









参考教材:算法设计与分析(第3版) 王晓东 编著 清华大学出版社
贪心算法总是做出在当前看来最好的选择,也就是说贪心算法并不从整体最优考虑,它所做出的选择只是在某种意义上的局部最优选择。
贪心算法的基本要素
1. 贪心选择性质
指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。
这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
2. 最优子结构性质
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。
拿单源最短路径当例子,从顶点5到顶点1的最短路径假设是5->4->2->1,那么,顶点4到1的最短路径一定是4->2->1,顶点2到1的最短路径一定是2->1。这种性质就叫做最优子结构性质。
问题的最优子结构性质是该问题可用动态规划算法或贪心算法求解的关键特征。
单源最短路径
Dijkstra算法是解单源最短路径问题的贪心算法。
算法思想的简单描述:要找出源到其他顶点的最短距离,首先将所有顶点划分成两个集合,S是已经到达的顶点,V是没有到达的顶点,显然S+V就是所有顶点。初始,S集合中只包含源顶点(本例中是1号顶点),然后找出V中距离S集合最近的一个顶点(即贪心选择,至于为什么是S集合,请务必理解该问题的最优子结构性质)。那么显然,需要有个对象来记录每个顶点到源顶点的距离,这就是代码中的dist数组。dist[2]=x就表示,顶点2到源顶点的最短距离是x。找到后,记录下路径。如何记录,同样需要一个对象,即代码中的prev数组。prev[2]=y就表示,顶点2到源顶点的最短路径中,顶点2的前一个顶点是顶点y。是不是和链表有点像?记录下路径的同时是不是还需要将该顶点加入到S集合中呢?它就是s数组了。由于简单,不多说。
测试数据:
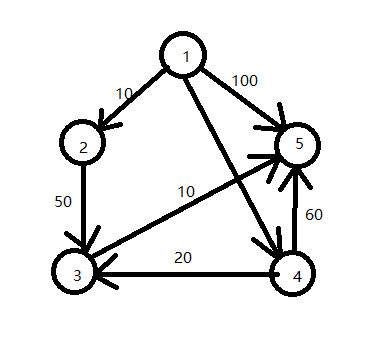
代码:
public class Dijkstra {
static float max = Float.MAX_VALUE;
/**
*
* @param v 源
* @param a 图
* @param dist 路径长度
* @param prev 路径
*/
public static void dijkstra(int v, float[][] a, float[] dist, int[] prev) {
// v是源,dist[i]表示当前从源到顶点i的最短特殊路径长度,prev[i]=j:最短路径中顶点i的前一个顶点是j,类似于链表
int n = dist.length - 1;// 节点个数
if (v < 1 || v > n)
return;
boolean[] s = new boolean[n + 1];
// 初始化
for (int i = 1; i <= n; i++) {
dist[i] = a[v][i];
s[i] = false;
if (dist[i] == Float.MAX_VALUE)
prev[i] = 0;
else
prev[i] = v;
}
dist[v] = 0;
s[v] = true;
for (int i = 1; i < n; i++) {// 循环n-1次
float temp = Float.MAX_VALUE;
int u = v;
for (int j = 1; j <= n; j++) {// 寻找不在集合内且距离集合最近的节点j
if ((!s[j]) && (dist[j] < temp)) {
u = j;// 记录节点
temp = dist[j];// 记录最短特殊路径长度
}
}
s[u] = true;// 将节点u放入集合
for (int j = 1; j <= n; j++) {// 重新设置dist[]和prev[]的值
if ((!s[j]) && (a[u][j] < Float.MAX_VALUE)) {// 寻找不在集合内,且可达的节点
float newdist = dist[u] + a[u][j];
if (newdist < dist[j]) { // 与旧值进行比较,保留小的值
dist[j] = newdist;
prev[j] = u;
}
}
}
}
}
public static void main(String[] args) {
float[][] a = { { max, max, max, max, max, max },
{ max, 0, 10, max, 30, 100 }, { max, max, 0, 50, max, max },
{ max, max, max, 0, max, 10 }, { max, max, max, 20, 0, 60 },
{ max, max, max, max, max, 0 } };
int n = a.length;
float[] dist = new float[n];
int[] prev = new int[n];
dijkstra(1, a, dist, prev);
System.out.println(" 顶点1到5的最短路径:");
trace(prev, 5);
System.out.println();
System.out.println(" 顶点1到3的最短路径:");
trace(prev, 3);
}
public static void trace(int[] prev, int n) {
if (n == 1) {
System.out.print(n + " ");
return;
}
trace(prev, prev[n]);
System.out.print(n + " ");
}
}测试数据运行结果:
顶点1到5的最短路径:
1 4 3 5
顶点1到3的最短路径:
1 4 3 将其中的一些运算步骤打印出来后,如下:
其中,prev数组记录路径。如果要找出顶点1到5的最短路径,可以从数组prev得到顶点5的前一个顶点是3,3的前一个订单是4,4的前一个顶点是1。于是从顶点1到5的最短路径为1,4,3,5.
dist数组记录当前顶点距离源的最短路径长度。
s[1]=true表示1顶点已经计算出最短路径了,不需要再计算了。
初始化:
1 2 3 4 5
prev[] 1 1 0 1 1
dist[] 0 10 max 30 100
s[] true false false false false
对数组进行必要的修改:
1 2 3 4 5
prev[] 1 1 2 1 1
dist[] 0 10 60 30 100
s[] true true false false false
对数组进行必要的修改:
1 2 3 4 5
prev[] 1 1 4 1 4
dist[] 0 10 50 30 90
s[] true true false true false
对数组进行必要的修改:
1 2 3 4 5
prev[] 1 1 4 1 3
dist[] 0 10 50 30 60
s[] true true true true false
对数组进行必要的修改:
1 2 3 4 5
prev[] 1 1 4 1 3
dist[] 0 10 50 30 60
s[] true true true true true最小生成树
1. Prim算法
算法的简单描述:与单源最短路径类似。同样将顶点分成两个集合,S和V。初始,S集合只包含顶点1,然后找出V集合中距离S集合距离最短的顶点,所以同样需要有对象保存顶点到集合S的距离,即lowcost数组。lowcost[2]=x就表示,顶点2距离集合S的最短距离是x。找到后,需要记录路径,即closest数组。closest[2]=y就表示,顶点2距离集合S中最近的顶点是y。同样,也需要一个变量来表示一个顶点是属于哪个集合,即s数组。
测试数据:
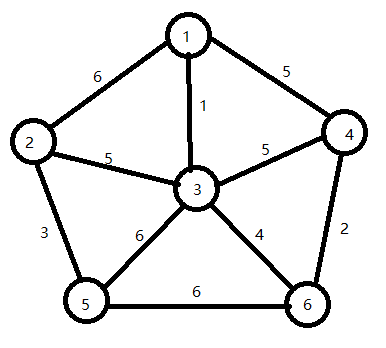
代码:
public class Prim {
/**
* @param n 图顶点个数
* @param c 图的二维数组
*/
public static void prim(int n,float [][] c){
float [] lowcost=new float [n+1];
int [] closest=new int [n+1];
boolean [] s=new boolean[n+1];
//初始化
s[1]=true; //以第一个节点为起点
for(int i=2;i<=n;i++){
lowcost[i]=c[1][i];
closest[i]=1;
s[i]=false;
}
for(int i=1;i<n;i++){ //循环n-1次找出剩余n-1个节点
float min=Float.MAX_VALUE;
int j=1;
//找集合外与集合最近的节点
for(int k=2;k<=n;k++){
if((lowcost[k]<min)&&(!s[k])){
min=lowcost[k];
j=k;
}
}
System.out.println("找到边"+j+","+closest[j]);
s[j]=true;
//找离j最近的节点k,寻找与集合最近的节点
for(int k=2;k<=n;k++){
if((c[j][k]<lowcost[k])&&(!s[k])){
lowcost[k]=c[j][k]; //记录权值
closest[k]=j; //记录节点
}
}
}
}
public static void main(String[] args){
float [][] c={
{100,100,100,100,100,100,100},
{100,100,6,1,5,100,100},
{100,6,100,5,100,3,100},
{100,1,5,100,5,6,4},
{100,5,100,5,100,100,2},
{100,100,3,6,100,100,6},
{100,100,100,4,2,6,100}};
prim(6,c);
}
}打印运算时的中间数据,如下:
初始化:
1 2 3 4 5 6
lowcost[] 0 6 1 5 100 100
closest[] 0 1 1 1 1 1
s[] true false false false false false
找到边3,1
对数组进行必要的修改:
1 2 3 4 5 6
lowcost[] 0 5 1 5 6 4
closest[] 0 3 1 1 3 3
s[] true false true false false false
找到边6,3
对数组进行必要的修改:
1 2 3 4 5 6
lowcost[] 0 5 1 2 6 4
closest[] 0 3 1 6 3 3
s[] true false true false false true
找到边4,6
对数组进行必要的修改:
1 2 3 4 5 6
lowcost[] 0 5 1 2 6 4
closest[] 0 3 1 6 3 3
s[] true false true true false true
找到边2,3
对数组进行必要的修改:
1 2 3 4 5 6
lowcost[] 0 5 1 2 3 4
closest[] 0 3 1 6 2 3
s[] true true true true false true
找到边5,2
对数组进行必要的修改:
1 2 3 4 5 6
lowcost[] 0 5 1 2 3 4
closest[] 0 3 1 6 2 3
s[] true true true true true true
2. Kruskal算法
Kruskal算法是构造最小生成树的另一个常用算法。
(这个大坑先留着)














 9537
9537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









