摘要
本文介绍MySQL的InnoDB索引相对底层原理相关知识,涉及到B+Tree索引和Hash索引,但本文主要介绍B+Tree索引,其中包括聚簇索引(InnoDB)和非聚簇索引(MyIASM),InnoDB数据页结构详解,B+Tree索引的使用以及优化,同时还有B+Tree索引的查询流程简介。
此文是我对学习InnoDB索引的一个总结,内容主要参考MySQL技术内幕 InnoDB存储引擎一书,及网上一些博客(参考文献会给出)
先看看几种树形结构:
1 搜索二叉树:每个节点有两个子节点,数据量的增大必然导致高度的快速增加,显然这个不适合作为大量数据存储的基础结构。
2 B树:一棵m阶B树是一棵平衡的m路搜索树。最重要的性质是每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m - 1;一个节点的子节点数量会比关键字个数多1,这样关键字就变成了子节点的分割标志。一般会在图示中把关键字画到子节点中间,非常形象,也容易和后面的B+树区分。由于数据同时存在于叶子节点和非叶子结点中,无法简单完成按顺序遍历B树中的关键字,必须用中序遍历的方法。
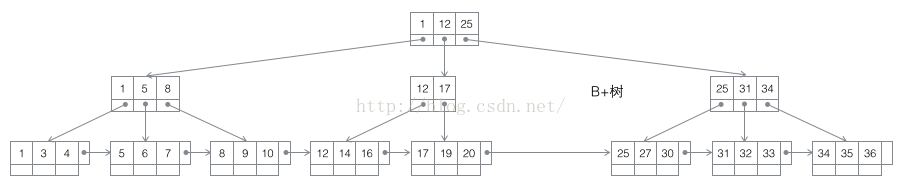
3 B+树:一棵m阶B树是一棵平衡的m路搜索树。最重要的性质是每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m;子树的个数最多可以与关键字一样多。非叶节点存储的是子树里最小的关键字。同时数据节点只存在于叶子节点中,且叶子节点间增加了横向的指针,这样顺序遍历所有数据将变得非常容易。
![]()
一、先从B+Tree入手
B+树的特性
因作者文笔有限,B+树的定义如果在这里重复列出的话,应该只会让大家更困惑,同时相信任何一本数据结构书中都能找到其复杂的定义。但是为了便于读者理解接下来的内容,下面只是简单的介绍一下B+树的几个本文中会用到的特性。
B+树是为磁盘或其他直接存取辅助设备而设计的一种平衡查找树(如果不知道平衡查找树,请自行google),在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶节点中,各叶节点指针进行连接。
下图是在网上找的一张B+树示意图
二、InnoDB数据页结构
1.页介绍
页是InnoDB存储引擎管理数据库的最小磁盘单位。
页类型为B-Tree node的页,存放的即是表中行的实际数据了。
InnoDB中的页大小为16KB,且不可以更改
InnoDB可以将一条记录中的某些数据存储在真正的数据页面之外,即作为行溢出数据。MySQL的varchar数据类型可以存放65535个字节,但
实际只能存储65532个
。同时InnoDB是B+树结构的,因此
每个页中至少应该有两个行记录
,否则失去了B+树的意义,变成了链表,所以一行记录
最大长度的阈值是8098
,如果大于这个值就会将其存到溢出行中。
2.InnoDB数据页组成部分
File Header(文件头)
Page Header(页头)
Infimun + Supremum Records
User Records(用户记录,即行记录)
Free Space(空闲空间)
Page Directory(页目录)
File Trailer(文件结尾信息)
这也是我摘抄的书上的内容,下面我只介绍一下会帮助理解底层原理的部分。
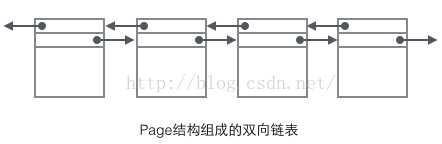
1.在File header中,FIL+PAGE_PREV,FIL_PAGE_NEXT两个表示当前页的上一页和下一页,由此可以看出
叶子节点是双向链表串起来的
。如下图
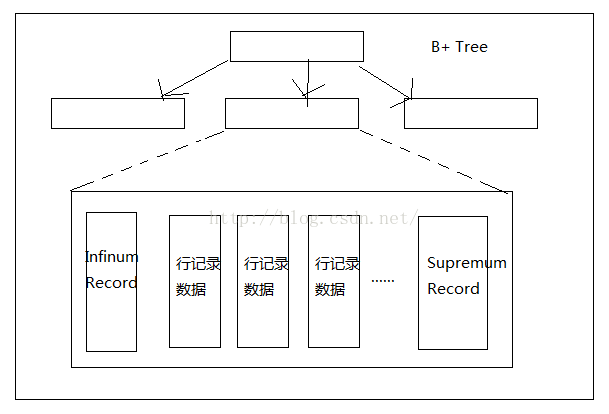
2.Infimum和Supremum记录
在InnoDB存储引擎中,每个数据页中有两个虚拟的行记录,用来限定记录的边界。Infimum记录是比该页中任何主键值都要小的值,Supremum指比任何可能大的值还要大的值。这两个值在页创建时被建立,并且在任何情况下不会被删除。
由上图可以看出,行记录是记录在页中的,同时是在页内行记录之间也是双向链表链接的(在网上有看到说是单链表的)
3.Page Directory
页目录中存放了记录的相对位置,有些时候这些记录指针称为Slots(槽)或者目录槽,与其他数据库不同的是,
InnoDB并不是每个记录拥有一个槽
,InnoDB中的槽是一个稀疏目录,即一个槽中可能属于多个记录,最少属于4个目录,最多属于8个目录。槽中记录按照键顺序存放,这样可以利用二叉查找迅速找到记录的指针。
但是由于InnoDB中的Slots是稀疏目录,二叉查找的结果只是一个粗略的结果
,所以InnoDB必须通过recorder header中的next_record来继续查找相关记录。同时slots很好的解释了recorder header中的n_owned值的含义,即还有多少记录需要查找,因为这些记录并不包括在slots中。
三、查询B+树索引的流程
首先通过B+树索引找到叶节点,再找到对应的数据页,然后将数据页加载到内存中,通过二分查找Page Directory中的槽,查找出一个粗略的目录,然后根据槽的指针指向链表中的行记录,之后在链表中依次查找。
需要注意的地方是,
B+树索引不能找到具体的一条记录
,而是只能找到对应的页。
把页从磁盘装入到内存中
,再通过
Page Directory进行二分查找
,同时此
二分查找也可能找不到具体的行记录
(有可能会找到),只是能找到一个接近的链表中的点,再从此点开始遍历链表进行查找。
四、聚簇索引与非聚簇索引
B+树索引可以分为聚集索引和辅助索引,他们不同点是,聚集索引的行数据和主键B+树存储在一起,辅助索引只存储辅助键和主键。
1.聚集索引
聚集索引是按每张表的主键构造的一颗B+树,并且叶节点中存放着整张表的行记录数据,因此也让聚集索引的节点成为数据页,这个特性决定了索引组织表中数据也是索引的一部分。由于实际的数据页只能按照一颗B+树进行排序,所以每张表只能拥有一个聚集索引。查询优化器非常倾向于采用聚集索引,因为其直接存储行数据,所以主键的排序查询和范围查找速度非常快。
不是物理上的连续,而是逻辑上的,不过在刚开始时数据是顺序插入的所以是物理上的连续,随着数据增删,物理上不再连续。
2.辅助索引
辅助索引页级别不包含行的全部数据。叶节点除了包含键值以外,每个叶级别中的索引行中还包含了一个书签,该书签用来告诉InnoDB哪里可以找到与索引相对应的行数据。其中存的就是聚集索引的键。
辅助索引的存在并不影响数据在聚集索引的结构组织。InnoDB会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后通过主键索引找到一个完整的行记录。当然如果只是需要辅助索引的值和主键索引的值,那么只需要查找辅助索引就可以查询出索要的数据,就不用再去查主键索引了。
补充内容: Mysql的存储引擎和索引
可以说数据库必须有索引,没有索引则检索过程变成了顺序查找,O(n)的时间复杂度几乎是不能忍受的。我们非常容易想象出一个只有单关键字组成的表如何使用B+树进行索引,只要将关键字存储到树的节点即可。当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。有两种常见的方法可以解决多个B+树访问同一套表数据的问题,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index)。这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式。对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树。对于非聚簇索引存储来说,主键B+树在叶子节点存储指向真正数据行的指针,而非主键。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。


我们重点关注聚簇索引,看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
五、索引的管理
索引在创建或者删除时,MySQL会先创建一个新的临时表,然后把数据导入临时表,删除原表,再把临时表更名为原表名称。
但是在InnoDB Plugin版本开始,支持快速创建索引。其原理是先在InnoDB上加一个s锁,在创建过程中不需要建表,所以速度会很快。创建过程中由于加了s锁,所以只能进行读操作,不能写操作。
show index form table;是查看表中索引的信息的。
Table:索引所在的表名
Non_unique:非唯一的索引,可以看到primary key 是0,因为必须是唯一的
Key_name:索引名称
Seq_in_index:索引中该列的位置
Column_name:索引的列
Collation:列以什么方式存储在索引中。可以是A或者NULL,B+树索引总是A,即排序的。
Cardinality:表示索引中唯一值的数目的估计值。如果非常小,那么需要考虑是否还需要建立这个索引了。优化器也会根据这个值来判断是否使用这个索引。
Sub_part:是否是列的部分被索引。100表示只索引列的前100个字符。
Packed:关键字如果被压缩。
Null:是否索引的列含有NULL值。
Index_type:索引的类型。InnoDB只支持B+树索引,所以显示BTREE
六、Hash索引
InnoDB中自适应哈希索引使用的是散列表的数据结构,并且DBA无法干预。
其实这一部分的原理,非常简单,在此就不做过多介绍了
总结






















 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









