







这篇博客是一个链接多个MapReduce作业的小案例,接下来就来看看具体是怎么是怎么实现的:
首先,本次的小案例操作了两个数据文件,分别是:
input1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c目标操作实现结果:
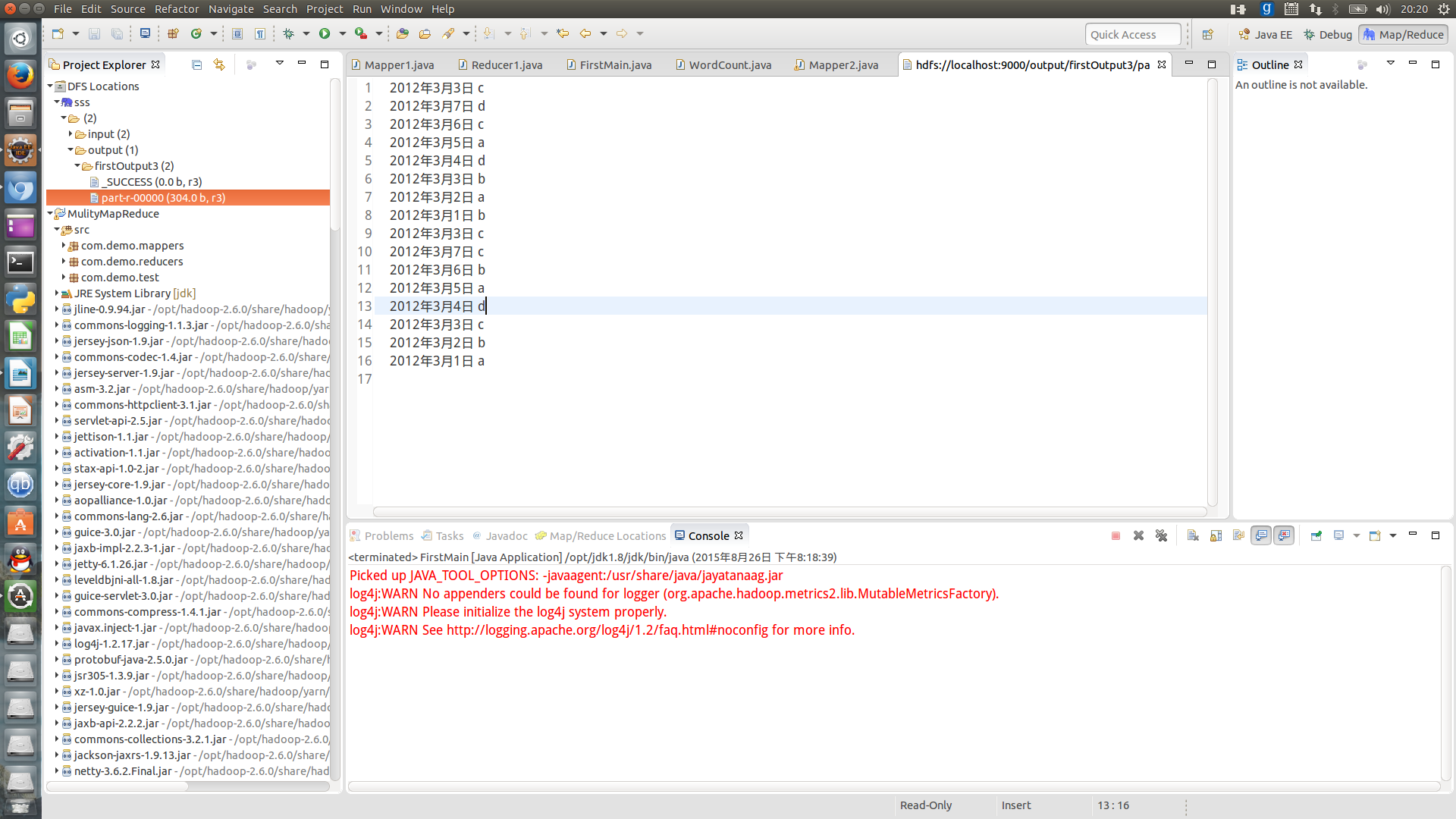
2012年3月3日 c
2012年3月7日 c
2012年3月6日 b
2012年3月5日 a
2012年3月4日 d
2012年3月3日 c
2012年3月2日 b
2012年3月1日 a
2012年3月3日 c
2012年3月7日 d
2012年3月6日 c
2012年3月5日 a
2012年3月4日 d
2012年3月3日 b
2012年3月2日 a
2012年3月1日 b
Mapper1类:
package com.demo.mappers;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Mapper1 extends Mapper<Object,Text,Text,Text> {
//map将输入中的value复制到输出数据的key上,并直接输出
public void map(Text key,Text value,Context context)
throws IOException,InterruptedException{
context.write(value, new Text(""));
}
}
Mapper2类:
package com.demo.mappers;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
public class Mapper2 extends Mapper<Object,Text,Text,Text> {
public void map(Text key,Text value,Context context)
throws IOException,InterruptedException{
context.write(key, new Text(value.toString().split(" ")[0]));
}
}
package com.demo.reducers;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Reducer1 extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
for(Text value : values){
String[] s = value.toString().split("-");
StringBuffer disStr = new StringBuffer();
disStr.append(s[0]).append("年").append(s[1]).append("月").append(s[2].split(" ")[0]).append("日").append(" "+s[2].split(" ")[1]);
context.write(key, new Text(disStr.toString()));
}
}
}
程序入口:
package com.demo.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.chain.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.demo.mappers.Mapper1;
import com.demo.mappers.Mapper2;
import com.demo.reducers.Reducer1;
public class FirstMain {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "MyJob");
job.setJarByClass(FirstMain.class);
//设置Map和Reduce处理链
JobConf mapper1Conf = new JobConf(false);
ChainMapper.addMapper(job, Mapper1.class, LongWritable.class, Text.class, Text.class, Text.class, mapper1Conf);
JobConf mapper2Conf = new JobConf(false);
ChainMapper.addMapper(job, Mapper2.class, Text.class, Text.class, Text.class, Text.class, mapper2Conf);
JobConf reduceConf = new JobConf(false);
ChainReducer.setReducer(job, Reducer1.class, LongWritable.class, Text.class, Text.class, Text.class, reduceConf);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/input/input*"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/output/firstOutput3"));
System.exit(job.waitForCompletion(true) ? 1 : 0);
} catch (Exception e) {
e.printStackTrace();
}
}
}运行结果:














 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









