







大家好,我是Mac Jiang,今天和大家分享Coursera-Stanford University-Machine Learning-Programming Exercise 7:K-means Clustering and Principal Component Analysis的第二部分PCA(主成分分析)的实现过程。第一部分的实现我已经在前面微博中展现,地址为:http://blog.csdn.net/a1015553840/article/details/50877623。第二部分讲的主要是PCA的实现过程,我写的代码虽然是正确的,但不一定是最好的,如果你有更好的想法,请留言讨论学习。当然,欢迎博友转载此文章,但转载前请标明出处,谢谢!
PCA(主成分分析)是一种降低数据维度的算法,降低维度的好处主要有三个:(1)减少存储空间;(2)减小数据量,提高算法速度;(3)将数据降到3D,2D,可视化数据
这次实验过程主要可以分为两大部分:
(1)第一部分主要是展现PCA理论和实现过程
(2)第二部分主要是利用PCA实现人脸图像的降维工作,并利用得到的低维度数据重建高纬度图像


数据集:ex7data1.mat---实现实验第一部分PCA理论实现的数据
ex7face.mat---实现实验第二部分人脸图像降维的数据
函数:ex7_pca.m---pca实现过程的控制函数,控制程序的进行过程
pca.m---PCA的实现文件,需要完善代码!
projectData.m---利用得到的PCA参数把n维的数据降为k维的数据,需要完善代码!
recoverDate.m---利用得到的低维(K维)数据重建成n维数据,需要完善代码!
实验主要用到了这4个文件,其中需要完善代码的文件有三个。
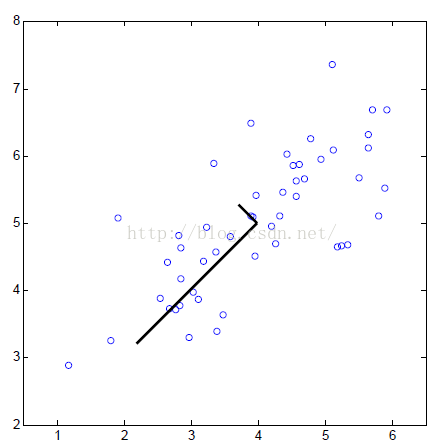
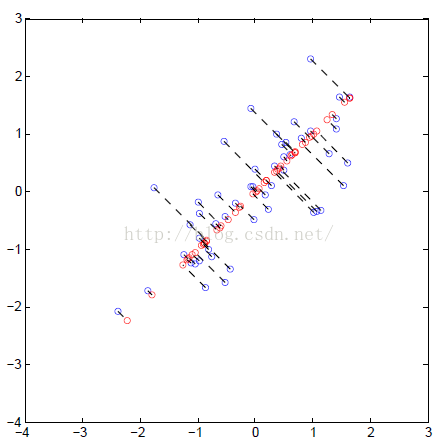
PCA将数据从n维降低到k维的过程为:
(1)数据预处理,特征缩放+均值归一。
均值归一(mean normalization)作用:求数据的平均值mu,用每个数据减去平均值x - mu,使数据在0附近
特征缩放(Feature Scaling)作用:由于不同特征值得数量级相差很大,需要将他们缩放到同一数量级,最好在[-1,1]区间内
(2)计算协方差矩阵:sigma = 1/m * X' * X
(3)计算协方差矩阵sigma的特征向量:[U,S,V] = svd(sigma)。这里U是特征向量矩阵,降低到K维就区向量的前K列即可,记U_reduce = U(:,1:k);S为对角线矩阵,用于计算保留的差异性。
(4) 将数据降到K维:Z = X * U_reduce
(5)将数据重建到n维: X_approx = Z * U_reduce’
注意,得到的U的每个列向量都是协方差矩阵sigm
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4466
4466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









