









You Only Look Once: Unified, Real-Time Object Detection
YOLO官网
论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
简介与特点
YOLO是今年CVPR上提出的一种目标检测方法,其速度达到了45fps(YOLO v2 达到了67fps),完全可以处理视频。其框架是直接利用CNN的全局特征预测每个位置可能的目标,比RCNN先检测多个RP再CNN快了很多。
实际测试中,检测提供的dog.jpg图片(768*576)使用了0.043s,GPU是K40,也到了20fps以上。
其大致流程为:
- 缩放图片到448x448;
- 运行单个CNN;
- 通过模型的置信度阈值得到检测结果。

除了速度快这一特点,还有:
背景误差小
YOLO在预测时考虑全局图像,与滑动或region proposal只提出图像中一块区域不同。因此更能得到分类目标附近区域信息, 与快速R-CNN相比,YOLO的背景误差数量少于一半。学习对象的可概括表示
当训练对象为自然图像,而测试图像为艺术作品时,有很好的检测率。不足
精度相比于最先进的检测系统,但YOLO v2 已经达到了76.8的mAP。
统一检测
YOLO将分离的组件检测器统一到一个神经网络中。网络使用整幅图的特征来预测bounding box,同时进行分类,网络全局地考虑整个图像和图像中的所有对象。
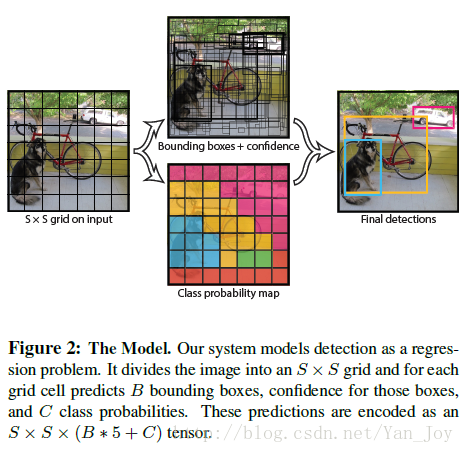
首先把图像分成
S×S
个网格,如果对象的中心落入网格单元中,则该网格单元负责检测该对象。每个网格单元预测这些框的
B
个bounding box和置信度得分。 这些置信度分数反映了box包含某种对象的自信程度,以及它对框预测的box的准确程度。定义置信度为:
如果该网格中没有目标,则Pr项值应该为0,整体为0,否则为1。
每个bounding box包括5个预测值:x,y,w,h和置信度。 (x,y) 坐标表示相对于网格单元的边界的框的中心。每一块需要预测的值是bounding box相对于该块中心的偏移,以及相对长宽,类别。
每个网格单元还预测 C 条件类概率
最终预测结果为 S×S×(B∗5+C) 的张量。
网络设计
模型以CNN实现,网络的初始卷积层从图像中提取特征,而完全连接的层预测输出概率和坐标。网络有24卷积层,其次是2完全连接的层。如图所示:
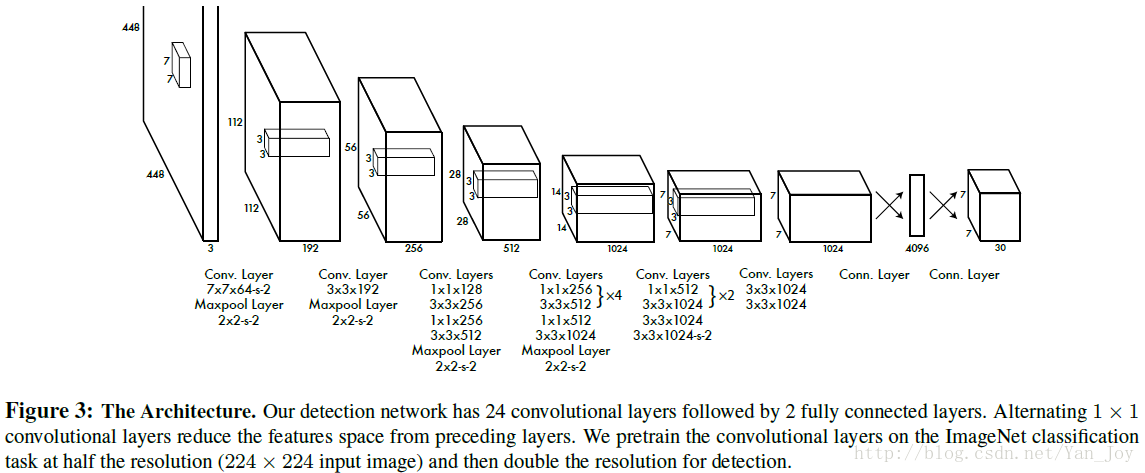
输出为
7×7×30
的张量。
每个grid有30维,这30维中,8维是回归box的坐标,2维是box的confidence,还有20维是类别。 其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
训练
最终层预测类概率和边界框坐标。 通过图像宽度和高度将边界框宽度和高度归一化,使得它们落在0和1之间。我们将边界框x和y坐标参数化为特定网格单元位置的偏移,使得它们也在0和1之间 。
最后一层使用线性激活函数(linear activation function),其他层使用leaky rectified linear activation:
ϕ(x)={x,0.1x,if x>0otherwise优化了模型输出中的平方误差。
使用平方误差,因为它很容易优化,但它不完全符合我们的最大化平均精度的目标。 It weights localization error equally with classification error,即8维的localization error和20维的classification error 同样重要,这可能不是理想的。 此外,在每个图像中,许多网格单元不包含任何对象。 这将这些网格单元的“置信度”为零,通常压倒包含对象的网格的梯度。 这可能导致模型不稳定,导致训练早期发散。
为了弥补这一点,增加了边界框坐标预测的损失,并减少了对不包含对象的框的置信预测的损失。 使用两个参数, λcoord 和 λnoobj 来完成这个,设置 λcoord=5 和 λnoobj=0.5 。通过这样的因子设置,更重视8维的坐标预测,即给这些localization error损失前面赋予更大的loss weight, 更小的classification error 。
对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。 预测边界框宽度和高度的平方根,而不是宽度和高度。
在训练期间,我们只需要一个bounding box预测器负责每个对象(原本每个网格单元会有B个预测)。 我们将一个与ground truth相比的最高IOU的预测器指定为“负责”。
loss function:
其中 1obji 表示如果对象出现在单元格i中, 1objij 表示网络单元格i中的第j个bounding box预测器对于该预测是“负责”的。如果对象存在于该网格单元中,则损失函数仅惩罚分类误差(因此前面讨论的条件类概率)。 它也只惩罚边界框坐标误差,如果该预测器是对ground truth “负责”的。即:- 只有当某个网格中有object的时候才对classification error进行惩罚。
- 只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大。

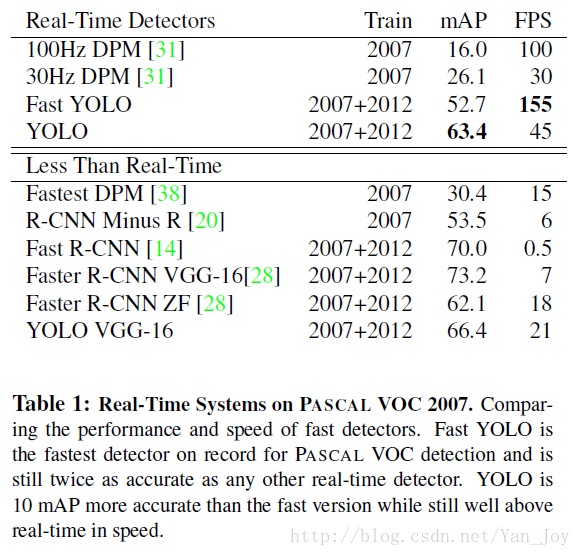
测试结果
如表:
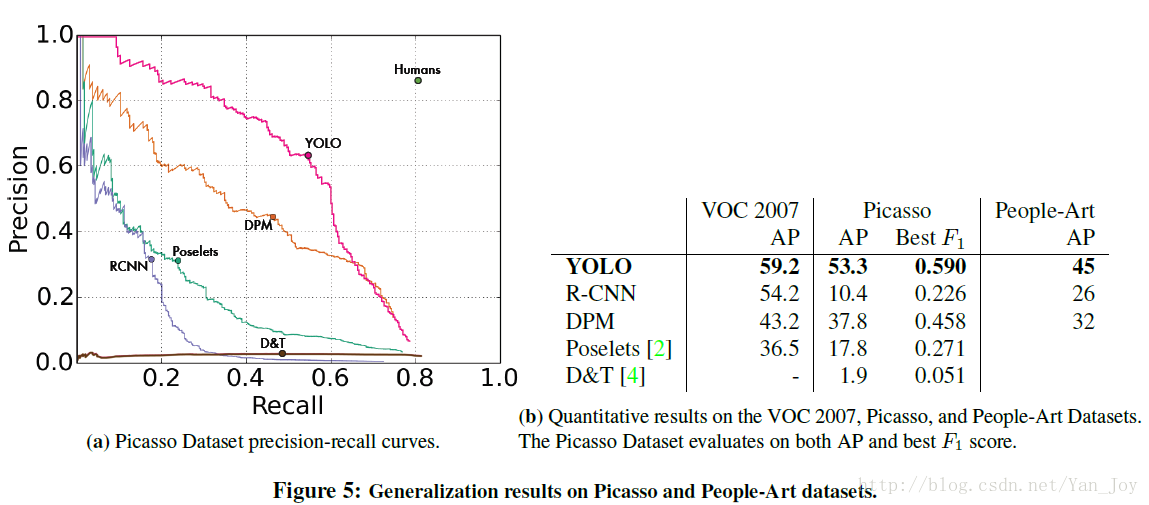
特别的,作者还进行了艺术作品中的检测识别,以测试其泛化性能。














 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









