







1、优缺点
优点:
SAX 从根本上解决了 DOM 在解析 XML 文档时产生的占用大量资源的问题。其实现是通过类似于流解析的技术,通读整个 XML 文档树,通过事件处理器来响应程序员对于 XML 数据解析的需求。由于其不需要将整个 XML 文档读入内存当中,它对系统资源的节省是十分显而易见的,它在一些需要处理大型 XML 文档以及性能要求较高的场合有起了十分重要的作用。支持 XPath 查询的 SAX 使得开发人员更加灵活,处理起 XML 来更加的得心应手。
缺点:
但是同时,其仍然有一些不足之处也困扰广大的开发人员:首先是它十分复杂的 API 接口令人望而生畏,其次由于其是属于类似流解析的文件扫描方式,因此不支持应用程序对于 XML 树内容结构等的修改,可能会有不便之处。
适用范围:
大型 XML 文件解析、只需要部分解析或者只想取得部分 XML 树内容、有 XPath 查询需求、有自己生成特定 XML 树对象模型的需求
2、触发器工作流程
在Sax的解析过程中,读取到文档开头、结尾,元素的开头和结尾都会触发一些回调方法,你可以在这些回调方法中进行相应事件处理这四个方法是:startDocument() 、endDocument()、 startElement()、endElement。此外,我们还需要characters()方法来仔细处理元素内包含的内容将这些回调方法集合起来,便形成了一个触发器类DefaultHandler。一般从Main方法中读取文档,却在触发器中处理文档,这就是所谓的事件驱动解析方法
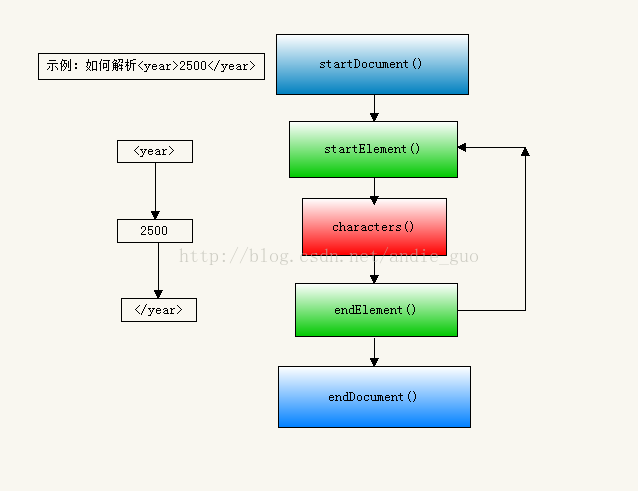
如上图,在触发器中,首先开始读取文档,然后开始逐个解析元素,每个元素中的内容会返回到characters()方法接着结束元素读取,所有元素读取完后,结束文档解析
DefaultHandler类:

3、SAX解析XML文件
使用XMLReader解析
// 1.新建一个工厂类SAXParserFactory
SAXParserFactory factory =SAXParserFactory.newInstance();
// 2.让工厂类产生一个SAX的解析类SAXParser
SAXParser parser = factory.newSAXParser();
// 3.从SAXPsrser中得到一个XMLReader实例
XMLReader reader = parser.getXMLReader();
// 4.得到内容处理器
SaxHandler saxHandler = new SaxHandler();
// 5.把自己写的handler注册到XMLReader中,一般最重要的就是ContentHandler
reader.setContentHandler(saxHandler);
// 6.将一个xml文档或者资源变成一个java可以处理的InputStream流后,解析正式开始
reader.parse(newInputSource(new FileInputStream("src/com/andieguo/saxparserdemo/books.xml")));
使用SAXParser解析
// 1.创建解析工厂
SAXParserFactory saxParserFactory =SAXParserFactory.newInstance();// 获取单例
// 2.得到解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
// 3.得到内容处理器
SaxHandler saxHandler = new SaxHandler();
// 4.解析器绑定内容处理器,并解析xml文件
saxParser.parse(new File("src/com/andieguo/saxparserdemo/books.xml"),saxHandler);
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









