







Princeton的算法课是目前为止我上过的最酣畅淋漓的一门课,得师如此夫复何求,在自己的记忆彻底模糊前,愿对这其中一些印象深刻的点做一次完整的整理和回顾,以表敬意。

算法,第一部分:https://www.coursera.org/course/algs4partI
-
注:
这是一篇更关注个人努力与完成任务项目过程相关的文章,内容集中于课程背后值得提到的部分,不会介绍课程基本信息及学习时必读的设定要求等部分,敬请谅解。
在学习一门课程的时候考虑为什么这么教是个人习惯,我会尝试给出一些解读,为什么这门课这么屌(awesome)。
优化无止境,越学习才能越深刻地感受自己的无知,即使是作业内已提到的额外内容我也并没有一一探究完整,这里只是谦卑地尽力记录自己的努力,并无意与谁比较,如有新的进展还会回来更新。
除特别标注外,文章非原创插图全部来自课程相关资源。
每一小节的作业题目链接到specification,“√”链接到checklist,“〇”链接到code下载。
这里提供一个全文完整的资源树。
剧透预警:
内容包含大作业的关键问题解法分析。
-
I. Union Find与Percolation √ 〇
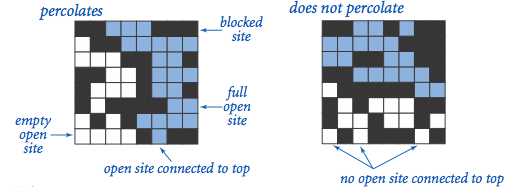
作为第一部分开学第一课,作业Percolation可谓精妙:
1. 既没有复杂的语法使用(仅数组操作),又着实比在基础语言层面上升了一个档次;
2. 漂亮的visualizer动画效果激励着初学者完成任务;
3. 强大的autograder功能初次展现,评价算法的主要管道一目了然,每一微秒每一字节都很重要;
4. 针对学习迅速的同学还隐含了一个很大的挑战:在仅使用一个WeightedQuickUnionUF对象的前提下,解决backwash问题。
下面主要聊聊backwash:
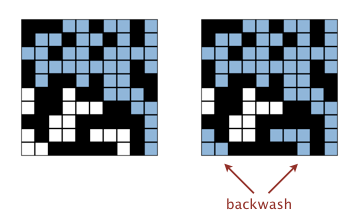
问题的核心源自virtual top/bottom,一个强行被导师在课程视频中提到的优化方法,于是天真的同学们(我)就去开心地实现这个看似无辜而又性能楚楚动人的方法,却毫不了解导师在下一节中马上提出的backwash问题是何物,还觉得这种低级错误怎么可能会发生:
java-algs4 PercolationVisualizer percolation/input10.txt
……

(我发誓这就是我看到的东西……)
把痛碎的心小心拼回,认真思索一番后确定问题根源出在virtual bottom,一个显而易见的解决方案便浮现在眼前:使用两个UF,一个使用vb一个不用,判断percolate用前者,判断full用后者,解决!
然而checklist的一句话又引起了我的注意:Raw Score 100.00 / 100.00
加上autograder特别温馨的提醒“bonus failed”,我不得不重新开始审视这个问题。However, many students consider this to be the most challenging and creative part of the assignment (especially if you limit yourself to one union-find object).
后来的事实证明,直到课程结束没有一个问题再让我如此头疼。经过了一段可谓长征式的思考,加之在forum的讨论中得到了一点灵感(多加利用Find()),最终形成并实现了解决方案,方案核心如下(corner case另行处理):
1. 将原方案中表示open状态的boolean数组改为byte数组,设定规则如下:初始化的默认值0代表blocked site,赋1代表open site,赋2代表与尾行相连的open site;
2. 每open一个site,如果位于尾行则赋2,否则赋1;
3. 分别对每个邻接site检测:如任何一方的root site对应byte值为2,将双方Union后的root site设为2。(root为Find()的返回值)
此方案下,判断open只需要对应byte>0,判断full使用UF结果准确,判断percolates检测virtual top的root site对应byte是否为2。
Raw Score 101.25 / 100.00
Test 2 (bonus): Check that total memory <= 11 N^2 + 128 N + 1024 bytes
==> passed
对这个作业来说,上面这三行的成绩凝聚了太多。
-
II. Resizing Array & Linked Lists与Randomized Queues and Deques √ 〇
第二周课程正式展开,但在作业深度上相对稍有下降,根据指定的性能和API要求,选择适当的实现方式(动态数组、单、双向链表),实现Randomized Queue和Deque,主要训练基本的算法分析和编程严谨性(完善处理corner-case),但并无特别的难点。有两个小技巧可以提出:链表可使用sentinel node(s)使代码更简洁(checklist已提),写client时可先shuffle再插入(bonus)。
过程中一并学习了Java的Generics,Iterable,Iterator概念,在大学课程部分已学习掌握得比较熟练,可不谈,the result speaks:
Raw Score 100.19 / 100.00
Test 3 (bonus): Check that maximum size of any or Deque or RandomizedQueue object created is <= k
==> passed
结合两次作业特性,可看出一些值得一提的点:
作业任务要求与说明往往面面俱到细致入微,在给定公有API框架及其对应时间空间复杂度的基础上,结合课程视频知识内容,这种“受指导”的编程过程变得十分清晰,尤其是其中API的设计,风格简洁高效到自成一家,我认可自己的代码风格已很简洁,而algs4.jar让我第一次看到了更高;
给定充足的测试材料,包括各类corner-case或相对有趣的输入数据(如sedgewick60.txt),及合适情况下生动的可视化工具(如PercolationVisualizer.java),都使得学生可以全力,高效,有动力地,将精力集中在核心算法本身上。

-
III. Sorting与Pattern Recognition - Collinear Points √ 〇
本周的课程介绍了两大经典排序:Mergesort和Quicksort,自然作业也与sorting紧密相关。Collinear Points(找出所有4个或以上共线的点构成的点集)是第一个在运行时见证“好的算法”与“暴力算法”直观差别的作业,这样的对比能给学生带来深刻的影响:忙了好久,为了什么?

左图为暴力算法(~N^4)求解100个数据点(input100.txt),右图为基于排序的算法(~N^2logN)求解1423个数据点(rs1423.txt)
测试数据还有很多。图中示例对快速算法给定数据量庞大了不止10倍,运行时间却与不到1/10数据量下的暴力算法接近;对左图数据,快速算法基本看不到找线的动画过程就完成了;对右图数据,暴力算法在可以忍受的时间里基本找不到几条线。
这样的运行结果可以给学生一种非常好的对自己努力的掌控感,正是这样一个个美妙的瞬间使学生能以最好的状态与饱满的好奇心在算法之路上继续走下去。
作业说明中对核心算法的描述非常清晰,应当特别小心的技术点(浮点误差、正负零等等)也都在checklist中予以强调,因而实现难度不算很大,其中使用了Java的Comparable与Comparator,排序过程调用Arrays.sort(),详细思考问题理清关系后,实现非常自然,前提是编程基本功必须扎实。
值得提到的点:
checklist鼓励初学者开始编写快速算法时先不要担心5个或以上的点共线的情况,而实际上对基本功扎实的同学,从开始便考虑这个问题更为合适;
checklist提到compare()和FastCollinearPoints类可以完全避免浮点数用整形运算实现,我想到的唯一符合要求(Point.java注释中规定不得依赖toString()ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4582
4582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









