







这套笔记是我去年刚接触C++时整理的笔记,有几课的内容没有记录。希望能给初学C++的你带来一些帮助。
FM是浙大很棒的老师,虽然我OOP没能选上他的课,但是好在有公开课可以弥补一下遗憾(ง •̀_•́)ง
课程地址:http://study.163.com/course/courseMain.htm?courseId=271005
怎样能开始写 C++程序?和 C 程序不一样,我们需要在编译器里建立一个项目(工程),
然后再在这个项目底下写自己的.h,对应的.cpp 以及 main.cpp。
【非常重要所以放在开头】
在 C++学习中,一定要区分的两个概念:
声明与定义,初始化与赋值。
【C++ 内存模型】
函数参数如果是指针或引用,那么就是将地址压栈。详情可看后续内联函数这一讲。
2.堆区:仅存放动态内存,也就是 new 出来的东西
3.全局数据区:全局变量,静态本地变量,静态成员变量;
//如果用%p 输出存放在全局数据区数据的地址,会发现它是一个非常小的地址
--代码段:字符常量,字符串常量 //保护不可写
//const:是否创建内存空间取决于具体操作。比如用 extern,或者将其传给一个带引用参数的函数,就会分配内存空间。否则只会在编译时刻将其放到符号表里,而在实际运行中不会创建内存空间。
C++最复杂的就是它有如此多的内存模型,第一点体现在它提供了太多你可以存放数据的地方,第二点体现在它提供了太多可以访问内存的方式。而 JAVA 就非常简单,所有的数据都是按指针来传递的。
【前面几节课在讲面向对象哲学,没有记录】
【课时 5 头文件 课程内容概述】
类的定义:
在 C++中,分别使用.h 和.cpp 来定义一个类。
.h 中存放类的声明,函数原型(放在类的声明中)。
.cpp 存放函数体。
也就是说,一个存放声明(declaration),一个存放定义(definition)。
如果我们在一个头文件里声明了一个函数,当我们需要定义这个函数(这个定义是唯一的,也就是只能定义一次),或者需要使用这个函数时,我们在 cpp 中需要 include 这个头文件。
同样地,如果我们在一个头文件里声明了一个类,当我们需要定义类里的成员函数,或者我们需要使用这个类时,我们在 cpp 中需要 include 这个头文件。
对于类的设计者来说,头文件就像他们和类的使用者的一个合同,编译器会强化这一合同,它会要求你在使用这些类里的函数或结构时必须要声明。
C++程序结构
#include 是一个编译预处理指令,它并不是编译器做的事情,更准确来说是另外一个程序做的事情,那个程序在 cpp 文件中找到所有#开头的指令,然后执行对应的命令。对于#include 来说,它会找到对应的头文件,然后把它们全部放到.cpp 文件的前面,形成一个大的编译前用的文件。
/ *
以下是涉及到 linux 终端的一些操作:
编译预处理指令 cpp,和 C++的 CPP 有别。
g++ a.cpp --save-temps,保存编译过程中的中间过程文件。
g++ -m32 a.cpp 在 32 位操作系统下编译
编译完成后,产生如下文件:
a.cpp
a.h
a.ii // 编译预处理指令结束后产生的文件
a.o // 目标代码
a.s // 汇编代码
a.out // 最终可执行的程序
在终端,可以同时编译多个 cpp,如 g++ a.cpp b.cpp。
c++编译器会将我们定义的所有名字都加上下划线。它在机器语言中用的名字和我们使
用的名字是不一样的。
*/
需要注意的是,在头文件中只能放声明。
如果我们在头文件中存放了一个定义,比如 int global,然后我们在 a.cpp 和 b.cpp 中都包含了这个头文件,然后一起编译,那么,预处理器首先会把头文件的内容拷贝到 a.cpp 的开头,然后产生汇编代码(编译器)以及目标代码(汇编器),接下来再对 b.cpp 做同样的事情,最后一步需要把 a.o 和 b.o 连起来(Linker)产生我们最终需要的 a.out 可执行文件。
前面几步都是可以正确执行的,因为对两个 cpp 文件是分开操作的,所以不会产生冲突,但是在最后一步连接时就会出现问题。根据预处理的特性,我们发现 a.o 和 b.o 里都会有global 这个变量的定义(因为被预处理器放到开头了),所以就产生了重复定义。
那么,我们如果希望这只是一个声明,可以引入关键字 extern:
extern int global;
当然,这也就意味着,我们在.cpp 文件中还需要定义一遍这个 global,否则也会出错(找不到变量)。
不过,如果我们并不需要使用这个变量的话,我们也没有必要定义这个变量了。
总结
总结一下,我们在头文件一般放这三种类型的东西:
1.extern 变量
2.类(结构体)的声明 // 不存在类(结构体)的定义
3.函数声明 // 函数原型就是声明,无需 extern
cpp 可以包含头文件,一个头文件也可以包含另一个头文件。
有两种形式的 include.
#include"....."优先在当前文件夹寻找。
#include<....>在系统目录文件范围寻找。
// 去掉.h 保证 C++风格
在.h 文件中,自动生成预处理指令:
#ifndef ???
#define ???
……
#endif
是一种保护措施,防止重复声明。
// 变量可以重复声明,但是类不可以重复声明
【课时 7,8 成员变量 课程内容概述】
本地变量和成员变量重名,成员变量被屏蔽。
成员变量(field):定义在类所有函数和构造函数之外,作用域(对象生存期):类的作用域,在整个类的所有函数都可以直接使用所有的成员变量
本地变量(local variables):作用域:函数内部
函数参数(parameters):和本地变量具有相同的属性
成员变量存储位置
那么,成员变量究竟在哪里?
它并不在类里,而是在 main 函数中我们定义它的地方。在 main 中,我们定义了类 A的一个变量 a:
A a;
类 A 里的成员变量 i 就在这里产生。
我们知道当我们声明了一个变量,或者一个函数,在后面我们就需要给它一个定义。但是类却不存在这种现象,我们不需要额外地对类中的成员变量进行定义。// 先忽略静态的成员变量
事实上,如上文提及,在我们定义 A 类对象 a 的时候,就默认定义了类里的成员变量。
成员变量在类的每一个对象里。
深入理解成员变量与成员函数
只要有了声明,我们就可以自由使用那些变量。比如有了全局变量的声明或函数的声明,我们就可以使用它们,而不需要知道它们在哪里。同样地,对于成员函数来说,它们不需要知道成员变量在哪里,就可以直接使用已声明的成员变量。
类是虚的,它存放的只是声明,只有当我们定义了某个类的对象后它才能存在于那个对象中。就像结构体只是产生了一个构造数据类型,只有当我们定义了某个结构体的变量,结构体才是真实存在的(分配了内存空间),只不过我们常常会写结构体的同时就在结构体后面定义了它的变量。
对于 ClassA,在 main 函数里:
A a;
a.f();
a.f()的意思是:让 a 这个对象去做 A 的 f()那个动作。如果我们再定义类的其它对象,那么 f()也就可以对其它对象作用。所以我们说,f()成员函数是属于类 A 的,而不是属于对象的。它对不同的对象作用,而且知道自己是在对哪个对象作用。
同时,我们又说 class A 里的成员变量是对象 a 的,因为对于不同的对象,它们都会各自拥有一个独立的成员变量,比如对于成员变量 i,a.i 和 b.i 事实上是完全不相关的。
总之,对于同一个类的不同对象来说,函数是公共的,而变量是私有的。
this 关键字
那么,成员函数是如何区分是哪个对象在调用它呢?事实上,C++的代码就是由 C 编写而来的,也就是说,每个 C++代码都可以恢复成 C 的代码。那么,对于成员函数来说,它是通过怎样的 C 代码来识别不同的对象呢?
通过一个测试,我们发现,成员函数事实上获得了对象中变量的指针。它们之间是存在某种联系的,这种联系的建立,就叫做 this。
所有的成员函数都有一个隐藏的变量,this。它是函数所属的类的对象的指针。
事实上,我们可以理解为,所有的成员函数都传入了 this 指针,然后在函数内部的所有成员变量之前都有 this->符号。
/ *
C++的一个很好的学习方法:思考 C++这个特性在 C 语言中是如何实现的。如果能够想明白,那么对 C++的理解就很到位了。
* /
【课时 9,10 构造与析构 课程内容概述】
我们在写一个类的时候,需要考虑到变量的初始化,我们不能认为没有初始化的变量的值就会是 0。因为 C++是追求效率的语言,所以不会为你做变量赋初值的事情,这一切需要你自己完成。
我们需要用构造函数来保证变量已经被初始化了。
class X{
public:
X();
~X();
}
它的名字和类的名字是相同的,也没有任何返回类型(注意是没有,不是 void),它会在这个对象被创建的时候自动被调用。当然,构造函数可以有参数,在我们在 main 里定义类的对象时,就需要用圆括号传递一个参数。
Tree t(12);
同时,我们还具有析构函数。比构造函数多了一个波浪号~,它没有返回类型,也没有参数。在被析构前,也就是变量离开作用域的时候,析构函数将被调用。
编译器会在大括号开始的地方去分配在这个大括号里面出现的所有变量的空间。但是构造函数的调用要直到对象定义的地方才会发生。
如果构造函数没有参数,那么它就叫缺省构造函数(default constructor)。
如果我们使用了 goto,goto 可能跳过一个类对象的定义,那么编译也会报错,因为未来可能出现这样一种情况,跳过了定义,也就意味着跳过了构造函数,但是析构依旧会执行,这样是会出问题的。
/*
那么,我可不可以用构造函数但不做初始化呢,当然编译器不会报错,唯有你的道德和良心能够考验你的行为。
*/
【课时 11 new&delete 课程内容概述】
new
new int;
new int[10];
new Stash;//对于类,分配空间后,会调用构造函数
delete
delete p;
delete[] p;//对于数组要这样做
delete Stash;//对于类,先调用析构函数,再释放空间
new 之后的对象都存放在堆里。C++运行库帮我们完成这件事情,当我们申请不多的空间时,是不需要向操作系统要内存的,因为系统一开始就分配了一定的内存,这些内存就足以供运行库分配了。
int *psome = new int [10];
delete []psome;
这个方括号表示要释放的对象不是只有一个,而是有很多个。编译器就会保证很多个对象的析构都会被调用。如果不带方括号,空间还是会被回收,但是析构只有第一个对象会调用。
这时候 psome 就指向了堆里那个分配好的内存,同时会有一张表记录下你申请了这块内存,以及你这块内存的首地址,有多大(以字节计算)。
当我们要 delete psome 时,它在表中查找 psome 指向内存的大小,然后收回。如果我们在 delete 前执行了 psome++操作,那么这时候编译器就找不到 psome 开头的内存,就会出错。
delete 一个空内存,是不会出错的。因为 delete 会判断指针指向是否会空,如果为空,就不执行操作。这样的机制为我们写程序提供了一些方便,当我们无法确定一个指针是否指向了某处内存,使用 delete 就不会出错。当然,更稳妥的选择依旧是 if(p)delete p。
/*
对于一个小的程序,像我们的作业,不用 delete 是不会出问题的,因为一旦运行结束,内存就会被回收。但是对于那些一直运行的程序,比如我们手机上的应用,它们甚至可能是不会关闭的,如果没有 delete 的话就会出现内存泄露问题。所以我们要从平时养成 delete的习惯。
*/
【课时 12 访问控制 课程内容概述】
Public:公开的,所有人都可以访问
Private:只有类的成员函数可以访问
Protected:只有类以及其子类的成员函数可以访问
同一个类的对象是可以互相访问私有成员的变量的。这种权限的限制仅仅在编译时刻。
C++的 OOP 特性只在源代码上体现,编译完以后就脱离 OOP 了。只要你能骗过编译器,在运行时你是可以把手伸向类的私有变量的。
friend
你可以声明别人是你的朋友,声明之后它就可以访问你的 private,别人可以是类,可以是函数,可以是类里的函数。当然你不能说你是别人的朋友,然后去访问别人的私有变量。
struct X;//前向声明
struct Y{
void f(X*);
};
//因为要用 X,所以要先声明,这是一种常用的策略。又因为后面 X 会使用到 Y,所以只做声明不做定义,不然会产生矛盾,在定义 X 时 Y 还没有出现。由于指针的大小是固定的,所以对于 Y 来说,我们不需要预先知道 X 是什么样的。当然如果这里的参数变成 X,就有问题了,因为这个时候编译器还不知道 X 的大小,这两个结构的关系就比较混乱了。
struct X{
private:
int i;
public:
void initialize();
friend void g(X*,int);//Global friend
friend void Y::f(X*);//struct memeber friend
friend struct Z;//entire struct is a friend
friend void h();
}
/*
在结构 Y 里用到了 X,如果在前面没有 X,编译器就会说我找不到 X,如果你在前面加
上一句 X 的声明,你就安抚了编译器,它就没有情绪了。
*/
在运算符重载时使用的会比较多。
当一个类已经写好的时候,就无法授权朋友了。
struct 和 class 的区别
C++中,struct 就是 class,唯一的区别是 struct 默认变量是公开的,而 class 默认变量是私有的。那么没有表明访问权限的变量的缺省是不一样。在 C++我们首选 Class。
【课时 13 初始化列表 课程内容概述】
初始化列表:在构造函数的圆括号后加上冒号,然后在后面写成员变量的名字,再用括号给出初始值:
A():i(0){ …… }
这和把句子写在大括号里是有区别的,初始化列表可以初始化任何类型的东西。那么构造器就不需要去做赋值这件事情了。这件事情(初始化)会早于构造函数的执行。
如果你的类的成员是一个对象,就会有所区别。
Student::Student(string s):name(s){ }
初始化
Student::Student(string s):{ name = s;}
赋值
第二种情况,因为初始化没有给 name 具体值,它会去找缺省构造函数来初始化,但如果你没有(缺省构造函数)的话,就会出问题。
/*
给大家一个建议,以后都用初始化列表来初始化,而不要在构造函数里做赋值。
*/
【课时 14 对象组合 课程内容概述】
OOP 的三大特性就是封装、继承和多态性。
继承是 OOP 对一件事情的回答:软件重用,或者说你的代码的重用。当然这件事情不是只有靠继承一个手段来解决的,但是 OOP 觉得继承是它可以实现软件重用的方式。
软件重用是一个梦想,从有软件开始,人们就开始梦想着软件有着各种程度上的重用。
到了 OOP,只能说我们找到了某些用来做软件重用的手段,但首先这不是唯一的手段,其次也不一定是最好的手段。
在 C++中,我们可以做的另外一种重用的方式是组合(composition)。我们用已有的对象来组合制造出新的对象。反映到 C++的代码,我们在设计一个类的时候,它的成员变量可以是另外一个类的对象。
但实际上在这种组合我们也可以有两种不同的方式。一种是 fully:那个别人的对象就是我这个对象的一部分,另一种是 by reference:那个别人的对象我知道它在哪里,我可以访问到它,但它并不是我身体内的一部分。
反映到 C++中,一个是成员变量就是对象本身,一个是成员变量是一个指针。
class Person{ ... };
class Currency{ ... };
class SavingsAccount{
public:
savingsAccount(const char *name,const char* address,int cents);
~savingsAccount();
void print();
private:
person m_saver;
currency m_balance;
};
在 SavingsAccount 中有两个其它对象的成员变量,而且是 fully inclusion。
当我们要去创建 SavingsAccount 的对象的时候,实际上我们就需要去初始化SavingsAccount,但是 person 和 currency 是有自己的构造函数的。别人的对象的内存该怎
么初始化?
在 C++中,我们应该遵循原来有的规则,所以得让它们自己初始化自己,自己去管理自己。
我们的 SavingsAccount 的构造函数应该长成这样:
SavingsAccount::SavingsAccount(const char* name,const char* address,intcents):m_saver(name,address),m_balance(0,cents) { }
void SavingsAccount::print(){
m_saver.print( );
m_balance.print( );
}
我组合进来的对象仍然具有独立的人格,我们应该遵循它们原有的规则,我们仍然不能随心所欲的去使用它们。所以在上面代码中我们不是直接 cout 结果,而是调用原来类的print 函数来做这件事情。
我们在给类中别的类的对象初始化的时候应该使用初始化列表。
前面的代码我们把别的类的对象做成了 private。我们把它做成 public,这就违背了oop 的原则,我们就让数据接触到了外界。
【课时 15 继承 课程内容概述】
继承是另外一种途径,拿已有的类,在这个类的基础上做一点改造,然后再做成新的类。
一个类的接口是它对外公开的部分,如果你从一个类继承,那么就可以共享它的成员变量,成员函数和接口。
对于类:person 和类:student,student 继承了 person,person 是 student 的父集,student 是 person 的超集。因为学生相比起人,有了更多属性。
class A{
int i;
public:
A():i(0){ cout<<"A::A()"<< endl;}
~A( ):{ cout<<"A::~A()"<<endl; }
void print( ){ cout<<"A::f( )"<<i<<endl;}
proteced:
void set(int ii){ i=ii; }
}
class B:public A{ //表明继承的写法
public:
void f( ){
set(20);
//! i=30
print( );
}
};
当你继承一个父类时,那个父类的所有东西你都有了。
父类私有的东西是存在的,但是,你不能碰,或者说你不能直接去修改私有的变量,你只能通过一定的规则使用它。
我们让我们所有数据都是 private 的,我们仍然坚持这一事情,哪怕是我们的儿子都不会去碰这些 private 的数据,然后我们会让那些真正要给所有人的东西是 public 的,当然所有人也包括我们的儿子。但是,我们会留一些 protected 的接口给子类,是告诉子类你可以用 protected 的东西来访问一些 private 的东西,这些手段只留给你,别人不能做。
【课时 16 子类父类关系 课程内容概述】
当我们构造一个子类的对象时,它的父类的构造函数是会被调用的。如果 B 类继承了 A类,A 类的构造函数需要一个参数,那么我们就必须这样写 B 的构造函数:
B():A(15){ }
父类的构造函数的初始化必须在初始化列表中,父类的构造会先于子类的构造。同时,父类的析构也会晚于子类的析构。
::这是一个解析符,表示这个是哪个类的函数。
如果子类出现了和父类完全一样的函数(函数名和参数都一样),那么就会出现名字隐藏现象。也就是说父类的是所有函数都被隐藏了。只有 C++语言是这么做的,其它 OOP 语言都是替换现象。这和 C++另外一件事也是只有它这么做有关,
【课时 17 函数重载和默认参数 课程内容概述】
函数名相同参数表不同的函数构成了函数重载。
只有返回类型不同不能构成重载。
可以在函数的参数表里预先给参数一个值:
Stash(int size,int initQuantity=0)
如果只给一个值,那么就会调用那个预先给的值。这个缺省值(default argument)必须从参数表的最右边开始写起。这个值是写在.h 里的,而且不能在.cpp 里重复这件事情。
缺省值是编译时刻的事情,那个函数还是要多个参数的,不是因为有了 default argument 就出现了函数重载,编译器只是替你补上了那个值。
/*
我给大家的建议,不要使用 default value,在软件工程中是不提倡的,它会造成你阅
读上的困难,而且它很不安全,它不一定是设计者的意图,它是可以修改的。
*/
【课时 18 内联函数 课程内容概述】
当我们去调一个函数的时候,实际上我们是有一些额外的开销的。
Push parameters
Push return address
Prepare return values
Pop all pushed
//真实的函数调用的堆栈是从顶往下走的
C++提供了内联函数,我们把那个函数的代码嵌入到调用它的地方,但是仍然保持函数的独立性,这样就避免了额外的开销。
如果你说一个函数是内联的,那么它就不会出现在最终的可执行程序中,它只会出现在编译过程中。
我们需要把函数的 body 放到 a.h 里,加上 inline 就相当于声明而不是定义了。
它会牺牲代码的空间(因为函数里的变量在离开后不会摧毁),但是赢得了时间(避免了额外的开销操作)。
【课时 19 const 课程内容概述】
const int bufsize= 1024; //初始化后就不能再赋值了
常量必须要初始化,除非你强调它是一个声明:
extern const int bufsize;
但是要注意的是,对于 C++来说,它仍然是变量,而不是常数。变量意味着编译器还是会为其分配内存空间的,而常量意味着编译器在编译过程中将其记录在内存表里。它也遵循参数传递那些规则。
C++的一切东西都是骗人的,也不是骗人的,一切东西都是编译器在搞鬼。这个 const并不是运行时刻有一个机制来保证它是 const,只是编译器去保证说,你说它是 const,那么我就保证你永远不会去修改它。至于它是不是真的是 const 这是两回事。
表示数组大小
const int class_size=12;
int finalGrade[class_size]; // ok
int x;
cin >> x;
const int size = x;
double classAverage[size]; // error!
第二种情况,编译器不知道在编译时刻不知道 size 的值,所以无法在编译时刻为数组分配内存。
同样,extern 也是不可以用来定义数组的大小的。
指针与 const
有两种情况,一个是 const 在*前,一个是 const 在*后。
char *const p = “abc”; //指针常量
const char *p = “abc”; //常量指针(指向常量的指针)
char const *p = “abc”; //也是常量指针
指针常量的地址是固定的,我们不可以修改它的地址,不能做 p++。
数组就是一个指针常量,一开始编译器就为它分配了一块固定的内存,我们可以修改数组里的元素,但是不能修改数组的地址,不能让它指向别的一块内存。否则就会出现
Segmentation fault。
/*
当然不能简单地将数组看做指针常量,详情可以看
http://blog.csdn.net/ztj111/article/details/1965341
*/
常量指针。也就是说不能通过*p 来修改那块内存,但可以做 p++,p++之后它的下一块内存单元又变成 const 了。而不是说,我指到哪里,那块内存单元就变成 const 了,它本身并不是 const,也就是说通过自己修改自己是被允许的。
int * ip;
const int *cip;
int i;
ip = &i;
cip = &i;
const int ci=3;
ip = &ci; //error
cip = &ci;
可以把常量赋给常量指针,但不能赋给普通指针。
一般变量可以赋给普通指针,也可以赋给常量指针。
字符串与字符数组
字符串常量:
char *s = “hello wolrd”;//s 在堆栈里,它指向内存里全局变量区的代码段
s[0]=‘B’;//warning:试图修改常量 + 段错误
字符数组:
char s[]=“hello world”;//s 在堆栈里,它把全局变量区的常量拷贝到数组里
s[0]=‘B’;//ok
常量与参数,返回值
void f(const int* x);
可以传常量,也可以传普通变量:
int a = 15;
f(&a); //ok
const int b = a;
f(&b); //ok
b = a + 1; //Error!不能对其所指的变量做修改
const int f(){ return 1; }
返回的常量可以赋值给常量(尚未初始化),也可以赋值给一普通变量:
const int j = f( ); //ok
int i = f( ); //ok
传整个对象进函数,会耗费很大,如果你能够传地址,就会省很多,但如果没有 const,你就不放心它会不会修改你的变量。所以传入 const 的指针可以保证你的变量是安全的。
【课时 20 不可修改的对象 课程内容概述】
常量成员函数
成员变量不能被修改。
常量成员函数对常量对象是安全的,意味着 this 是 const 的。
int Date::set_day ( int d ){
day = d; // ok, non-const so can modify
}
int Date::get_day ( ) const {
day++; //Error:modifies data member
Set_day(12); //Error calss non-const member
return day; //ok
}
注意:在原型和定义处都要加 const。
class A{
public:
A( ): i(0){ }
void f( ) { } //参数表:A * this
void f( ) const { } //参数表:const A* this
};
int main( )
{
const A a;
a.f( );
return 0;
}
上面函数中,f()const 会运行,而 f()不运行。这两个函数构成了重载关系。
const 成员变量
class A{
const int i;
};
需要在初始化列表给 i 初始化。
如果有成员变量是 const,不能用其做数组下标:
class HasArray{
const int size;
int array[size];//Error
};
//应该加入 static,这个在后面会继续讲
另一种修改:
class HasArray{
enum{ size = 100 };
int array[size]; //ok
}
【课时 21 引用 课程内容概述】
char c; // a character
char* p = &c; // a pointer to a character
char& r = c; // a reference to a character
一般引用定义时都要初始化,建立了一个绑定的关系。
字面可以理解为,r 是 c 的一个别名。使用 r,就是在使用 c。
在参数表和成员变量里,引用不需要初始化。成员变量是在构造对象的时候初始化,函数是在传参数的时候初始化。
void f(int& x);
f(y);
这里面的 x 就是外面的 y。
const int&z = x;
z 是 x 的一个别名,这件事情是永远无法改变的。这里的 const 是指,不能通过 z 修改x,这和 const 的指针是一样的。z 是不能做左值的,但是可以改变 x,z 的值也会改变。
func(i*3); // Error
i*3 有结果,但没有位置,没有一个变量去存放它,或者说没有一个有名字的变量去存放它,而只有一个匿名的临时变量来存放它,所有它不可能送到函数内部让其被绑定。
int* f( int* x ) {
(*x)++;
return x; //Safe, x is outside this scope
}
int& g(int& x){
x++; // Same effects as in f( )
return x; // Safe, outside this scope
}
int x;
int& h( ){
int q;
//! return q; //Error
return x; // Safe,x lives outside the scope
}
int main( ){
int a = 0;
f(&a); //Ugly ,but explicit
g(a); //Clean , but hidden
h( )=16; //可以做左值
*k( )=10;
}
做左值的话,没有任何人拿到 x 的 reference,我们至今拿 x 的 reference 来赋值。
int g(int x)是不能和 int& g(int& x)形成重载的。
事实上,引用就是用指针实现的。
int x;
int &a = x;
int &b = a; // Error!
int &c = y;
&a = &c; //x = y
我们没有办法从代码上看出引用的地址、值,我们看到的都是它所捆绑的对象相应的值,
换句话说,reference 的地址是我们取不到的。
int &* p; // illegal
int* & p; //ok
前者,我们无法取得引用的地址,所以是错的(在这里,*p 是引用别名,那么 p 就是引用的地址)。后者,p 是引用,它所捆着的那个变量是指针。离变量最近的那个决定了它的基本类型。
既然 reference 不是一个实体,那么也就没有 reference 的数组。
【课时 22 向上造型 课程内容概述】
如果说,D 类是 B 类派生出来的。那么:
D -> B
D* -> B*
D& -> B&
这个也就是说,如果 B 是 D 的一个子类,那么 B 的对象就可以被当做 D 的对象来看待,就可以当做 D 的对象来使用,为什么可以?因为,从内容来说,我们知道,从那个对象的内部的结构来看,一个子类的对象具有父类的对象的所有东西。
然后,就外观来说,我们知道,子类继承了父类。那父类所有的 public 的东西子类都有,而且也是 public 的。因此,你对一个子类的对象,把它当做父类的对象来用,调用父类所具有的所有的那些函数,它都能接受。
/*
那多出来的东西呢?
多出来的东西你就当他不存在咯,比如说你是一个学生,同时你也是一个人,我不拿你
当学生看,就拿你当人看,没问题啊。
*/
class A{
public:
int i;
A():i(10) { }
};
class B:public A{
};
int main( )
{
A a;
B b;
cout << a.i <<“ ”<<b.i<<endl;
cout << sizeof(a) <<“”<<sizeof(b)<<endl;
int *p = (int*)&a;
cout<<p<<“ ”<<*p<<endl;
p=(int*)&b;
cout<<p<<“ ”<<*p<<endl;
return 0;
}
运行结果:
10 10
4 4
0x7fff57659fb0 10
0x7fff57659fb8 10
我们来试一下。我们看到两个 10,这是两个 i,两个 4 这是两个 sizeof,a 和 b 的大小是一样的。
这是 a 的地址,然后我们把它当做 int,它就给了我们 10。这是 b 的地址,它们当然不一样,这是两个不同的对象,你不能指望这两个相同,这两个相同就有问题了嘛。然后它也是 10。
当然我们也可以做更邪恶的事情,是这样的,既然我们拿到了那个地址,我们可以改嘛,我们可以赋值嘛。所以我们说*p = 20,在这个之后我们来看看 a.i 等于多少:
//我们真的很坏,有点丧心病狂了,我是想告诉你们 c++的一切都是骗你们的
运行结果:
20
//被我们改过来了。假的?你再看看我的代码,哪里假了?
然后我们还可以再试一件事情,我们给 B 加一个变量,既然有同学说这个事情,我们把它设为 private 好了:
class A{
public:
int i;
A():i(10) { }
};
class B:public A{
private:
int j;
public:
B():j(30){ }
void f( ) { cout << “B.j = ” << j << endl;
};
int main( )
{
A a;
B b;
cout << a.i <<“ ”<<b.i<<endl;
cout << sizeof(a) <<“”<<sizeof(b)<<endl;
int *p = (int*)&a;
cout<<p<<“ ”<<*p<<endl;
p=(int*)&b;
cout<<p<<“ ”<<*p<<endl;
p++;
*p = 50;
b.f( );
return 0;
}
运行结果
10 10
4 8
0x7fff5609cbf0 10
0x7fff5609cbe8 10
B.j = 50
当然我不是说你们要这么干,我这么干的目的只是为了告诉你们,你们其实可以知道那个对象的里面是怎样的,可以通过这些手段来知道对象里面是怎么样的。拿到指针以后你们就可以随心所欲,为所欲为了。
所以,为什么一个子类的对象可以被当做父类来看待,因为里面的数据结构是一样的。
子类虽然有新增加的部分,我这个 B 类对象里面实际上有两个东西,第一个是 int i,第二个是它自己的 int j,所以,当我们把它看做是一个父类的对象的时候,我从这个指针的角度看过来,它上面这个部分正好就是父类的对象,一点没错的。它增加的部分一定会是在后面的,不会在前面的。所以把它当父类来看待,所有的地址偏移全部是对的,然后函数还都是对的。它多出来的部分只不过被无视了而已。
把子类的对象当做父类来看待,这件事情我们叫做向上造型(upcasting)。与之对应的还有 downcasting,downcasting 是有风险的,而 upcasting 一定是安全的。
Manager pete(“Pete”,“444-55-6666”,“Bakery”);
Employee* ep = &pete; //upcast
Employee* er = pete; //upcast
【课时 23 多态性 课程内容概述】
Shape
class XYPos{...};
class Shape{
public:
Shape( );
virtual ~Shape( );
virtual void render ( );
void move (const XYPos&);
virtual void resize( );
protected:
XYpos center;
};
这个 virtual 意思是说,将来 shape 类的所有子类里面,如果它重新写了 render,参数表也一样,那么这个 render 和子类里的那个 render 就是有联系的。和前面我们看到的例子里没有关系的是不一样的。有了这个 virtual 才有了联系。
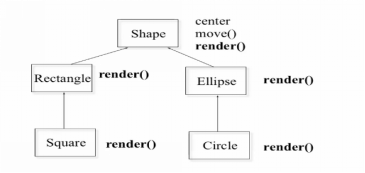
class Ellipse : public Shape{
public:
Ellipse(float maj, float minr);
virtual void render( ); //will define own
protected:
float major_axis, minos_axis;
};
class Circle : public Ellipse{
public:
Circle(float radius) : Ellipse(radius, radius){ }
virtual void render( );
};
你不加 virtual,它也依然是 virtual 的。只要在它的继承树里某个祖先说他是 virtual的,以后它的子子孙孙都是 virtual 了。但是,把它放在这里是一个好习惯,这样的话别人不用再去看 shape 了,看到你 ellipse 就知道这个是 virtual 的。
所以 ellipse 定义了一个自己的构造,没有自己的析构。定义了一个自己的 render,然后也说是 virtual 的。然后增加了 major_axis 和 minor_axis,长轴短轴。
Circle 是 ellipse 的一个特例,它也有自己的 render。
void render(Shape* p){
p->render( ); //calls correct render function for given shape
}
void func(){
Ellipse ell(10,20);
ell.render();
Circle circ(40);
Circ.render();
render(&ell);
render(&circ);
}
这个 render 函数是通用函数,对任何 shape 类的子类都是适用的,当然也包括 shape自己。也意味着这个 render 函数适用于将来的新出现的 shape 的子类的对象。
然后我们就可以做这样的事情。我们做了一个 ellipse 的对象 ell,如果我们说ell.render,这是 ellipse 的 render,然后我们说 circ.render,这也一定是 circle 的render,这个时候如果我们把 ell 的地址传入 render,这个时候发生的就是 upcast,我们把一个子类当做 shape 的对象看待了,那么是谁在 render?是 ellipse 而不再是 shape。因
为这个函数是 virtual 的,virtual 的函数就在告诉编译器说,对这个函数的调用,如果是通过指针,或者引用,你就不能相信它一定是什么类型,得要到运行的时候才能确定。这个指针所指的对象是什么类型,你就在调用那个类型的函数。
这件事情就叫做多态性(polymorphism),什么东西是多态的?p 就是多态的,有的地方就会把 p 叫做多态对象,因为 p 里面指了什么类型的对象,通过 p 做的动作就是那个类型的对象做的。
所以 p 指的是谁,它就变成那个东西的形态,这就是多态。
多态性是建立在两个事情的基础上,第一个基础叫做 upcast,第二个基础叫做动态绑定。绑定的意思是说,当我们去调一个函数的时候,我们究竟应该调哪个函数。其中静态绑定是说我调的那个函数是确定的,而动态绑定是到了运行的时候才知道我到底应该调用哪个函数。根据我指针所指的对象来决定。
【课时 24 多态的实现 课程内容概述】
一个类如果有虚函数,这个类的对象就会比正常的大一点。
class A{
public:
A():i(10){ }
virtual void f( ) { cout“A::f( )”<< i <<endl;}
int i;
};
int main()
{
A a;
a.f( );
cout<< sizeof(a) <<endl;
int *p = (int*)&a;
cout << *p <<endl;
}
结果:
A::f()10
8
835680
最后我们拿出的 p 的值,不是那个 10,我们再来做一点改变,我们在输出 p 之前加一句 p++:
结果是 10。
这说明什么?其实我们现在这个对象是这样的:上面有一个 int 大小的东西,不知道是什么,下面还有一个 int 大小的东西,那个才是我们的 i。
那个东西是什么呢?那个东西是一个指针,叫做 vptr。所有有 virtual 的类的对象里面,
最头上就会自动加上一个隐藏的不让你知道的指针,它指向一张表,那张表叫做 vtable。
Vtable 里面是它所有 virtual 函数的地址。这张 vtable 不是这个对象的,而是这个类的。
所以这个类的所有 vptr 它们的值应该是一样的。
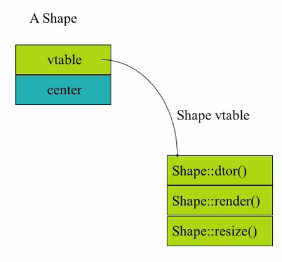
在运行的时候,它其实根本不知道这个对象的类型是什么,它只是顺着这个 vptr 找到了 vtable,然后找到了这个东西。
当我们做了这样一个赋值(两个具有继承关系):
Ellipse elly(20F,40F)
Circle circ(60F)
elly = circ;
我们是把 circ 的值给了 elly,所以 elly 依旧是 Ellipse,在这个赋值过程中,vptr 并没有赋给另外一个对象,它是不传递的。当然,我们也可以通过指针让这 vptr 传递。
/*
首先,通过指针调用才会是动态绑定,通过点调用是不会动态绑定的。
*/
如果析构可能被继承的话,让他们是 virtual 的。
Shape *p = new Ellipse(100.0F,200.0F);
...
delete p;
如果希望 Ellipse::~Ellipse()被调用,那么必须把 shape::~shape()声明成 virtual的,否则就会自动调用 shape::~shape()。如果 shape 的析构不是 virtual 的话,那么只有 shape 会被调用。
只有 C++是默认静态绑定的,为了追求效率。
如果父类子类两个函数是 virtual 的,它们名称相同,参数表也相同,那么它们构成覆盖/改写(overidden)关系。
想要调用父类的函数,要这样写:
Base::func()
假如 D 是 B 的一个子类,D::f()可以返回 B::f()里返回类型的子类。
如果 B 的函数返回了 B 类的引用或指针,D 继承了它,那么由于改写,D 类的函数返回的是 D 类的引用或指针。
父类可以返回父类的指针引用,也可以返回自己;子类返回子类的指针和子类的引用都是可以的,但是不能返回对象自己。
class Expr{
public:
virtual Expr* newExpr();
virtual Expr& clone();
virtual Expr self();
};
class BinaryExpr:public Expr{
public:
virtual BinaryExpr* newExpr();//ok
virtual BinaryExpr& clone(); //ok
virtual BinaryExpr self();//error,因为 upcast 只在指针引用中存在,不能出现多态性。
}
如果又有 overload 又有 override:
class Base{
public:
virtual void func();
virtual void func(int);
};
你在子类里也必须改写所有函数,而不是只有其中一个,要不会有一些被隐藏。
【课时 25 引用再研究 课程内容概述】
但是如果你的 reference 是函数参数,或者是成员变量,你就没有办法在声明它的时候给它捆绑,因为你不知道这个变量将来在构造对象时和谁捆在一起。
class X{
public:
int& m_y;
X(int& a);
};
X::X(int& a) : m_y(a) { }
然后,你就必须在构造函数的初始化列表中把它和谁捆绑在一起写出来,这是它唯一可以做的地方,你不能把它放在构造函数括号里面。如果写在里面,那就是赋值了,就是把值赋给它们捆着的那个变量了。
如果你要从一个函数里面返回一个 reference:
#include<assert.h>
const int size = 32;
doule myarray[size];
double& subscript(const int i){
return myarray[i];
}
和你要返回一个指针一样的,我们知道,在一个函数里面,你不能返回本地变量的地址。
同样的,你也不能返回本地变量作为引用。
main(){
for(int i = 0;i<size;i++){
myarray[i]=i*0.5;
}
double value = sibscript(12);
subscript(3) = 34.5;
}
我们把 sibscript 的返回值给了 value 对象。表面上看来,它们的类型是不匹配的,一个是引用,一个是变量。实际发生的事情是,把 myarray 里的 12 的值赋给了 value。也就是说,虽然我返回的是 reference,但是我接受的值是一个普通变量。
下面一行 subscript(3)=34.5 是我们比较少见的例子,一个函数的返回值放在赋值号的左边做了左值,因为它返回的是一个 reference,所以这个 reference 可以作为一个变量来使用,其实发生的事情是 myarray 的 3 等于 34.5.也就是返回值代表的变量等于了 34.5.
如果你要传递参数进函数,这个事情在前面讲过了,用 const 来保证指针所指对象不被改变是一种良好的编程习惯。//几乎这是唯一的方法。
之前提到的传 i*3 入 void f(int &i)是不可以的,因为 i*3 是一个 const 的临时变量,不能将 const 传给一个非 cosnt 引用函数,但是如果这个函数是 const 的,那么我们就可以传i*3 了。
classA{};
A f()
{
A a;
return a;
}
这件事情是可以的,与返回引用/指针不一样,这里返回一个成员变量,相当于完成了一次拷贝,再返回。
f()函数返回的对象里面的成员(甚至对象本身)是可以做左值的。如果你给这个返回加一个 const,那是有意义的,如果这个函数返回了成员对象,那是不能修改的。
如果 f()整个对象做左值的话,那么它本来返回的值相当于失踪了,没有人知道它去了哪里。
【课时 26 拷贝构造 1 课程内容概述】
我们现在做了一个函数叫做 func,这个函数要一个 currency 的对象作为输入,看清楚了这里没有&也没有*,我就是要一个对象作为输入。
void func(currency p){
cout<<“x = ”<<p.dollars();
}
…
Currency bucks(100,0);
func(bucks);//bucks is copied into p
p 是 func 里面的一个对象,和外面的 bucks 是没有关系的。
有可能会发生两种情况:
Currency p = bucks;//初始化
p = bucks;//赋值
我们来看这样一个例子:
#include<iostream>
#include<string>
using namespace std;
static int objectCount = 0;
class HowMany{
public:
HowMany(){objectCount++;print(“HowMany()”;}
void print(const string& msg = “”){
if(msg.size() != 0) cout<<msg<<”:”;
cout<<”objectCount = “<<objectCount<<endl;
}
~HowMany(){
objectCount--;
print(“~Howmany()”);
}
};
HowMany f(HowMany x){
cout<<”begin of f”<<endl;
x.print(“x argument inside f()”);
cout<<”end of f”<<endl;
return x;
}
int main(){
HowMany h;
h.print(“after construction of h”);
HowMany h2 = f(h);
h.print(“after call to f()”);
}
f()函数完全是对象入,对象出,没有任何的指针或引用。
HowMany():objectCount = 1
after construction of h: objectCount = 1
begin of f
x argument inside f():objectCount = 1
end of f
~HowMany():objectCount = 0;
after call to f():ojectCount = 0;
~HowMany():objectCount = -1;
~HowMany():objectCount = -2;
我们预期看到的应当是 objectCount = 0。因为构造++,析构--,最终构造和析构的数目应该是一样所以可以抵消,但是最终的结果却是-2,所以一定有什么被忽略了。
从析构里可以得到一个结论,在 f 里一定构造了一个 x 出来了,但是这个构造的过程没有通过 Howmany 的构造函数来做。
一定有两个析构,一个是 h,另外一个是 h2,那么,h2 的创建过程也绕过了我们的构造函数。
/*
在 C++中,你用圆括号和等号去初始化一个变量是等价的,尽管这看上去很古怪。
*/
用另外一个对象来初始化,这样一个构造函数我们有一个特殊的名字叫做拷贝构造。
T::T(const T&)
为什么在上面那个代码中我们没有给拷贝构造函数,它还是构造了?因为如果你没有给的话,C++会自动给你,当然,如果你给了,你可以用你那个函数来控制怎么做拷贝。C++自带的拷贝函数会拷贝每一个成员变量。这是在成员级别上的拷贝,不是字节对字节的拷贝,就是说如果你的类还有其他对象的话,那么它一定会调用那个类的拷贝构造函数,一直递归下去。
如果你的成员里面有指针的话,就会发生指针的拷贝,两个指针会指向同一个类型。引用也是一样。
标准写法的拷贝构造:
HowMany(const HowMany& )
这里要传参数进入,但是这个过程并没有发生拷贝构造。因为传的是引用。如果这里传的不是引用,而是对象本身,那么里面又会发生一次拷贝构造,这个是一个无限循环的过程,所以编译器一定会报错。
【课时 27 拷贝构造 2 课程内容概述】
class Person{
public:
person(const char *s);
~person();
void print();
//..accessor functions
private:
char *name; //char *instead of string
//...some info e.g. age,address,phone
};
如果你没有做拷贝构造的话,那么就会拷贝一个指针,这时候新的指针和老的指针就会是相同的,因为指向同一个东西。
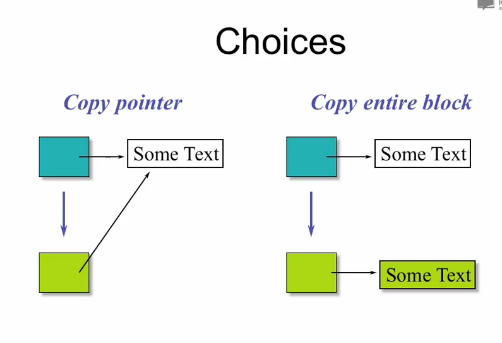
所以,我们还应该对它做一个另外的拷贝构造:
person::person(const Person& w){
name = new char[::strlen(w.name) + 1];
::strcpy(name,w.name);
}
//虽然 name 是 private 的,但是 private 是针对类,而不是针对对象,所以这里可以使用。
什么时候这样的拷贝构造会被调用呢?
当你去调一个函数的时候,那个函数说它的参数是一个对象的本身,而不是引用,也不是指针。在这个时候,就会发生拷贝构造。
void roster(Person);//declare function
Person child(“Ruby”);//create object
roster(child); //call function
Person baby_a(“Fred”);
// they use the copy ctor
Person baby_b = baby_a;//not an assignment
Person baby_c(baby_a);//not an assignment
Person captain(){
Person player(“George”);
return player;
}
....
Person who(“”)
...
Person copy_func(char *who){
Person local(who);
local.print();
return local;//copy ctor called!
}
Person nocopy_func(char *who){
return Person(who);
}//no copy needed
如果你的字符串是 string 而不是 char*,那么你就可以不需要写拷贝构造。除非你要直接访问内存,否则在 C++中最好使用 string。
任何时候你写一个类,都要写这三个函数:构造析构函数,虚函数,拷贝构造函数。
如果不希望被拷贝,写成私有的。别人来用这个类的对象,就不能是对象本身,只能是指针或者引用。但是你也很难直接拿这个类的对象做些什么事情。
【课时 28 静态对象 课程内容概述】
static 关键字,从 C 开始,就被赋予了两种不同的职责。它的一层含义,是说这个存储是持久存储的,第二层含义是说它的访问性是局限的。一个是说你在哪里,一个是说谁能看到你。他们两个可以是不一样的。
一个全局变量是 static,那么这个全局变量只在头文件有效;一个本地变量是 static,那么这个本地变量就具有持久存储了。(放在全局变量的地方)
static 函数只能在这个.c 文件里被访问,之外不能访问。
//static free functions and static global variables is deprecated
现在到了 C++,我们又有了 Static 的成员变量和成员函数。
全局静态变量
int g_global;
static int s_local;
void func(){
...
}
程序 2:
extern int g_global;//ok
void func();
extern int s_local;//error
class X{
X(int ,int);
~X();
....
};
有一个函数里包含静态对象
void f(){
static X my_X(10,20);
...
}
我们关心两件事情,一件是它在哪里,一件是它什么时候被构造出来/初始化。
它的存储是全局的,但是初始化(构造)是在函数内部的,也就是第一次进函数的时候。
如果存在条件的构造:
void f(int x){
if(x>10){
static X my_X(x,x*21);
}
}
C++会有一个标记来看对象有没有被构造,如果没有就不执行析构。
作为一个静态变量,它的析构是在什么时候发生的?程序结束的时候发生的。
全局变量
如果一个文件有多个.cpp,这些.cpp 文件里的全局变量谁先初始化谁后初始化是没有规定的。如果程序执行变量是互相依赖的,并没有比较好的解决方案。
【课时 29 静态成员 课程内容概述】
类的成员是 static 的会怎么样?
Persistant 就是只要在函数之间存在的,包括全局数据区的以及 malloc 出来的东西,在你离开了函数它依然存在。
在对象和对象之间还能存在的东西,是 persistant 的,比如全局变量,以及在同一个类里不随着对象不同而不同的东西。
也就是说,在 C++中,hidden 的属性已经结束了,我们用其他的东西比如 private,public来控制是否 hidden。但是 persistant 还要借助 static。
在 C++中,我们可以让一个成员是静态的,它成为不依赖于某个对象的东西,也就是整个类领域的东西。
静态成员变量在这个类的所有对象里都存在,值是保持一致的。
classA
{
public:
A({i=0;}
void printf(){cout<<i<<endl}
void set(int ii){i=ii;}
private:
static int i;
};
int main()
{
A a,b;
a.set(10);
b.print();
return;
}
程序报错,找不到 i。为什么?
这个变量 i 实际上在全局区,但是写在括号里的东西都是声明,而不是定义,在这里并没有 i 的位置。
一定要在程序的某个地方,写上:
int A::i;
//静态的成员变量一定要多做这件事情,在一个.cpp 里做这件事
//这里也可以赋值。但不要加 static
修改后得到:
10
初始化列表只能对非静态的成员变量初始化,静态成员变量只能在定义的地方初始化。
对于静态成员变量,可以用 this 来访问,在这件事情上是没有差异的。
假如静态成员变量是 public 的,想在类以外访问它:
cout<<a.i<<endl;
cout<<A::i<<endl;
想输出它,这两个都是对的。
但如果是 private 的话,就不能访问了。
接下来我们看静态成员函数:
static void say(int ii){cout<<ii<<<i<<endl;}
同样我们有两种写法:
a.say(0);
A::say(0);
你没有建立这个类的任何对象之前,你就可以访问类的静态函数静态对象。
假如成员变量还有一个非 static 的,想要在静态成员函数里调用是不可以的。静态函数只能够访问静态的成员变量。
但是,在这个静态函数中,它是没有 this 的,所以才不能访问所有非静态的成员。这样才能在没有对象的时候就能被调用,所以不能和具体的对象联系在一起。
【课时 30 运算符重载-基本规则 课程内容概述】

只有已经存在的运算符可以被重载。
要保持原有操作数的个数,以及保持原来的优先级。
前面要用关键字 operator。
这个运算符函数可以作为成员函数:
const String String::operator+(const String& that)
它已经有一个隐藏的参数,就是 this,所以它的参数表里只要再出现一个 that 就可以了。
返回对象是一个新的结果,没有&。
也可以作为全局函数:
const string operator+(const string& r,const string&s)
class Integer{
public:
Integer(int n = 0):i(n){}
const Integer operator+(const Integer& n)const{
return Integer(i+n.i);
}
. ...
private:
int i;
}:
Integer x(1),y(5),z;
x + y;//等价于 x.operator+(y);
如果在这个函数里对象没有被使用过,它有所存在的目的就是被传出去,而且它又是nline 的,编译器就会看到,它就会被优化,拷贝构造不会发生。
这里的 operator+就满足这样的条件。
z = x + y; //ok
z = x + 3; //ok 用构造函数把 3 构造成 int 对象
z= 3 + y;//error 编译器从左到右读取,看到 3 的时候就确定用整数的加减,再发现右边的不是整数,所以需要一个手段把对象变成整数,但是对象里没有这个手段。
一元运算符:
const Integer operator-()const{
return Integer(-i);
}
.....
z = -x;//等价于 z.operator = (x.operator-());
如果作为全局函数,不作为任何一个类的成员函数的话,那么就意味着你要把两个算子都写上去。那这样做就有可能,在别人的类已经做出来的时候,不修改它的代码,为它增加重载运算符,当然,前提条件是,你有办法接触到它里面的成员。
这个办法不一定是要求 public,比如说它有函数 get,set,可以读到某个成员的值,再用构造函数构造一个新的对象出来。
在两个参数上都可以进行类型转换:
class Integer{
friend const Integer operator+(
const Integer& lhs,
const Integer& rhs);
...
}
const Integer operator+(
const Integer& lhs,
const Integer& rhs){
return Integer(lhs.i+rhs.i);
}
Z = x +3;//ok
Z = 3 + y;//ok
Z = 3 + 7;//ok
单目运算符应该做成成员函数。
= () [] -> ->*必须做成成员函数。
其它二元运算符都可以做成非成员函数。














 3107
3107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









