







#!/usr/bin/env python
# encoding: utf-8
#========================================================================
# MACHINE LEARNING IN ACTION - CH02
# kNN classify algorithm
# Typed in Feb 14, 2016 by Alex
#========================================================================
from numpy import *
import operator
def classify_0(inX,dataSet,labels,k):
sizeOfDS=dataSet.shape[0]
# --> tile()
# Build a matrix with sizeOfDS rows and 1 column
# to calculate the differences.
diffMat=tile(inX,(sizeOfDS,1))-dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
# --> argsort()
# Sort the members of a matrix and return the sorted index of each.
sortedDistIndicies=distances.argsort()
classCount={}
for i in range(k):
voteInLabel=labels[sortedDistIndicies[i]]
# --> dict.get()
# Append a item to the dict and set default as the second parameter.
classCount[voteInLabel]=classCount.get(voteInLabel,0)+1
# --> sorted
# Sort members of object by key(mutiple dimension)
# and reverse's default key if False which means return ascenting sequence.
# --> items()
# Return the items in a couple.
sortedClassCount=sorted(classCount.items(),\
# --> operator.itemgetter()
# Get and return the indicated dimension members of object.
key=operator.itemgetter(1),\
reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
fr=open(filename)
numberOfLines=len(fr.readlines())
returnMat=zeros((numberOfLines,3))
classLabelVector=[]
fr=open(filename)
index=0
for line in fr.readlines():
# -->line.strip()
# Return a copy of the string with the leading
# and trailing characters removed.
line=line.strip()
# -->line.split()
# Get the contents from file in line seperated by Tab character.
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
row=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(row,1))
normDataSet=normDataSet/tile(ranges,(row,1))
return normDataSet,ranges,minVals
def datingClassTest():
hoRatio=0.10
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
row=normMat.shape[0]
numTestVecs=int(row*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify_0(normMat[i,:],\
normMat[numTestVecs:row,:],\
datingLabels[numTestVecs:row],\
3)
print("the classifier came back with: %d, the real answer is: %d"\
% (classifierResult,datingLabels[i]))
if(classifierResult!=datingLabels[i]):errorCount+=1.0
print("=============================================================")
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))
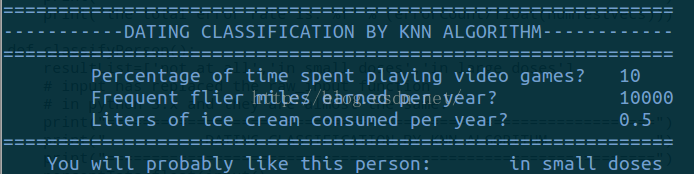
def classifyPerson():
resultList=['not at all','in small doses','in large doses']
# input has replaced the raw_input function
# in python 3.x and they are almost the same.
print("=============================================================")
print("-----------DATING CLASSIFICATION BY KNN ALGORITHM------------")
print("=============================================================")
percentTats=float(input(\
"\tPercentage of time spent playing video games?\t"))
ffMiles=float(input("\tFrequent flier miles earned per year?\t\t"))
iceCream=float(input("\tLiters of ice cream consumed per year?\t\t"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
classifierResult=classify_0((inArr-minVals)/ranges,\
normMat,datingLabels,\
3)
print("=============================================================")
print(" You will probably like this person: ",\
resultList[classifierResult-1])
#------------------------------------------------------------------------
# Ch02 handwriting congition system by kNN algorithm
#------------------------------------------------------------------------
def img2vector(filename):
returnVect=zeros((1,1024))
fr=open(filename)
for i in range(32):
lineStr=fr.readline()#readline() just read one line
for j in range(32):
returnVect[0,32*i+j]=int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels=[]
trainlingFileList=listdir('trainingDigits')
m=len(trainlingFileList)
trainingMat=zeros((m,1024))
for i in range(m):
fileNameStr=trainlingFileList[i]
fileStr=fileNameStr.split('.')[0]
classNumStr=int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:]=img2vector('trainingDigits/%s' % fileNameStr)
testFileList=listdir('testDigits')
errorCount=0.0
mTest=len(testFileList)
for i in range(mTest):
fileNameStr=testFileList[i]
fileStr=fileNameStr.split('.')[0]
classNumStr=int(fileStr.split('_')[0])
vectorUnderTest=img2vector('testDigits/%s' % fileNameStr)
classifierResult=classify_0(vectorUnderTest,\
trainingMat,\
hwLabels,\
3)
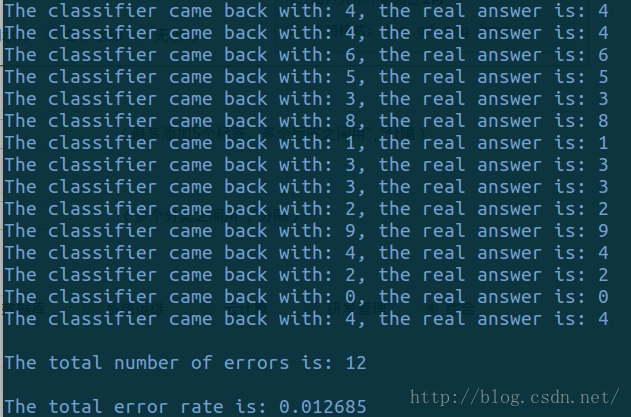
print("The classifier came back with: %d, the real answer is: %d\
" % (classifierResult,classNumStr))
if (classifierResult!=classNumStr): errorCount+=1.0
print("\nThe total number of errors is: %d" % errorCount)
print("\nThe total error rate is: %f" % (errorCount/float(mTest)))














 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









