







「近年来,百度贴吧已经成为一些同学生活中必不可少的一部分,利用空闲时间刷刷贴吧、看看帖子也成为一些人的日常。同学们经常会遇到这样一个问题,有一个图片帖,帖子中有大量自己喜欢的图片(如http://tieba.baidu.com/p/3242594565),于是便想把图图片保存到自己的电脑上以便以后之需,可是由于一个帖子中的图片实在太多(多达几百张),逐张保存非常耗费时间和精力,这时大家就希望有一种简单的方法,能一键把一个帖子中所有的代码保存到电脑上。鉴于此种需求,本帖应运而生」
需要用到的工具:一台装有Python3集成开发环境的电脑,目标帖子(在这里以http://tieba.baidu.com/p/3242594565为例)。
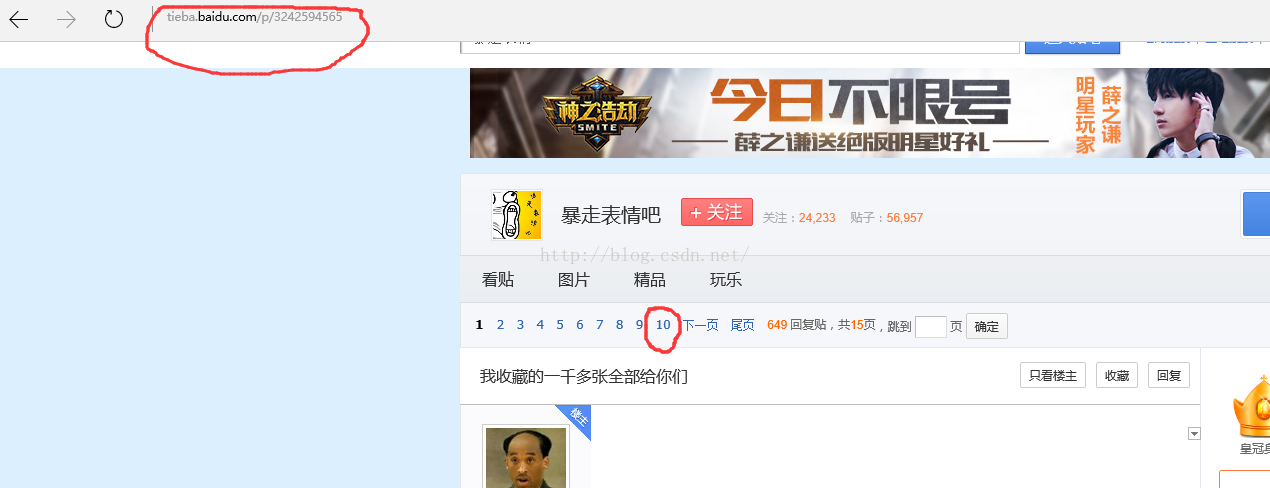
首先,打开你要抓取的网址,如图,获取两个信息,1.此帖子的URL。2.此帖子的页数。
第二,建一个用于保存图片和代码的文件夹,在文件夹下建立一个名为“pic”的子文件夹和一个名为Crawler.py的Python文件,并将以下模板复制到其中。
import re
import urllib.request
# ------ 获取网页源代码的方法 ---
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# ------ 获取帖子内所有图片地址的方法 ------
def getImg(html):
# ------ 利用正则表达式匹配网页内容找到图片地址 ------
reg = r'src="([.*\S]*\.jpg)" pic_ext' #----- 对照网页源代码匹配正则-----
imgre = re.compile(reg);
imglist = re.findall(imgre, html)
return imglist
imgName = 0
pageNum = 1
while 1:
# ------ 帖子的网址 (需要修改)------
html = getHtml("http://tieba.baidu.com/p/3242594565?pn=%d" % pageNum)
# ------ 修改html对象内的字符编码为UTF-8 ------
html = html.decode('UTF-8')
imgList = getImg(html)
for imgPath in imgList:
# ------ 下载与保存 ------
print("正在下载第%d张" % imgName)
f = open("pic/"+str(imgName)+".jpg", 'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
pageNum+=1
if pageNum>10: #确定帖子的页数
break
print("All Done!!!!!!!!!")将模板的 html变量中的URL帖子号修改为目标贴的帖子号(3242594565),将倒数第四行PageNum后的数字修改为帖子的页数。
接下来,是最重要的部分,打开刚才的帖子,按F12查看网页源代码,如下图。
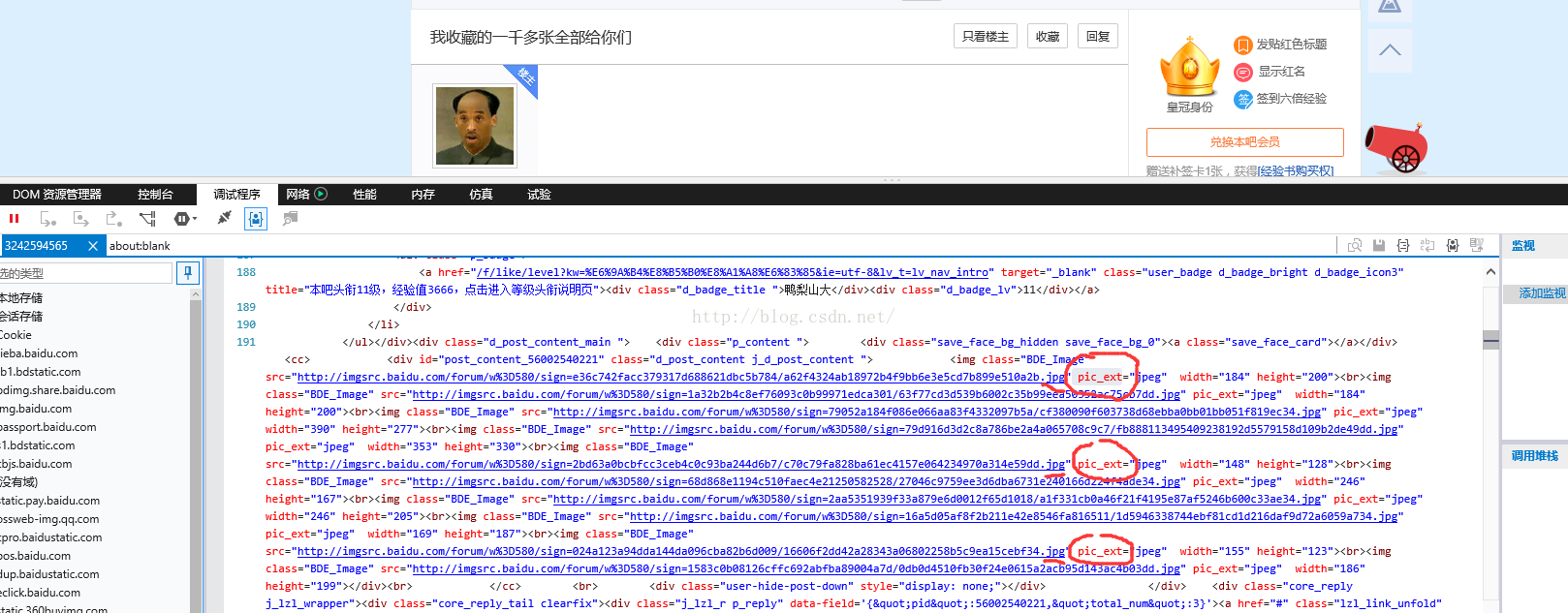
滑动鼠标滚轮,在网页源代码中寻找以.jpg结尾的网址,如图所示,可以发现,每一个以.jpg结尾的URL后,都会有一个固定的单词 “pic_ext”(不同的帖子该单词也不同,需视情况而定),然后,将python文件第13行的pic_ext替换为你的目标贴的该单词。(会使用正则表达式的同学可以看出来,这一步的目的就是利用正则表达式匹配出帖子中所有图片的URL)
至此,代码的编写工作已经完成,用PythonIDE打开此文件,按F5运行,会看到以下界面。
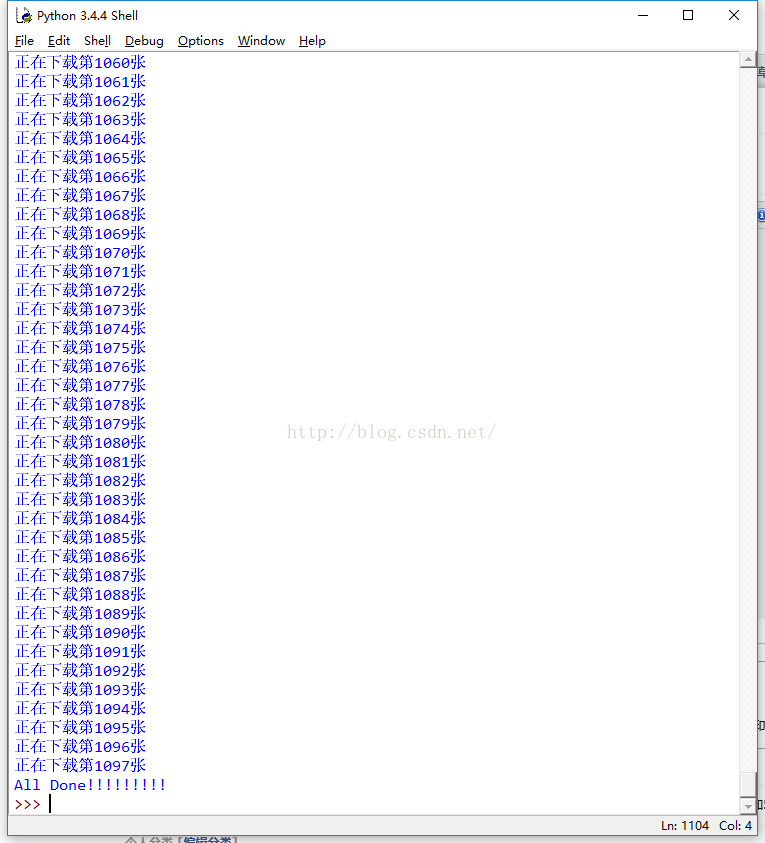
等到显示 All Done!!!!!!!时,抓取工作就全部完成了。很开心有木有?!!!!
下面,让我们打开pic文件夹,来看看我们的成果。
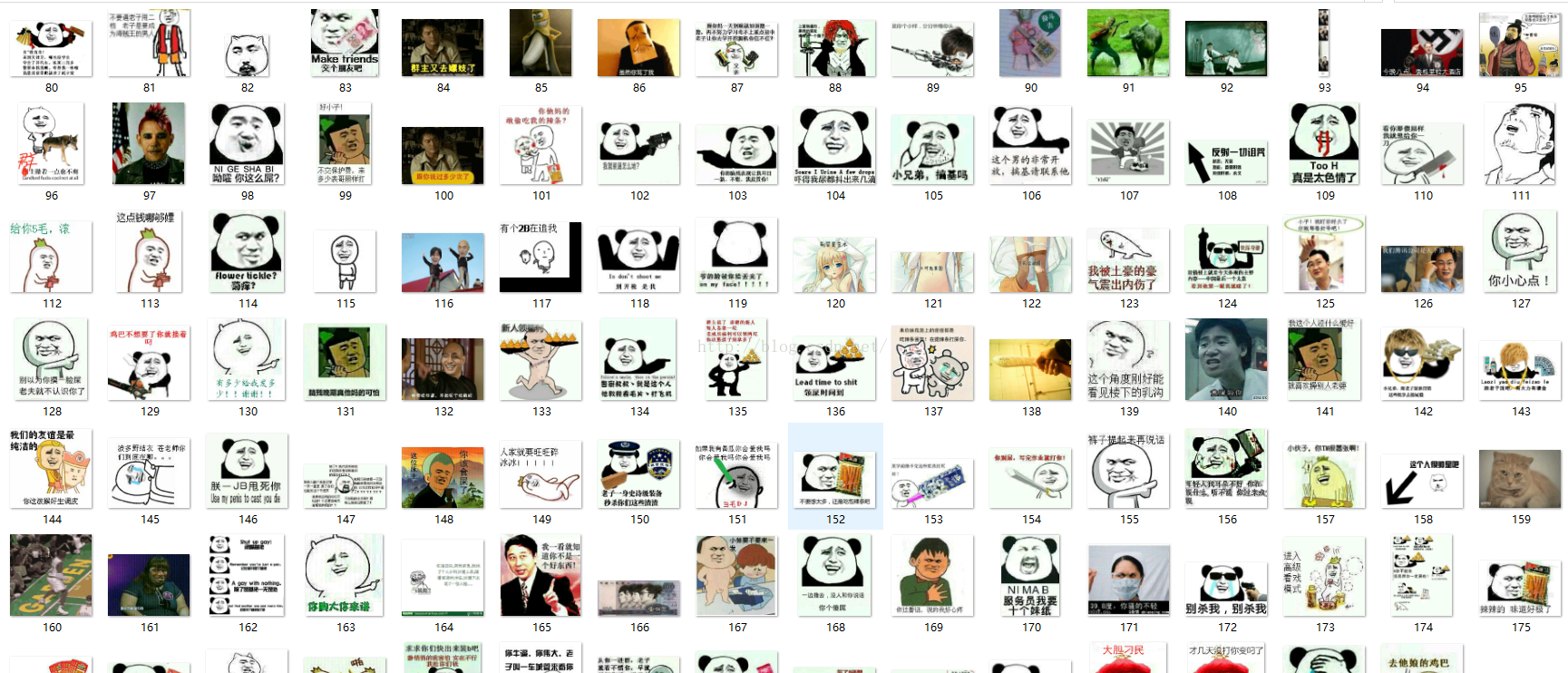
是不是很想试试呢?赶紧行动把。














 3742
3742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









