







Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下:
1、独立模式即本地运行模式(standalone或local mode)
无需运行任何守护进程(daemon),所有程序都在 单个JVM上 执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
2、伪分布运行模式
1、独立模式即本地运行模式(standalone或local mode)
无需运行任何守护进程(daemon),所有程序都在 单个JVM上 执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
2、伪分布运行模式
伪分布:如果Hadoop对应的Java进程都运行在一个物理机器上,称为伪分布运行模式,如下图所示:
[root@hadoop20 dir2]# jps
8993 Jps
7409 SecondaryNameNode
7142 NameNode
7260 DataNode
8685 NodeManager
8590 ResourceManager3、集群模式
如果Hadoop对应的Java进程运行在 多台物理机器上 ,称为集群模式.[集群就是有主有从] ,如下图所示:[root@hadoop11 local]# jps
18046 NameNode
30927 Jps
18225 SecondaryNameNode[root@hadoop22 ~]# jps
9741 ResourceManager
16569 Jps[root@hadoop33 ~]# jps
12775 DataNode
20189 Jps
12653 NodeManager[root@hadoop44 ~]# jps
10111 DataNode
17519 Jps
9988 NodeManager[root@hadoop55 ~]# jps
11563 NodeManager
11686 DataNode
19078 Jps[root@hadoop66 ~]# jps
10682 DataNode
10560 NodeManager
18085 Jps注意:伪分布模式就是在一台服务器上面模拟集群环境,但仅仅是机器数量少,其通信机制与运行过程与真正的集群模式是一样的,hadoop的伪分布运行模式可以看做是集群运行模式的特殊情况。
为了方便文章的后续说明,先介绍一下hadoop的体系结构:
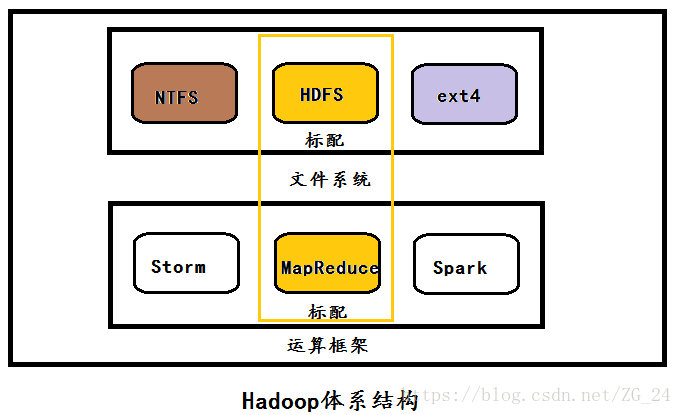
从Hadoop的体系结构可以看出,HDFS与MapReduce分别是Hadoop的标配文件系统与标配计算框架,但是呢?–我们完全可以选择别的文件系统(如Windows的NTFS,Linux的ext4)与别的计算框架(如spark、storm等)为Hadoop所服务,这恰恰说明了hadoop的松耦合性。在hadoop的配置文件中,我们是通过core-site.xml这个配置文件指定所用的文件系统的。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop11:9000</value>














 3350
3350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









