






女主宣言
3月10号,在IT趣学社技术沙龙第12期——《大话运维之弹性运维最佳实践》上,360奇云团队分享了《360奇云的架构演进之路》。360奇云提供灵活的专有网络(VPC)服务。根据业务模型特点,划分出不同的虚拟隔离网络,定制内容包括选择自有IP地址范围、划分网段、路由器隔离网络等,实现多业务网络规划管理。本文为大家介绍360奇云的VPC架构的演变历程。
本文首发于自“360奇云”,已授权转载。
360奇云是360公司旗下品牌,以国内最大的互联网安全为基础,致力于为企业提供高性能、可依赖、安全的公有云服务,最大程度降低 IT基础架构技术和成本门槛,助力企业轻松上云。360奇云官方网站https://qiyun.360.cn/
更多有关360奇云的问题,可关注“360奇云”。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!
前言
360奇云的IaaS服务虚拟化网络使用的是openstack的neutron组件,并在社区的版本上做了较大改动,维护着自己内部的版本。本文介绍奇云的VPC方案及在迭代版本时候的考虑,分成两个阶段。
阶段一:在社区liberty版本的基础上做了一些定制化开发(下文介绍)并在奇云北京A区上线。
阶段二:在之前的基础上,做了一次大的架构调整,采用了软硬结合的方案,引入了EVPN,在奇云上海C区上线。
新架构不仅可以提升VPC的网络传输性能、节省资源的CPU消耗,还可以降低运维复杂度。
基于阶段二的新架构,奇云也将推出云物理机等更多服务与大家见面。
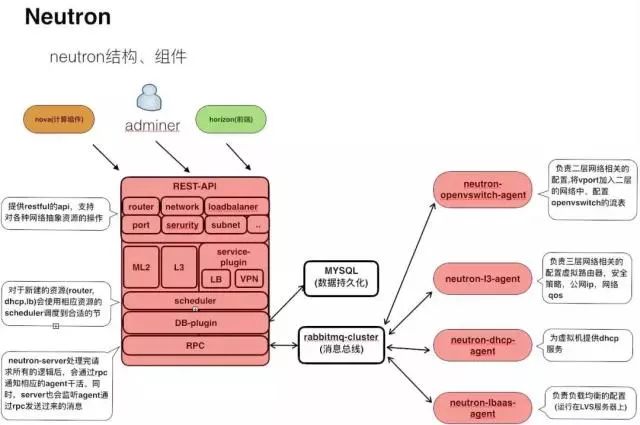
Neutron项目的结构图
阶段一
在360奇云的北京A区,网络基本上使用的是社区liberty版本的DVR(分布式虚拟路由器)方案,虚拟网络的路由器会以分布式的形式起在相应的计算节点上,跨物理节点的东西流量(同一个虚拟网络里不同终端交互的流量)使用openvswitch的vxlan来进行隔离。
我们在liberty版本的基础上做了定制化开发,增加了公网IP限速、OSPF协议动态路由通告等功能。
主要改动
1. 为了满足对公网ip流量限速的需求,我们扩展了neutron api的extensions,新增了Qos资源,底层使用linux tc来实现。区分虚拟机的管理流量和业务流量,保证管理流量的高优先级。
2. liberty版本DVR方案的虚拟网络的外部网络是个二层网络,每台计算节点的fip-gateway虚接口会被分配一个外部网络地址做转发使用,这样就造成了公网ip地址的浪费,我们在这个地方进行了改造,给fip-gateway设备分配172.16.0.0/16的私网段地址以节省公网地址。
3. 公司的IDC物理网络结构是三层网络(可以理解成网关都在接入交换机上,网络的广播域被终结在接入交换机,这种做法可以避免IDC内大面积的广播风暴出现),上面提到lieberty的外部网络是个二层网络,这和我们IDC物理环境不符。直接使用它这种模式的话,在虚拟机跨接入交换机迁移的场景中,虚拟机南北流量会中断。我们也对这里进行了改造,将外部网络改造成三层网络,在neutron-l3-agent上新增了一个运行ospf协议的driver,网络节点和计算节点都会使用这个driver和交换机建立ospf邻居,来动态通告本物理机的所有公网ip,实现虚拟机可以在整个IDC内迁移,不受物理位置的限制。
4. 部分特殊的虚拟机有连通我们内部管理网的需求,我们仿照浮动ip的机制扩展了新的资源serviceip,专门用于虚拟机和我们的管理网互通。
北京A区示意图
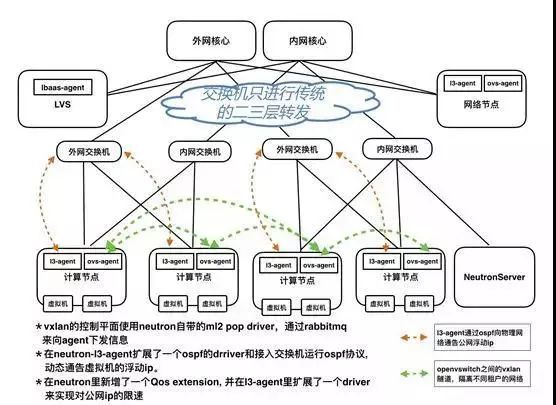
(备注:物理网络都是高可用架构,由于本文主要介绍虚拟化网络,故全文节省这一部分的画图)
问题
在使用这套架构的过程中发现的一些问题:
1. vxlan隧道的逻辑控制层是neutron的ml2 pop driver,性能较差。
ml2 pop driver的工作原理:当集群中有新的vport(端口)被创建出来,计算节点上的neutron-openvswitch-agent会向neutron-server请求获取这个vport的信息,neutron-server会通过ml2 pop driver从数据里获取这个vport的虚拟网络的信息,计算完拓扑后,通过消息队列服务器向集群中的节点通告谁和谁之间应该建立vxlan的隧道。在集群规模较大的时候(我们当时集群超过500个计算节点)反复测试批量创建虚拟机(100-150台),发现ml2 pop driver的表现非常的差,python的orm模块耗时过长,严重消耗neutron-server的cpu资源。从测试的结果来看,继续使用这种结构,而不管其他的因素,光是vxlan的控制层面就是集群规模的瓶颈,很难将单个集群的规模做到更大。
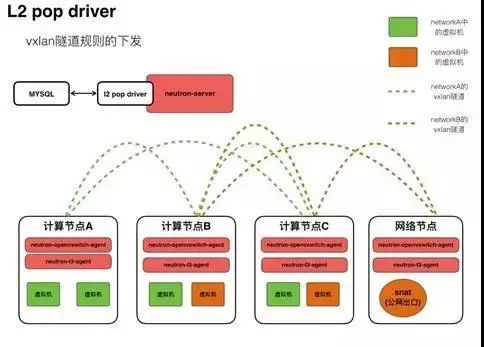
2. 第二个问题:由于vxlan本身性能的问题,openvswtich封装和解封装vxlan包头消耗较多计算节点上的CPU资源。
3. 当时我们用户有需求是在虚拟化里提供裸机和其他的一些硬件设备(如防火墙)的服务,在这个方案中,很难将这部分硬件设备接入到租户的VPC里。
阶段二
为了解决现存的问题以及满足新的功能需求,我们在迭代下个版本的时候做了较大的改动。采用了软硬结合的方案。硬件接入交换机也作为云虚拟化网络的一部分(之前的方案中,交换机仅仅只提供传统的二三层网络转发)。
在新版本的虚拟化网络中引入了较新的技术:硬件EVPN+Vxlan。
EVPN协议是一种二层VPN技术,控制平面采用MP-BGP通告EVPN路由信息,数据平面采用VXLAN封装方式转发报文。
在考虑是否使用这套方案的时候,一方面是硬件EVPN+VXLAN和接入交换机作为VTEP的方案能解决我们上一代架构中的主要问题以及可以满足我们的后续需求, 另一方面是我们已经将这种EVPN+Vxlan的方案应用到了公司IDC的内部网络中并取得了一定的网络优化效果及积累了这方面较为丰富的运维经验,使得我们有信心做这一次虚拟化网络较大的改动。
上海C区示意图
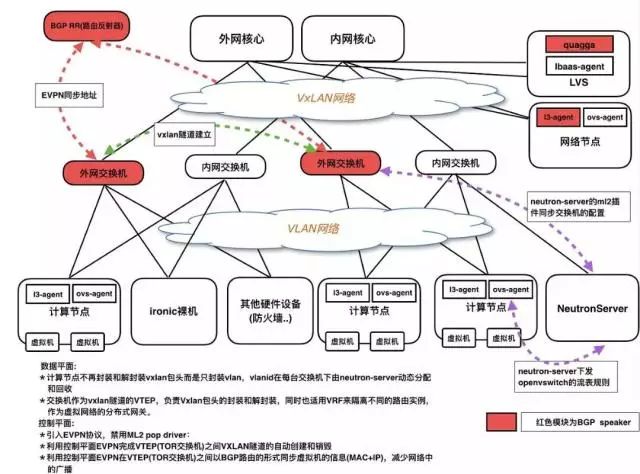
主要改动
1. 将vxlan的VTEP从openvswitch移交到接入交换机从而减少openvswitch封装/解封装vxlan包消耗的计算节点cpu资源。计算节点的虚拟网络的流量在openvswitch上封装成普通的vlan包,送到交换机后,再由交换机根据vlan和vxlan的对应关系封装vxlan。每台接入交换机下的vlan号由neutron-server动态分配和回收。这种模式下,可以很轻松地将硬件设备接入到租户的VPC网络中。
2. 接入交换机充当虚拟化网络的分布式网关,使用VRF来隔离不同租户的路由表。
3. 使用EVPN协议来充当Vxlan隧道的控制层,不再使用ml2 pop driver。降低了neutron-server的压力,另一个好处是网络中的终端信息(MAC+IP)可以通过EVPN协议以BGP路由形式在邻居之间同步,减少了网络中的泛洪流量。
4. 因为整套架构基于BGP协议,在网络节点上的neutron-l3-agent上新增了BGP driver来动态通告公网浮动ip,不再使用OSPF协议。
5. 无公网ip的虚拟机snat出口的高可用,社区采用的是keepalived机制在多台网络节点之间进行主备切换,我们的在新结构中的解决方案是多台网络节点向租户的VRF通告不同metric的bgp路由,通过bgp协议的选路机制来实现出口的切换,相比于keepalived有更快的切换速度和更好的可维护性。
总结
为了兼容不同网络硬件的厂商的网络操作系统,我们在neutron的ml2和l3 flavors里各新增了一个二层和三层driver组装netconf的请求向集群中的硬件交换机同步配置。使用过程中发现,由于neutron-server直接向设备发送请求,前端过来的请求会在这里消耗较多的时间,造成用户体验不佳。
我们做了后续的优化,社区里neutron的资源如:network,subnet,,router, port一直以来没有状态这个属性。为了优化用户体验,给neutron的各类资源增加状态这个属性,将netconf模块从neutron-server拆分出去,两者之间的交互采用https协议交互,整个工作流以异步的形式运行,netconf模块根据操作结果更新netron里对应资源的状态、前端轮询资源的状态。
HULK一线技术杂谈
由360云平台团队打造的技术分享公众号,内容涉及云计算、数据库、大数据、监控、泛前端、自动化测试等众多技术领域,通过夯实的技术积累和丰富的一线实战经验,为你带来最有料的技术分享















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









