
第二个部分是Cascade Forest
,这部分是算法的核心,通过将若干个弱分类器(决策树)集成得到的森林再次集成,形成森林瀑布的层次,每一层中都由四个森林组成,最终结果层是取森林瀑布顶层的四个森林结果的均值作为最终判定结果。
Cascade Forest 整体算法如下:
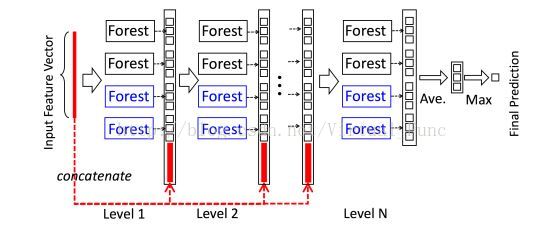
1. Deep Forest 是由多层森林组成的瀑布型结构,每一层的输入是前一层森林输出的特征信息,且该层森林的输出作为下一层森林的输入特征的一部分
2. 瀑布是由多个森林串成的,而森林又是由多棵决策树集成的。为了保证模型的多样性,采用了多种不同种类的森林
3. 为了简单起见,文中在每层中只选用了两种森林:two complete random forests 与 two random forests。即每层只有四个森林
4. complete random forest 是由1000棵 complete random trees 组成的,complete random tree 中每个节点都随机的选择一个特征作为分裂特征,不断增长整棵树,直到剩余所有样本属于同一类,或样本数量少于10
5. random forest 是由1000棵 random trees 组成的, random tree 中的每个节点都随机的选择 sqrt(d) 个特征(其中d是输入特征总数),然后选择最佳基尼系数的特征作为该节点的分裂特征,同样增长整棵树,直到剩余所有样本属于同一类或样本数量少于 10
输出过程分析:
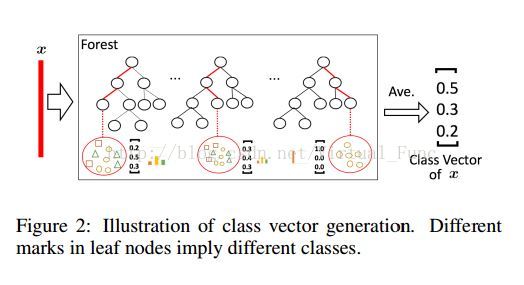
森林对每个输入样本都有一个输出,该输出是以类别占比的形式给出的,如上图中,此时存在三个类别(方形,三角形,椭圆形),森林中每棵树的叶子节点记录了建立该决策树时,落在该叶子节点中的样本集合中各个类别的样本所占的比例,如第一棵树中给出的叶子节点的例子,落在该节点上的一共有9个样本,其中有2个方块样本,4个椭圆样本,和3个三角形样本。因此该叶子节点记录的 class vector 为 [ 0.2, 0.5, 0.3]。
一个样例 x 进入森林中,在第一棵树中按决策树规则走,最后落在的叶子的 class vector 为[0.2, 0.5, 0.3],在第二棵树中得到的 class vector 为 [0.3, 0.4, 0.3], 在第三棵树中得到的 class vector 为 [1.0, 0 , 0 ],所以最终整个森林得到的 class vector 为各棵树上得到的 class vector 的平均值,即【0.5,0.3,0.2】。
四个森林得到的结果串联起来,同时原始输入的特征也串联在这四棵树的特征后,将这些特征传入下一层
在瀑布层次后,用一个总的验证集衡量瀑布的性能,不断增加瀑布的层次,直到验证集上的性能不再提升,这也是文中说的自适应的森林层次的实现方式。
注意:为了避免过拟合,每个森林中 class vector 的产生采用了 k 折交叉验证的方法,具体来说,假设样本有 k 个, 观察针对第k个样本的class vector 的生成, 先把第一个样本扔出训练集,用剩下的 k - 1 个样本训练整个森林(其中包含第k个样本),此时得到的森林对第k个样本输出一个 class vector。然后将第二个样本扔出训练集,用剩下的 k - 1个样本训练森林,此时得到的森林对第 k 个样本仍然输出一个 class vector,。。。依次,每个样本被用作训练集中样本的数量为(k - 1)次,产生 k - 1 个 class vector,取这些 class vector 的平均值作为该森林对该样本最终输出的 class vector。(这个部分 我还没理解透!!!!)
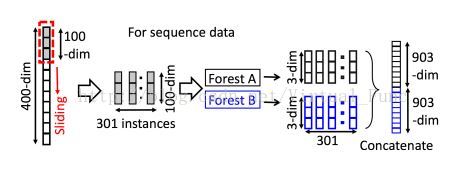
Multi-Grained Scanning 算法说明:
如上图所示,其中假设原始输入样本的特征维度为400维,通过定义一个大小为100的滑动窗口,将滑动窗口从原始输入特征上滑过,每次移动一个特征大小,每次窗口滑动获取的100个特征作为一个新的实例,等效于在400维特征上每相邻100维的特征摘出来作为一个特征实例,得到301个新的特征实例(400 - 300 + 1),每个特征实例的维度为100维。同理,假设窗口大小为200,则400维的特征将得到201个特征新实例。
注意:这里的301个特征实例是属于同一个样本的多维特征生成的,属于同一个样本,而不是通常理解的实例即样本的概念。
得到301个 100维的特征实例后,将其通过两个随机森林A与B,分别是complete random forest 和 random forest,由之前对这两个森林的描述可知,每个森林对每个输入样例将输出一个 class vector(假设此时分类任务为分为3类,则此时每个class vector 大小为3)。因此301个特征实例通过一个森林后将生成301个class vector, 每个 class vector 的大小为3。将两个森林生成的各个特征实例的class vector 级联起来,得到的总特征数量为(301 * 3 * 2)1806个特征。
注意:每个样本对应的label 就是该样本对应的301个特征样本的 label。 同时输入m 个样本,这m个样本映射为301 * m 个特征样本输入此时的 Forest A 与 Forest B,构建了各个树,并得到各个样本对应的高维映射结果。
该算法通过这样的思路,将同一个样本的特征之间按照相邻关系分组,分组后输入随机森林,将特征映射到更高维度,其中原始特征之间的关系构成了 其中一部分新的特征。将映射后的高维特征输入森林瀑布中,继续完成整个流程。
整体流程:
分析一下整个流程图,输入是一个样本原始的400维特征,通过设置三个不同大小的滑动窗口,100维的滑动窗口得到 301 个特征实例(维度为100), 200维的滑动窗口得到201个特征实例,300维的滑动窗口得到101个特征实例,每个特征实例通过一个森林后映射为1个维度为3的 class vector,因此301个特征实例经过两个 forest 后得到的特征维度为:301 *3(class vector) * 2(2个森林)=1806。201个特征实例经过两个 forest 后得到的特征维度为:201 * 3 * 2 = 1206。101个特征实例对应维度为 606,最终将所有特征集成起来,每个样本得到的总特征数为:1806 + 1206 + 606 = 3618。
将3618作为森林瀑布的输入,除了第一层森林外的各层森林的输入为:森林的输出结果(4*3)+原始特征(3818)=3830个特征。最后一层森林的结果取均值后取其中占比最大的类作为该样本的预测结果。
论文转载,请标明出处:http://blog.csdn.net/virtual_func/article/details/60466788






















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









