






1. 概况
hadoop MapReduce是一个软件框架,在这个框架上可以很容易编写以可靠、容错地运行在大量廉价硬件组成的集群(上千节点)上、并行地处理大量数据(数TB数据集)的程序。
MapReduce job经常将输入数据集切分成独立的大块,然后用map任务以完全并行的方式处理。框架将maps输出排序,并作为reduce任务的输入。典型情况下job的输入和输出都会存储在文件系统中。框架处理任务安排、监测和重新执行失败的任务。
典型情况下计算节点和存储节点是同一个节点,也就是说,MapReduce框架和HDFS运行在同一节点集上。这个配置允许框架高效地在数据现成的节点上安排任务,导致跨节点非常高的综合带宽。
MapReduce框架有单一的resourceManager主机、每个集群节点一个nodemanager从机,和每个应用一个MRAppmaster。
最小情况下,应用指定input和output地址,通过实现合适的接口和抽象类来提供map和reduce功能。这些和其他的job参数构成job配置。
hadoop job客户端提交job(jar/executable等)和配置给resourcemanager,由resourcemanager承担分发软件、配置给从机,安排任务,监控任务,提供状态和诊断信息给job客户端。
虽然hadoop框架由java实现,MapReduce应用不需要由java编写。
- hadoop steaming是一个工具,允许用户使用任何可执行程序(比如shell utilities)作为mapper/reducer建立和运行jobs。
- hadoop pipes是一个兼容SWIG的C++ API,来实现MapReduce应用(不以JNI为基础)。
2. inputs and outputs
MapReduce框架专门操作< key,value >对,也就是框架把input看作< key,value >集,并产生一套< key,value >集作为job的输出,conceivably of different types.
key和value类必须被框架序列化,因此需要实现writable接口。另外,key类必须实现writablecompareble接口以促进框架排序。
一个MapReduce job的输入和输出类型:
(input)< k1,v1 > —> map —>< k2,v2 > —>combine —>< k2,v2 > —>reduce —>< k3,v3 >(output)
3. wordcount v1.0
wordcount是一个简单的应用,统计一个给定输入集的每个单词的出现次数。
1. 源代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 2. 使用
设定环境变量如下:
export JAVA_HOME=/usr/java/default
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar编译WordCount.java,建立jar文件
$ bin/hadoop com.sun.tools.javac.Main WordCount.java
$ jar cf wc.jar WordCount*.class假定:
- /user/joe/wordcount/input - hdfs中的input文件夹
- /user/joe/wordcount/input - hdfs中的input文件夹
作为input的样例文本文件:
$ bin/hadoop fs -ls /user/joe/wordcount/input/
/user/joe/wordcount/input/file01
/user/joe/wordcount/input/file02
$ bin/hadoop fs -cat /user/joe/wordcount/input/file01
Hello World Bye World
$ bin/hadoop fs -cat /user/joe/wordcount/input/file02
Hello Hadoop Goodbye Hadoop运行程序:
$ bin/hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output
测试结果:
[hadoop@hadoop ~]$ hadoop jar wc.jar mvn.mvnsample.WordCount wordcount/input wordcount/output
17/11/02 12:18:10 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/11/02 12:18:53 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/11/02 12:18:55 INFO input.FileInputFormat: Total input paths to process : 2
17/11/02 12:18:56 INFO mapreduce.JobSubmitter: number of splits:2
17/11/02 12:18:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1509592542822_0002
17/11/02 12:19:49 INFO impl.YarnClientImpl: Submitted application application_1509592542822_0002
17/11/02 12:21:20 INFO mapreduce.Job: The url to track the job: http://hadoop:8088/proxy/application_1509592542822_0002/
17/11/02 12:21:20 INFO mapreduce.Job: Running job: job_1509592542822_0002
17/11/02 12:22:52 INFO mapreduce.Job: Job job_1509592542822_0002 running in uber mode : false
17/11/02 12:22:53 INFO mapreduce.Job: map 0% reduce 0%
17/11/02 12:24:32 INFO mapreduce.Job: map 100% reduce 0%
17/11/02 12:26:05 INFO mapreduce.Job: map 100% reduce 100%
17/11/02 12:27:37 INFO mapreduce.Job: Job job_1509592542822_0002 completed successfully
17/11/02 12:27:39 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=79
FILE: Number of bytes written=362146
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=292
HDFS: Number of bytes written=41
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=203474
Total time spent by all reduces in occupied slots (ms)=87282
Total time spent by all map tasks (ms)=203474
Total time spent by all reduce tasks (ms)=87282
Total vcore-milliseconds taken by all map tasks=203474
Total vcore-milliseconds taken by all reduce tasks=87282
Total megabyte-milliseconds taken by all map tasks=208357376
Total megabyte-milliseconds taken by all reduce tasks=89376768
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=82
Map output materialized bytes=85
Input split bytes=242
Combine input records=8
Combine output records=6
Reduce input groups=5
Reduce shuffle bytes=85
Reduce input records=6
Reduce output records=5
Spilled Records=12
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1551
CPU time spent (ms)=11070
Physical memory (bytes) snapshot=644284416
Virtual memory (bytes) snapshot=6374944768
Total committed heap usage (bytes)=449314816
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=50
File Output Format Counters
Bytes Written=41输出:
$ bin/hadoop fs -cat /user/joe/wordcount/output/part-r-00000
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2程序能通过使用“-files”选项指定一个逗号分隔的目录清单,这些目录存在于当前任务的工作目录。“-libjars”选项允许程序增加jar包到maps和reduces的classpaths中。“-archives”允许把逗号分隔的archives清单作为参数。这些档案是解压的,在当前任务的工作目录中建立有这个档案名字的链接。
使用-libjars,-files,-archives运行wordcount样例程序:
bin/hadoop jar hadoop-mapreduce-examples-<ver>.jar wordcount -files cachefile.txt -libjars mylib.jar -archives myarchive.zip input output这里,会生成myarchive.zip,解压成myarchive.zip文件夹。
用户可以通过-files和-archives选项、使用#为文件和档案指定一个不同的符号名称。比如:
bin/hadoop jar hadoop-mapreduce-examples-<ver>.jar wordcount -files dir1/dict.txt#dict1,dir2/dict.txt#dict2 -archives mytar.tgz#tgzdir input output这里dir1/dict.txt和dir2/dict.txt可以被任务通过相应地使用符号名称dict1和dict2来访问。会生成mytar.tgz档案,并解压成tgzdir名字的文件夹。
3. walk-through
wordcount应用是非常直接的:
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}通过map方法实现mapper,一次处理由指定的TextInputFormat提供的一行。然后通过StringTokenizer把这行分解成有空格分隔的tokens,然后产生一个key-value对< < word >, 1>。
对应给定的输入样例,第一个map产生:
< Hello, 1>
< World, 1>
< Bye, 1>
< World, 1>
第二个map产生:
< Hello, 1>
< Hadoop, 1>
< Goodbye, 1>
< Hadoop, 1>
我们会稍后学习更多关于一个给定的job会产生maps的数量,和如何用一种条理清晰的方式控制它们。
job.setCombinerClass(IntSumReducer.class); wordcount也指定一个combiner,这样每个map的输出在按key被排序后,会通过local combiner()做local aggregation。
第一个map的输出:
< Bye, 1>
< Hello, 1>
< World, 2>
第二个map的输出:
< Goodbye, 1>
< Hadoop, 2>
< Hello, 1>
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}通过reduce方法实现reducer,计算出每个key(就是该例中的words)出现的次数值。
这样这个job的输出是:
< Bye, 1>
< Goodbye, 1>
< Hadoop, 2>
< Hello, 2>
< World, 2>
main方法指定这个job的很多面,比如input/output路径(通过命令行传递),key/value类型,input/output格式等等。然后调用job.waitForCompletion来提交job,并监控他的进度。
我们稍后学习更多关于job、InputFormat、OutputFormat、其他接口和类。
4. mapreduce 用户接口
这部分提供合理的细节,这个细节是关于MapReduce框架中每个直面用户的方面。这会有助于用户条理清晰地实现、配置和调试他们的jobs。但是,请注意每个类、接口的javadoc仍然是可用的最全面的文档。这部分只是一个指南。
让我首先看下mapper和reducer接口。典型情况下程序实现它们来提供map和reduce方法。
我们接下来讨论其他核心接口包括Job,Partitioner,InputFormat,OutputFormat等等。
最后我们通过讨论一些框架中有用的特色,比如DistributedCache,IsolationRunner等,来做个总结。
1. payload
典型情况下程序实现mapper和reducer接口来提供map和reduce方法。以下构成job的核心。
1. mapper
mapper把key/value输入映射成一套中间的key/value。
maps是单独的任务,把输入记录转化成中间记录。转化过的中间记录不需要和输入记录具有相同的类型。一个给定的输入对会映射成0个或者很多输出对。
hadoop MapReduce框架为由job的InputFormat产生的每个inputSplit生成一个map任务。
整体上,mapper实现通过Job.setMapperClass(Class) 方法传递给job。然后框架为任务的inputSplit中的每个key/value对调用map(WritableComparable, Writable, Context)方法。然后程序覆盖cleanup(Context) 方法来执行任何需要的cleanup。
输出对需要和输入对有相同的类型。一个给定的输入对会映射成0个或者很多输出对。调用context.write(WritableComparable, Writable)来收集输出对。
程序可以使用Counter来报告统计数据。
一个给定的输出对相应的所有中间值随后被框架分组,传递给Reducer来决定最后的输出。用户可以通过Job.setGroupingComparatorClass(Class)指定一个Comparator来控制分组。
mapper输出排序后,按reducer分区。分区的数量和job的reduce任务数量一样。用户可以通过实现自定义的partitioner控制哪些keys去哪些reducer。
中间的、排序后的输出总是以简单的(key-len,key,value-len,value)格式存储。程序可以控制是否、如何压缩中间输出,通过configuration使用CompressionCodec。
1. how many maps
maps的数量通过由inputs的总量大小驱动,也就是input文件的总block数量。
虽然被设置成每个轻型cpu的map任务300maps,maps并行的最好级别大概是每个节点10-100maps。任务设置需要一点时间,所以最好是maps至少执行1分钟。
因此,如果你预计输入文件为10TB和blocksize为128MB,你会用到8.2万maps,除非Configuration.set(MRJobConfig.NUM_MAPS, int) 被设置的更高。
2. reducer
reducer分解一系列中间值,这些中间值把一个key分享给一小系列的值。
job中reduces的数量通过Job.setNumReduceTasks(int)来设定。
总的来说,通过 Job.setReducerClass(Class) 方法把reducer实现传递给job,reducer的实现重载job初始化自己。然后框架为经过分组的输入中每个< key,(list of values) >调用reduce(WritableComparable, Iterable, Context)方法。程序然后重载cleanup(Context)方法执行需要的cleanup。
reducer有三个主阶段:shuffle(洗牌),sort和reduce。
1. shuffle
reducer的输入是排序后的mappers输出。在这个阶段框架通过http取回所有mappers的输出的相关分区。
2. sort
在这个阶段,框架按keys(因为不同的mapper有着相同的key)将reducer 输入分组。
shuffle和sort阶段同时出现,当map输出取回的同时,他们就合并了。
3. secondary sort
如果将中间值分组的规则和将reduction之前值分组的规则不同,就需要通过Job.setSortComparatorClass(Class)制定一个comparator。由于Job.setGroupingComparatorClass(Class) 可以用来控制如何分组中间值,这些可以联合用在模拟针对值的第二次排序。
4. reduce
在这个阶段, 在分组的输入中为每个
3. partitioner
partitioner对key空间进行分区。
partitioner控制着中间的map输出的keys的分区。key(或者key的子集)用来获得partition,特别是hash功能。partition 的总数和reduce任务的数量一致。这样就控制着中间值(和记录)会送给那个m reduce任务来进行reduction。
HashPartitioner是默认的partitioner。
4. counter
counter用于MapReduce程序报告它的统计资源。
mapper和reducer的实现可以用counter来报告统计资料。
hadoop MapReduce附带普遍有用的mappers、reducers和partitioners库。
2. job configuration
job代表MapReduce job配置。
job是用户描述hadoop框架执行MapReduce job的主要接口。框架尝试着如实地按job描述的那样执行job,但是:
- 一些配置参数被管理员标记为final,因此无法被更改。
- 尽管有些job参数(比如Job.setNumReduceTasks(int))直接就可以设置,然而其他参数巧妙地和框架的其他部分和job配置交互,是很难设置的(比如Configuration.set(JobContext.NUM_MAPS, int))。
典型情况下,job用来指定mapper、combiner(如果有的话)、partitioner、reducer、InputFormat、OutputFormat实现。fileinputformat表明input文件的设置(FileInputFormat.setInputPaths(Job, Path…)/ FileInputFormat.addInputPath(Job, Path))和(FileInputFormat.setInputPaths(Job, String…)/ FileInputFormat.addInputPaths(Job, String)) 和output文件输出的位置(FileOutputFormat.setOutputPath(Path))。
有时job也用来指定job一些其他高级的方面比如使用的comparator、要放入DistributedCache中的文件、中间或者job输出是否压缩(以及如何)、job任务是否以一种推测的方式执行(setMapSpeculativeExecution(boolean))/ setReduceSpeculativeExecution(boolean))、每个任务尝试的最大次数(setMaxMapAttempts(int)/ setMaxReduceAttempts(int))等等。
当然,用户可以使用 Configuration.set(String, String)/ Configuration.get(String) 来设置/获取程序需要的任意参数。无论如何,为海量(只读)数据使用DistributedCache。
3. Task Execution & Environment
MRAppMaster执行mapper/reducer任务时作为子进程在独立的jvm中进行。
子任务继承了父MRAPPMaster的环境。用户可以通过mapreduce.{map|reduce}.java.opts给子jvm指定额外的选项, 指定job中的配置参数比如通过 -Djava.library.path=<>设置运行时linker用于搜寻共享库的非标准路径。如果 mapreduce.{map|reduce}.java.opts 参数包含@taskid@符号,它表示插入MapReduce任务的taskid值。
以下是一个例子,有很多参数和替代,展示jvm gc logging,开启一个无密码的jvm jmx客户端以便能够连接jconsole,the likes to 观测子内存、线程,得到thread dumps。还设置了map和reduce 子JVM的最大heap-size为512MB和1024MB。还增加了子jvm的java.library.path额外路径。
<property>
<name>mapreduce.map.java.opts</name>
<value>
-Xmx512M -Djava.library.path=/home/mycompany/lib -verbose:gc -Xloggc:/tmp/@taskid@.gc
-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>
-Xmx1024M -Djava.library.path=/home/mycompany/lib -verbose:gc -Xloggc:/tmp/@taskid@.gc
-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
</value>
</property>memory management
用户、管理员可以通过mapreduce.{map|reduce}.memory.mb指定启动的子任务和递归地启动的子进程的最大虚拟内存。注意这里设置的值是每个进程的极限值。mapreduce.{map|reduce}.memory.mb的值以(mega bytes)MB为单位。而且值必须大于或等于赋给JavaVM的-Xmx,否则vm将无法启动。
注意: mapreduce.{map|reduce}.java.opts 用来配置已经启动的来自MRAppMaster的子任务。为守护进程配置内存选项在“Configuring the Environment of the Hadoop Daemons”中说明。
一些框架部分的内存可用情况也是可以配置的。在map和reduce任务中,调节影响并发操作的参数和数据命中磁盘的频率会影响性能。监测文件系统一个job(特别是从map到reduce的相关字节数)的counters对于调试这些参数是非常重要的。
map parameters
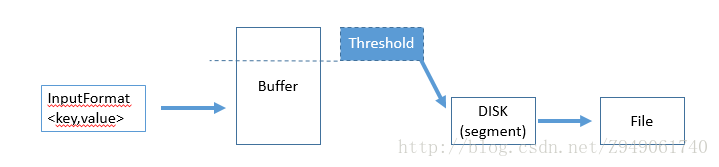
shuffle/reduce parameters
configured parameters
task logs
distributing library
4. Job Submission and Monitoring
job control
5.job input
inputsplit
recordreader
5.job output
6.other useful features
Example: wordcount v2.0
在显示< word >时有个坑:word和<>之间需要有空格,否则就不会显示出来。














 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









