







Hadoop Federation + HA 搭建(一) – 环境准备
一 . 搭建ZK的分布式环境(3台机器,如果ZK是StandAlone的模式,只需要一台机器)
1 . 解压Zookeeper包
解压到当前目录
[root@wpixel01 www]# tar -zxvf zookeeper-3.4.10
[root@wpixel01 www]# ll
total 4488
-rw-r--r--. 1 root root 35042811 Oct 22 06:23 zookeeper-3.4.10.tar.gz
drwxr-xr-x. 11 1001 1001 4096 Jan 20 08:12 zookeeper-3.4.102 .配置ZK的参数文件:配置文件zoo.cfg
[root@wpixel01 www]# cd zookeeper-3.4.10/conf/
[root@wpixel01 conf]# cp zoo_sample.cfg zoo.cfg
[root@wpixel01 conf]# vi zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
#这里配置ZK保存数据的目录(myid文件就在这个目录下)
dataDir=/home/www/zookeeper-3.4.10/tmp
clientPort=2181
#加入ZK集群的所有节点,这里server.1中的1要和myid的内容一致
server.1=wpixel01:2888:3888
server.2=wpixel02:2888:3888
server.3=wpixel03:2888:3888
3 .将配置好的ZK复制到wpixel02和wpixel03上
[root@wpixel01 www]# scp -r zookeeper-3.4.10 root@wpixel02:/home/www/
[root@wpixel01 www]# scp -r zookeeper-3.4.10 root@wpixel03:/home/www/4 .需要修改wpixel01,wpixel02和wpixel03上的myid(自己创建)
[root@wpixel01 www]# cd zookeeper-3.4.10/tmp/
[root@wpixel01 tmp]# ll
total 1
-rw-r--r--. 1 root root 3 Jan 28 00:52 myid
#myid的内容,和zoo.cfg文件配置的server.1一致,如server.10那myid就写10
[root@wpixel01 tmp]# vi myid
15 .配置zookeeper环境变量,同时配置[wpixel02]和[wpixel03]
export ZOOKEEPER_HOME=/home/www/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin6 .然后在wpixel01,wpixel02和wpixel03上启动ZK
[root@wpixel01 www]# zkServer.sh start
[root@wpixel02 www]# zkServer.sh start
[root@wpixel03 www]# zkServer.sh start7 .查看zk状态和停止zk命令
#查看zk状态
zkServer.sh status
#停止zk命令
zkServer.sh stop8 .启动zk后的进程QuorumPeerMain
[root@wpixel01 www]# jps
19648 Jps
7128 QuorumPeerMain为什么采用Federation:
随着HDFS的数据越来越多,单个namenode的资源使用必然会达到上限,而且namenode的负载能力也会越来越高,限制HDFS的性能。
采用Federation的最主要原因是简单,Federation能够快速的解决了大部分的单点故障问题。
二 . 配置Federation
在10.211.55.111(wpixel01)上进行配置
配置文件都在hadoop-2.8.1/etc/hadoop/目录下
[root@wpixel01 www]# cd hadoop-2.8.1/etc/hadoop/
[root@wpixel01 hadoop]# ll
total 156
-rw-rw-r--. 1 500 500 4707 Jan 28 06:23 hadoop-env.sh
-rw-rw-r--. 1 500 500 1182 Jan 28 06:30 core-site.xml
-rw-rw-r--. 1 500 500 4045 Jan 28 06:41 hdfs-site.xml
-rw-rw-r--. 1 500 500 845 Jan 28 06:45 mapred-site.xml
-rw-rw-r--. 1 500 500 1663 Jan 28 07:05 yarn-site.xml
-rw-rw-r--. 1 500 500 40 Jan 28 07:06 slaves1 . hadoop-env.sh
export JAVA_HOME=/home/www/jdk1.8.0_1012 . core-site.xml
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/www/hadoop-2.8.1/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>wpixel01:2181,wpixel02:2181,wpixel03:2181</value>
</property>3 . hdfs-site.xml
<!--block副本冗余度-->
<property>
<name>ds.replication</name>
<value>2</value>
</property>
<!-- 指定hdfsde nameservices为ns1和ns2 -->
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<!--ns1下面的两个namenode,分别为nn1,nn2-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>wpixel01:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>wpixel01:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>wpixel02:9000</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs-namenode.http-address.ns1.nn2</name>
<value>wpixel02:50070</value>
</property>
<!--ns2下面的两个namenode,分别为nn3,nn4-->
<property>
<name>dfs.ha.namenodes.ns2</name>
<value>nn3,nn4</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns2.nn3</name>
<value>wpixel03:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns2.nn3</name>
<value>wpixel03:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns2.nn4</name>
<value>wpixel04:9000</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs-namenode.http-address.ns2.nn4</name>
<value>wpixel04:50070</value>
</property>
<!--指定namenode的日志在journalNode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://wpixel01:8485;wpixel02:8485;wpixel03:8485/ns1</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/www/hadoop-2.8.1/journal</value>
</property>
<!--开启ns1的namenode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled.ns1</name>
<value>true</value>
</property>
<!--配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--开启ns2的namenode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled.ns2</name>
<value>true</value>
</property>
<!--配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--*************************************************-->
<!--配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--使用sshfence隔离机制需要ssh免登陆-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置sshfence隔离机制超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>4 . mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5 . yarn-site.xml
<!--开启RM高可靠-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定RM的cluster id-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!--指定RM的名字-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!--分别指定RM的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>wpixel01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>wpixel02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>wpixel03</value>
</property>
<!--指定zookeeper集群地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>wpixel01:2181,wpixel02:2181,wpixel03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>6 . slaves
wpixel01
wpixel02
wpixel03
wpixel047 .节点预览
| 节点 | ||
|---|---|---|
| ns1 | nn1(wpixel01) | nn2(wpixel02) |
| ns2 | nn3(wpixel03) | nn4(wpixel04) |
以上配置完成后,拷贝到其他三台主机上
[root@wpixel01 www]# scp -r hadoop-2.8.1/ root@wpixel02:/home/www/
[root@wpixel01 www]# scp -r hadoop-2.8.1/ root@wpixel03:/home/www/
[root@wpixel01 www]# scp -r hadoop-2.8.1/ root@wpixel04:/home/www/修改ns2节点时需要注意的地方
只要修改两个文件
core-site.xml 和 hdfs-site.xml
修改wpixel03和wpixel04的core-site.xml文件
[root@wpixel03 hadoop]# vi core-site.xml
<!-- 指定hdfs的nameservice为ns2 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns2</value>
</property>
ns1节点中的value值:hdfs://ns1
ns2节点中的value值:hdfs://ns2
修改wpixel03和wpixel04的hdfs-site.xml文件
[root@wpixel03 hadoop]# vi hdfs-site.xml
<!--指定namenode的日志在journalNode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://wpixel01:8485;wpixel02:8485;wpixel03:8485/ns2</value>
</property>
ns1节点中的value值:qjournal://wpixel01:8485;wpixel02:8485;wpixel03:8485/ns1
ns2节点中的value值:qjournal://wpixel01:8485;wpixel02:8485;wpixel03:8485/ns28 .配置完毕,启动测试
- 启动Zookeeper (已经启动了,略)
- 启动JournalNode
[root@wpixel01 www]# hadoop-daemon.sh start journalnode
[root@wpixel02 www]# hadoop-daemon.sh start journalnode
[root@wpixel03 www]# hadoop-daemon.sh start journalnode- 格式化ZooKeeper
在wpixel01和wpixel03上执行hdfs zkfc -formatZK
这是一个zookeeper控制器,用于HA切换
[root@wpixel01 www]# hdfs zkfc -formatZK
[root@wpixel03 www]# hdfs zkfc -formatZK
- 格式化ns1的NameNode
#对wpixel01节点进行格式化
[root@wpixel01 www]# hdfs namenode -format -clusterId hadoop
18/01/28 07:34:09 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = root
STARTUP_MSG: host = wpixel01/10.211.55.111
STARTUP_MSG: args = [-format, -clusterId, hadoop]
STARTUP_MSG: version = 2.8.1
STARTUP_MSG: classpath = /home/w*****************
************************************************************/
18/01/28 07:34:09 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/01/28 07:34:09 INFO namenode.NameNode: createNameNode [-format, -clusterId, hadoop1]
Formatting using clusterid: hadoop
***************************
#看到successfully说明格式化成功
18/01/28 07:34:10 INFO common.Storage: Storage directory /home/www/hadoop-2.8.1/tmp/dfs/name has been successfully formatted.
#启动wpixel01的namenode
[root@wpixel01 www]# hadoop-daemon.sh start namenode
#对wpixel02节点进行格式化
[root@wpixel02 www]# hdfs namenode -bootstrapStandby
18/01/28 07:31:43 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = root
STARTUP_MSG: host = wpixel02/10.211.55.112
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 2.8.1
****************************
18/01/28 07:31:43 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/01/28 07:31:43 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
About to bootstrap Standby ID nn2 from:
Nameservice ID: ns1
Other Namenode ID: nn1
Other NN's HTTP address: http://wpixel01:50070
Other NN's IPC address: wpixel01/10.211.55.111:9000
Namespace ID: 1691295794
Block pool ID: BP-6442734-10.211.55.111-1517142447286
#这里的ID要和wpixel01设置的ID相同,
Cluster ID: hadoop
Layout version: -63
isUpgradeFinalized: true
#启动wpixel02的namenode
[root@wpixel02 www]# hadoop-daemon.sh start namenode
现在可以在浏览器上查看
http://10.211.55.111:50070查看
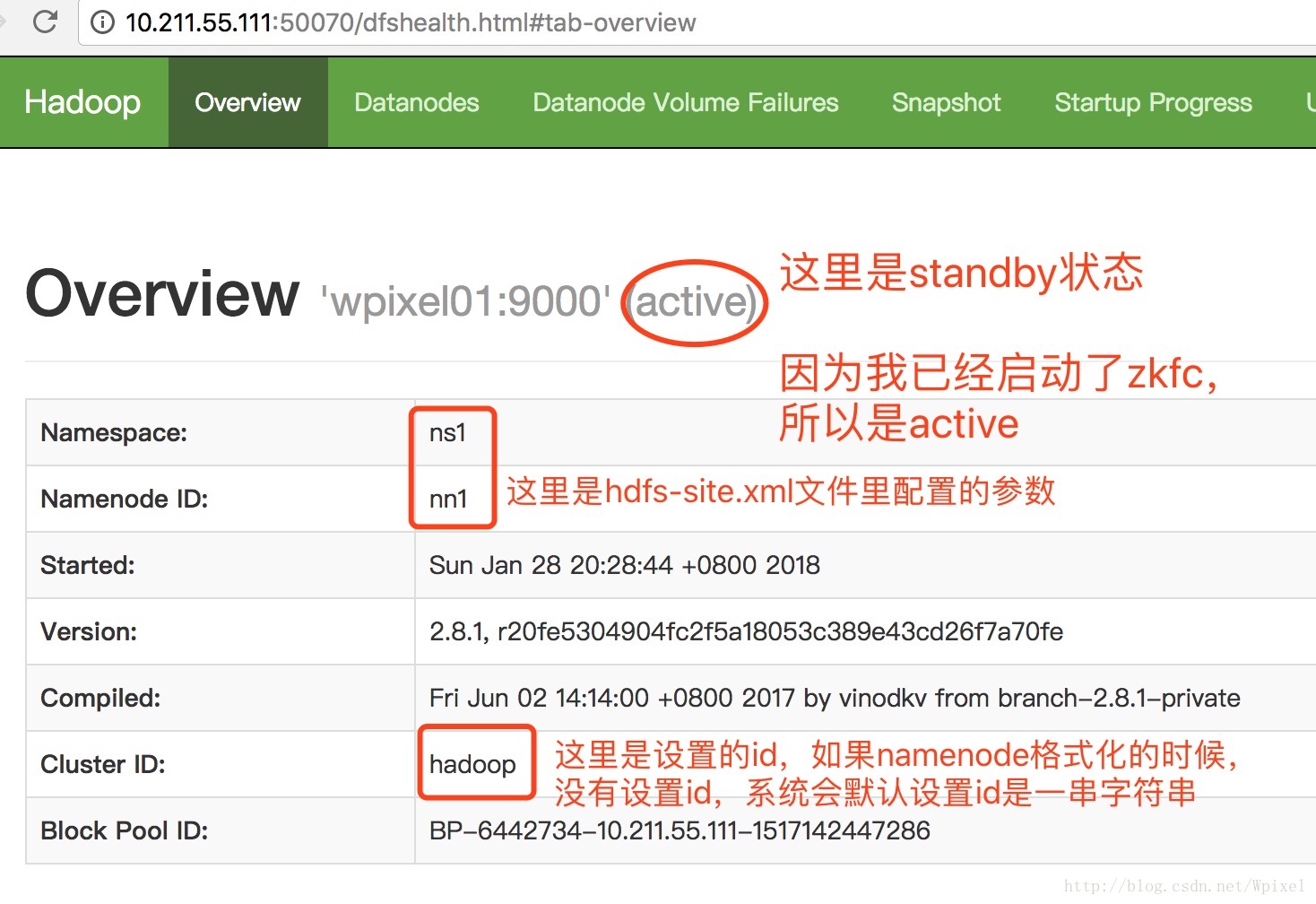
http://10.211.55.112:50070查看
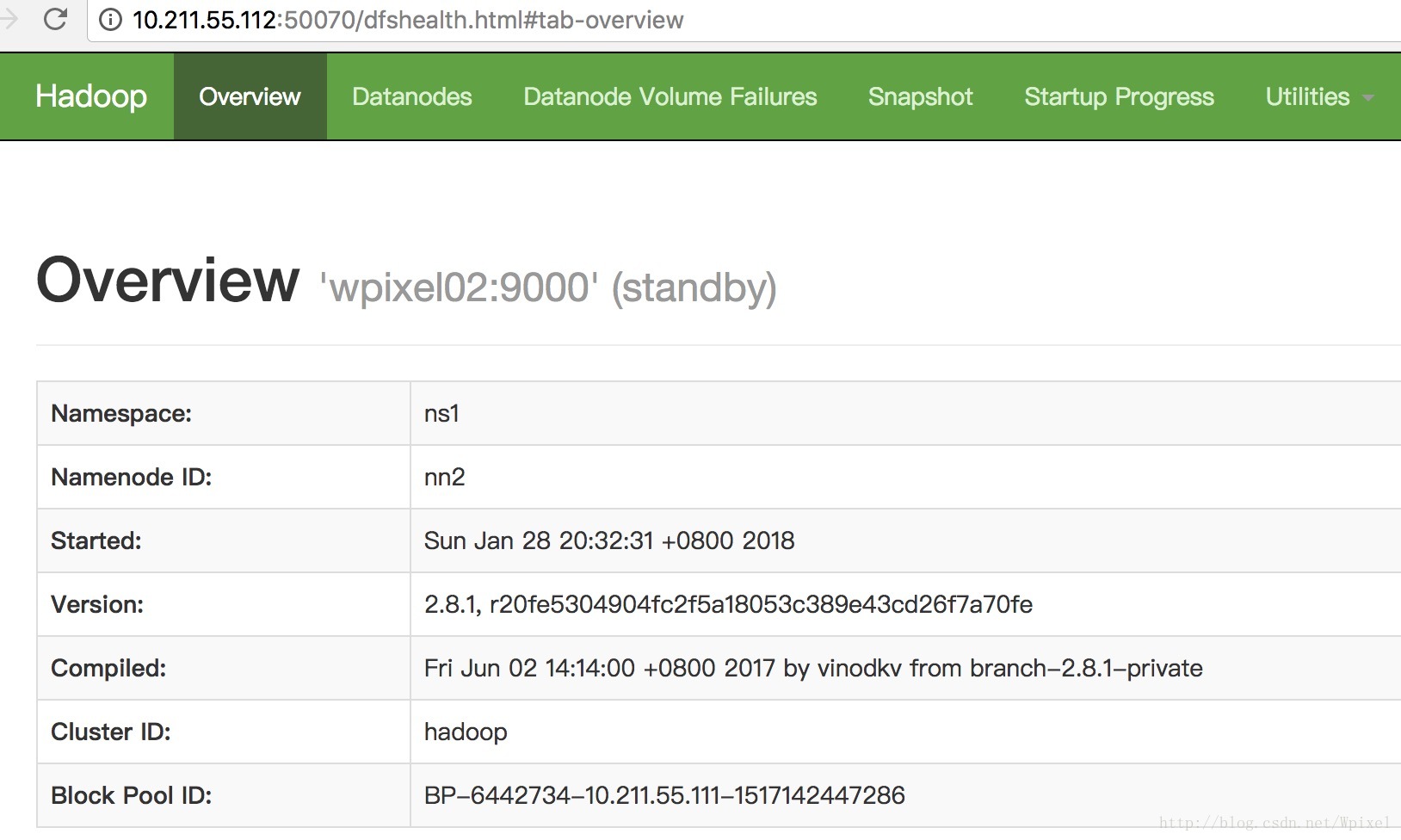
- 格式化ns2的NameNode
#对wpixel03节点进行格式化
[root@wpixel03 www]# hdfs namenode -format -clusterId hadoop1
#启动wpixel03的namenode
[root@wpixel03 www]# hadoop-daemon.sh start namenode
#对wpixel04节点进行格式化
[root@wpixel04 www]# hdfs namenode -bootstrapStandby
#启动wpixel04的namenode
[root@wpixel04 www]# hadoop-daemon.sh start namenode
也可以查看wpixel03和wpixel04
http://10.211.55.113:50070
http://10.211.55.114:50070
- 然后启动所有的datanode
我这里只启动了一台,所以还要在其他主机上执行
[root@wpixel01 www]# hadoop-daemon.sh start datanode
starting datanode, logging to /home/www/hadoop-2.8.1/logs/hadoop-root-datanode-wpixel01.out
[root@wpixel02 www]# hadoop-daemon.sh start datanode
[root@wpixel03 www]# hadoop-daemon.sh start datanode
[root@wpixel04 www]# hadoop-daemon.sh start datanode- 启动yarn
[root@wpixel01 www]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/www/hadoop-2.8.1/logs/yarn-root-resourcemanager-wpixel01.out
wpixel02: starting nodemanager, logging to /home/www/hadoop-2.8.1/logs/yarn-root-nodemanager-wpixel02.out
wpixel03: starting nodemanager, logging to /home/www/hadoop-2.8.1/logs/yarn-root-nodemanager-wpixel03.out
wpixel04: starting nodemanager, logging to /home/www/hadoop-2.8.1/logs/yarn-root-nodemanager-wpixel04.out
wpixel01: starting nodemanager, logging to /home/www/hadoop-2.8.1/logs/yarn-root-nodemanager-wpixel01.out然后在wpixel02和wpixel03的主机上启动resourcemanager
[root@wpixel02 www]# yarn-daemon.sh start resourcemanager
[root@wpixel03 www]# yarn-daemon.sh start resourcemanager在四台主机上启动zkfc,就会有进行HA选举,standby会有一个变成active状态
[root@wpixel01 www]# hadoop-daemon.sh start zkfc
[root@wpixel02 www]# hadoop-daemon.sh start zkfc
[root@wpixel03 www]# hadoop-daemon.sh start zkfc
[root@wpixel04 www]# hadoop-daemon.sh start zkfc9 .结果展示一( 通过web端,查看集群运行情况)
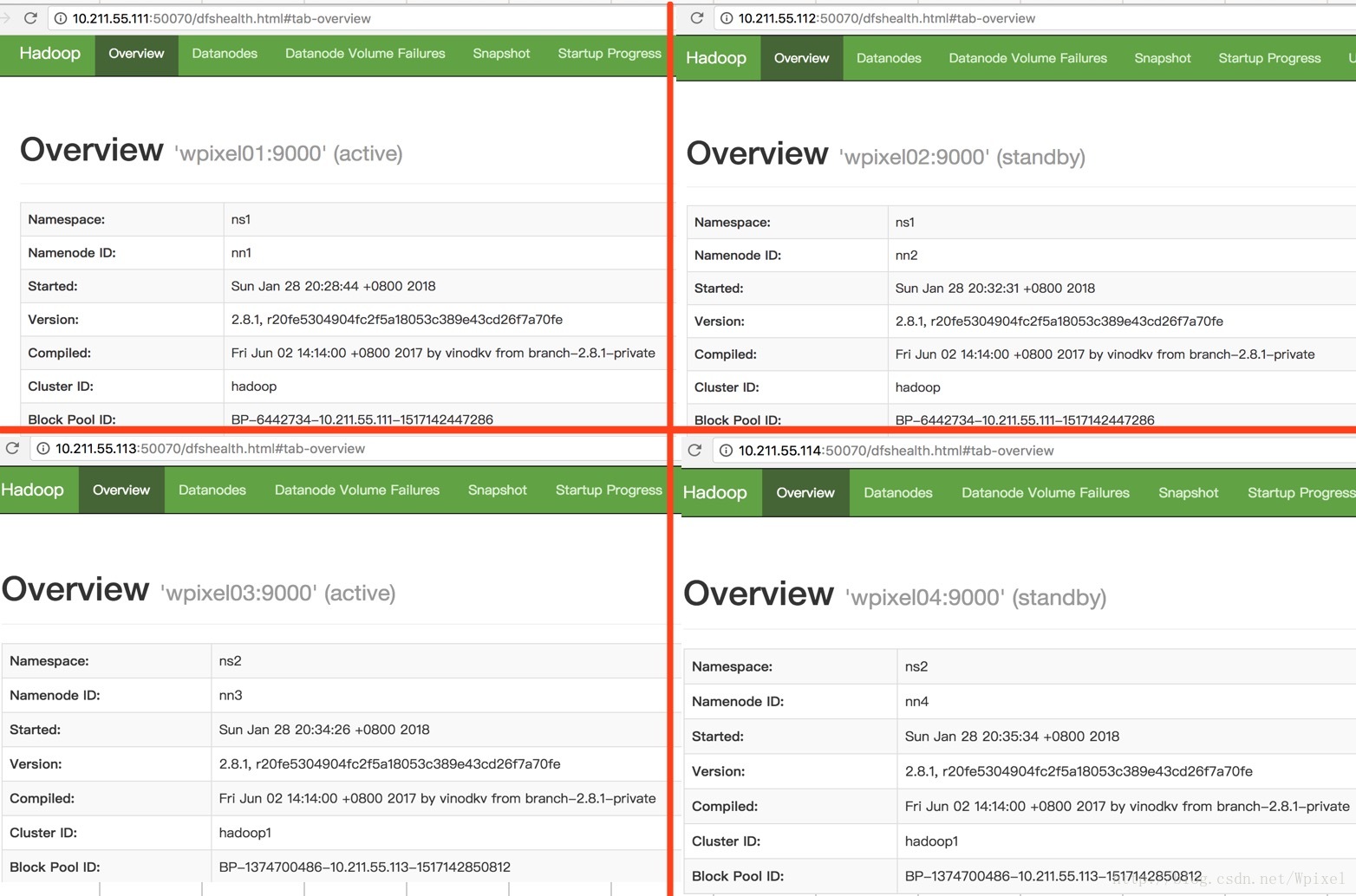
10 .结果展示二( 通过jps查看集群守护进程)
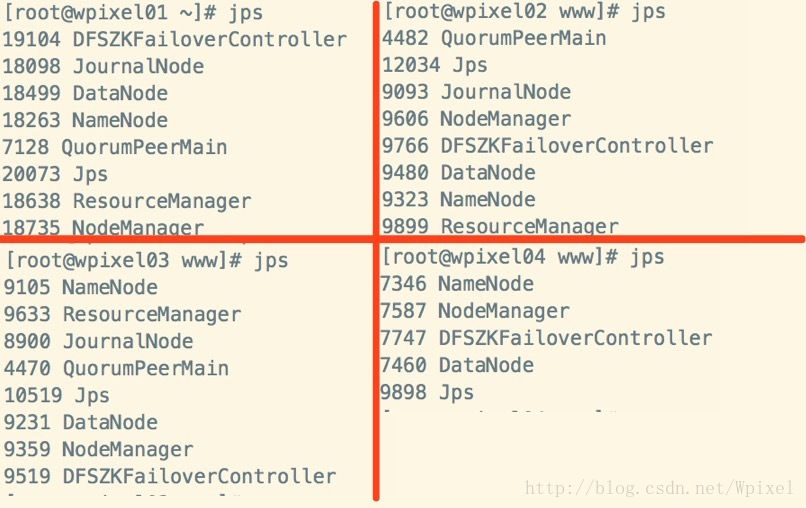
Hadoop Federation + HA 搭建(三) – wordCount测试













 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









