









简介
在Hadoop兴起之后,google又发布了三篇研究论文,分别阐述了了Caffeine、Pregel、Dremel三种技术,这三种技术也被成为google的新“三驾马车”,其中的Pregel是google提出的用于大规模分布式图计算框架。主要用于图遍历(BFS)、最短路径(SSSP)、PageRank计算等等计算。在Pregel计算模式中,输入是一个有向图,该有向图的每一个顶点都有一个相应的独一无二的顶点id (vertex identifier)。每一个顶点都有一些属性,这些属性可以被修改,其初始值由用户定义。每一条有向边都和其源顶点关联,并且也拥有一些用户定义的属性和值,并同时还记录了其目的顶点的ID。
一个典型的Pregel计算过程如下:读取输入,初始化该图,当图被初始化好后,运行一系列的supersteps,每一次superstep都在全局的角度上独立运行,直到整个计算结束,输出结果。
在pregel中顶点有两种状态:活跃状态(active)和不活跃状态(halt)。如果某一个顶点接收到了消息并且需要执行计算那么它就会将自己设置为活跃状态。如果没有接收到消息或者接收到消息,但是发现自己不需要进行计算,那么就会将自己设置为不活跃状态。这种机制的描述如下图:
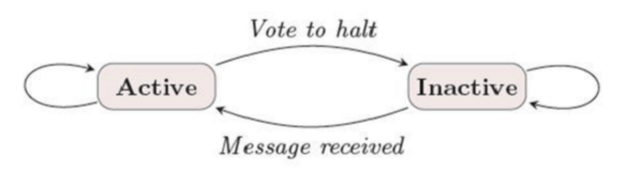
计算过程
Pregel中的计算分为一个个“superstep”,这些”superstep”中执行流程如下:1、 首先输入图数据,并进行初始化。
2、 将每个节点均设置为活跃状态。每个节点根据预先定义好的sendmessage函数,以及方向(边的正向、反向或者双向)向周围的节点发送信息。
3、 每个节点接收信息如果发现需要计算则根据预先定义好的计算函数对接收到的信息进行处理,这个过程可能会更新自己的信息。如果接收到消息但是不需要计算则将自己状态设置为不活跃。
4、 每个活跃节点按照sendmessage函数向周围节点发送消息。
5、 下一个superstep开始,像步骤3一样继续计算,直到所有节点都变成不活跃状态,整个计算过程结束。
下面以一个具体例子来说明这个过程:假设一个图中有4个节点,从左到右依次为第1/2/3/4个节点。圈中的数字为节点的属性值,实线代表节点之间的边,虚线是不同超步之间的信息发送,带阴影的圈是不活跃的节点。我们的目的是让图中所有节点的属性值都变成最大的那个属性值。
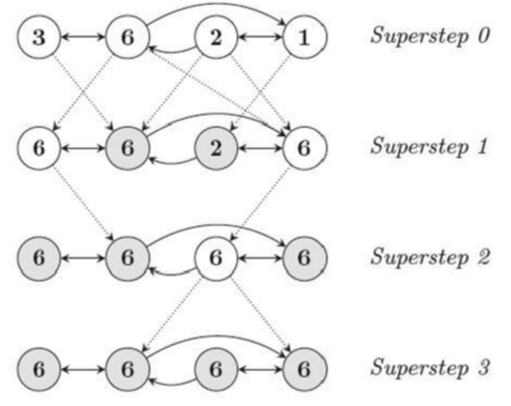
superstep 0:首先所有节点设置为活跃,并且沿正向边向相邻节点发送自身的属性值。
Superstep 1:所有节点接收到信息,节点1和节点4发现自己接受到的值比自己的大,所以更新自己的节点(这个过程可以看做是计算),并保持活跃。节点2和3没有接收到比自己大的值,所以不计算、不更新。活跃节点继续向相邻节点发送当前自己的属性值。
Superstep 2:节点3接受信息并计算,其它节点没接收到信息或者接收到但是不计算,所以接下来只有节点3活跃并发送消息。
Superstep 3:节点2和4接受到消息但是不计算所以不活跃,所有节点均不活跃,所以计算结束。
在pregel计算框架中有两个核心的函数:sendmessage函数和F(Vertex)节点计算函数。
Spark graphX的pregel API
Spark在其graphX组件中提供了pregel API,让我们可以用pregel的计算框架来处理spark上的图数据。以下操作均在spark-shell上进行,我们建立一个图,然后通过一个求单源最短路径的例子解释pregel的操作。准备工作
操作之前我们需要导入一些可能用到的包:再根据hdfs上的web-Google.txt文件生成图,这个文件可以在https://snap.stanford.edu/data/web-Google.html下载。

初次用edgelistfile建立图时,所有vertices、edges、triplets的属性值由于我没有指定所以默认值均为整数 1.
计算
首先设定源点,这里设置源点为0:
然后对图进行初始化:
这段代码的意思是对所有的非源顶点,将顶点的属性值设置为无穷,因为我们打算将所有顶点的属性值用于保存源点到该点之间的最短路径。在正式开始计算之前将源点到自己的路径长度设为0,到其它点的路径长度设为无穷大,如果遇到更短的路径替换当前的长度即可。如果源点到该点不可达,那么路径长度自然为无穷大了。
接下来开始计算最短路径:
我们打印一下sssp中的一些值看一下:

我们可以看到0点到354796的最短路径为11,到291526不可达。
过程详解
接下来详解这个过程:在调用pregel方法时,initialGraph会被隐式转换成GraphOps类,这个类中pregel方法的源码如下:
这个方法采用的是典型的柯里化定义方式,第一个括号中的参数序列分别为initialMsg、maxIterations、activeDirection。第一个参数initialMsg表示第一次迭代时即superstep 0,每个节点接收到的消息。maxIterations表示迭代的最大次数,activeDirection表示消息发送的方向,该值为EdgeDirection类型,这是一个枚举类型,有三个可能值:EdgeDirection.In/ EdgeDirection.Out/ EdgeDirection.Either.可以看到,第二和第三个参数都有默认值。
第二个括号中参数序列为三个函数,分别为vprog、sendMsg和mergeMsg。
vprog是节点上的用户定义的计算函数,运行在单个节点之上,在superstep 0,这个函数会在每个节点上以初始的initialMsg为参数运行并生成新的节点值。在随后的超步中只有当节点收到信息,该函数才会运行。
sendMsg在当前超步中收到信息的节点用于向相邻节点发送消息,这个消息用于下一个超步的计算。
mergeMsg用于聚合发送到同一节点的消息,这个函数的参数为两个A类型的消息,返回值为一个A类型的消息。
最后调用Pregel对象的apply方法返回一个graph对象。
Apply方法的源码如下,我们可以看到graph和计算的参数都被传过来了:
接下来再看一下我们刚开始的求单源最短路径的算法:
首先将所有除了源顶点的其它顶点的属性值设置为无穷大,源顶点的属性值设置为0.
Superstep 0:然后对所有顶点用initialmsg进行初始化,实际上这次初始化并没有改变什么。
Superstep 1 :对于每个triplet:计算triplet.srcAttr + triplet.attr 和 triplet.dstAttr比较,以第一次为例:假设有一条边从0到a,这时就满足triplet.srcAttr + triplet.attr < triplet.dstAttr,这个triplet.attr的值实际上为1(没有自己指定,默认值都是1),而0的attr值我们早已初始化为0,0+1<无穷,所以发出的消息就是(a,1)这个在每个triplet中是从src发放dst的。如果某个边是从3到5,那么triplet.srcAttr + triplet.attr < triplet.dstAttr就不成立,因为无穷大加1等于无穷大,这时消息就是空的。Superstep 1就是这样,这一步执行完后图中所有的与0直接相连的点的attr都成了1而且成为获跃节点,其它点的attr不变同时变成不活跃节点。活结点根据triplet.srcAttr + triplet.attr < triplet.dstAttr继续发消息,mergeMsg函数会对发送到同一节点的多个消息进行聚合,聚合的结果就是最小的那个值。
Superstep 2:所有收到消息的节点比较自己的attr和发过来的attr,将较小的值作为自己的attr。然后自己成为活节点继续向周围的节点发送attr+1这个消息,然后再聚合。
直到没有节点的attr被更新,不再满足activeMessages > 0 && i < maxIterations (活跃节点数为大于0且没有达到最大允许迭代次数)。这时就得到节点0到其它节点的最短路径了。这个路径值保存在其它节点的attr中。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









