






浏览器判断返回的 HTTP 响应消息所使用的编码遵循以下一系列规则。
1.首先, 浏览器会检查 HTTP 响应中的“Content-type”消息头。 如“text/html;charset=UTF-8”, 表明该消息所包含的内容是纯文本的 HTML 文档,采用 UTF-8 编码。但在很多情况下,服务 器返回的 Content- type 消息头并不包含“charset”信息。
2. 当响应消息不包含“charset”信息时,浏览器会尝试自动探测编码。第一个步骤是检查响 应消息体的开头是否包含 UTF-8 的 BOM(字节顺序标 记,Byte Order Marker)。BOM 是一 种用来判断文件编码的特定字节标记, 如果一个文件的开头几个字节包含了 UTF-8 的 BOM,那么浏览器就可以断定这个 HTML 文件是采用 UTF-8 编码的。
3. 如果该 HTML 中不包含 BOM, 那么, 浏览器就会尝试寻找 HTML 页面中的<meta>标记,如: <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
4. 如果页面中又不包含<meta>标记,那么,浏览器将采用默认的编码来解析。在中文的 IE 和 Firefox 里就是采用 GBK 或 GB2312 编码。 因此, 要使服务器端返回的响应消息能够正确地被浏览器解析, 最简单有效的方法就是 在响应的“Content-type”消息头中设置 charset 属性。
验证上述结论,实验如下:先看代码:
package net.programe.ten;
import java.io.*;
import java.net.*;
public class SingleFileHttpServer extends Thread {
//发送数据的正文
private byte[] content;
//发送数据的首部
private byte[] header;
//默认端口为80
private int port = 80;
public SingleFileHttpServer(String data, String encoding, String MIMEType, int port)
throws UnsupportedEncodingException {
this(data.getBytes(encoding), encoding, MIMEType, port);
}
public SingleFileHttpServer(byte[] data, String encoding, String MIMEType, int port)
throws UnsupportedEncodingException {
this.content = data;
this.port = port;
String header = "HTTP/1.0 200 OK\r\n"
+ "Server:OneFile 1.0\r\n"
+ "Content-length:" + this.content.length + "\r\n"
+ "Content-type:" + MIMEType + "\r\n\r\n";
this.header = header.getBytes(encoding);//都是英文,什么编码格式都ok
//this.header = header.getBytes("gbk");//都是英文,什么编码格式都ok
}
@Override
public void run() {
try {
//创建服务器socket
ServerSocket server = new ServerSocket(this.port);
System.out.println("接收来自端口为" + server.getLocalPort() + "的客户端的连接");
while (true) {
Socket conn = null;
try {
conn = server.accept();
//定义一个输出流,用来向客户端发送数据
OutputStream out = new BufferedOutputStream(conn.getOutputStream());
//定义一个输入流,用来读取客户端发来的数据
InputStream in = new BufferedInputStream(conn.getInputStream());
//创建字符缓冲区,初始容量为80个字符
StringBuffer request = new StringBuffer(80);
//只读取一行
while (true) {
//读取一个字节的数据
int c = in.read();
if (c == '\r' || c == '\n' || c == -1) {
break;
}
request.append((char) c);
}//end while
System.out.println(request);
//如果是HTTP/1.0或者以后的版本,就发送一个MIME首部
if (request.toString().indexOf("HTTP/") != -1) {
//向客户端发送消息
out.write(this.header);
}
System.out.println(this.header);
//发送context
out.write(content);
//涮新
out.flush();
} catch (IOException ex) {
}
}//end while
} catch (IOException ex) {
ex.printStackTrace();
}
}//end run
public static void main(String[] args) throws UnsupportedEncodingException {
String encoding = "big5";
byte content[] = "hello java net 十大領軍".getBytes(encoding);
Thread t = new SingleFileHttpServer(content, encoding, "text/html", 80);
t.start();
}
}
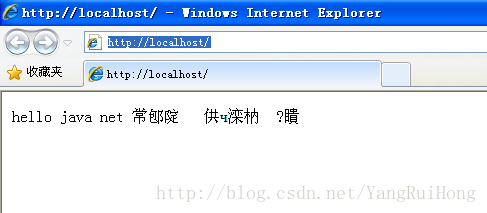
消息头没有设置charset,消息体也没有编码信息,中文系统默认编码是gbk或gb2312,现在代码中使用繁体编码big5,按照上述理论,浏览器的显示结果中文应该是乱码
浏览器响应:














 4404
4404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









