







一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?

在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下:
1. UNICODE (UTF8-16),C854;
2. UTF-8,E59388;
3. GBK,B9FE。
一、python中的str和unicode
一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为
u'\u54c8\u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果你想使这个字节流显示的内容有意义,就必须用正确的编码格式,解码显示。
例如:
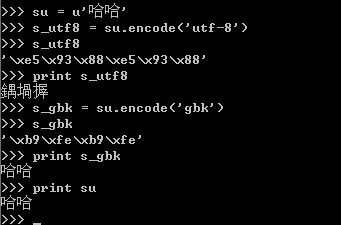
对于unicode对象哈哈进行编码,编码成一个utf-8编码的str-s_utf8,s_utf8就是是一个字节数组,存放的就是'\xe5\x93\x88\xe5\x93\x88',但是这仅仅是一个字节数组,如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?
因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据系统的编码对输入的字节流进行编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 '\xe5\x93\x88\xe5\x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









