






信息熵理论及应用
1948年美国数学家香农(shanonc.E)为解决信息的度量问题提出了信息熵的概念。信息熵是信息论中用来刻画信息无需度的一个量,熵值越大,表示信息的无序化程度越高,相对应的信息效率越高
计算过程
- 建立体系的数学模型,假设X为已知矩阵,其中Xij表示第i个评价对象的第j个指标,构建矩阵。
- 对矩阵消除量纲并做归一化处理得到矩阵Y,其中的矩阵Y中的任何一个值都在[0,1]内;
- 计算每个参数的熵值;
- 利用熵值计算每个参数的权重值。
模型特点
假设针对评价指标已经建立了合理的权重矩阵P,则Pj表示第j个评价指标的权重。显然Pj的和为1且pj>=0。
为确定权重矩阵P,我们应该构建一个计算矩阵Y的函数H,H的相关性质如下:
- 对称性:H(x1,x2)=H(x2,x1)。当评价对象次序改变的时候,对同一评价指标的权重不变。即计算矩阵Y的任意两行发生变化时,函数的值保持不变。
- 单调性:函数要求单调递增
- 连续性:
- 可加性
基于以上原则,我们构建出的函数:
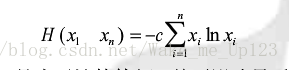
这里的c为归一化因子,对数的底取e是为了计算方便,并不影响后续的计算结果,唯一问题是H(x1,x2)位单调减函数与习惯不符,因此在计算后期必须计算离差进行修整。
信息熵的计算过程
- 首先对数据矩阵X做归一化处理得到计算矩阵Y,
其中分母中的第一个、第二个分别表示数据矩阵X第j列的最大值、最小值,分母中的第二个参数为矩阵的平均值。
权重的熵值并不是为了为了评价某个指标的实际熵值(信息量)大小,而是体现对应评价在给定评价体系中的作用,反映评价指标的相对重要性。从信息论的角度来看,它代表该问题中有用信息的多寡程度,因此对数据矩阵X处理的方式并不会减少数据本身携带信息量的多少。因此我们可以根据要评价的问题来定义如上图所示的归一化公式。 - 计算熵值。如计算第j个指标的熵值为:
这里取负号是因为要保证熵值为正,归一化系数定义为 - 计算评价指标权重
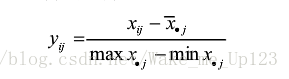
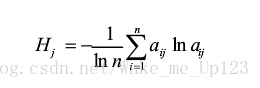
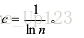
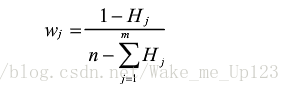














 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









