







一、简单介绍
1、定义
Ensure a class has only one instance, and provide a global point of
access of it.
翻译过来的意思就是:确保一个类只有一个实例,要自行实例化并且想整个系统提供这个实例。
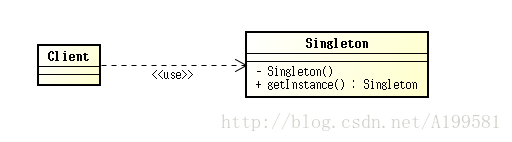
2、UML类图
3、实现的关键点
- 构造函数不对外开放,一般未private;
- 通过一个静态方法或者枚举返回单例对象;
- 确保单例类的对象有且只有一个,尤其是多线程环境下;
- 确保单例类对象在反序列化时候不会重新构建对象;
二、实现方式
1、饿汉模式
public class Singleton {
private static Singleton sInstance = new Singleton();
private Singleton() {
}
public static Singleton getInstance() {
return sInstance;
}
}优点:
- 实现简单。
- 多线程安全。
缺点:
- 不能传递参数给构造函数。
- 需要考虑反序列化问题(见下文的补充材料)。
2、懒汉模式
public class Singleton {
private static Singleton sInstance = null;
private Singleton() {
}
public static synchronized Singleton getInstance() {
if (sInstance == null) {
sInstance = new Singleton();
}
return sInstance;
}
}优点:
- 单例只有在使用的时候才会被实例化,一定程度上节约了资源。
缺点:
- 第一次加载的时候需要及时进行实例化,反应稍慢;
- 每次调用
getInstance()方法都需要进行同步处理,造成不必要的同步开销。 - 需要考虑反序列化问题(见下文的补充材料)。
3、Double Check Lock (DCL) 模式
public class Singleton {
private volatile static Singleton sInstance = null;
private Singleton() {
}
public static Singleton getInstance() {
if (sInstance == null) {
synchronized (Singleton.class) {
if (sInstance == null) {
sInstance = new Singleton();
}
}
}
return sInstance;
}
}优点:
- 资源利用率高。第一次执行
getInstance()方法时候对象才会被实例化,效率高。
缺点:
- 第一次加载时反应慢。
- 由于Java内存模型的原因偶尔会失败,低于JDK 5版本下不可使用(这个问题被称为双重检查失效问题,见下文的补充材料)。
- 需要考虑反序列化问题(见下文的补充材料)。
4、静态内部类模式
public class Singleton {
private Singleton() {
}
public static Singleton getInstance() {
return SingletonHolder.sInstance;
}
private static class SingletonHolder {
private static final Singleton sInstance = new Singleton();
}
}优点:
- 只有第一次调用Singleton的
getInstance()方法时,导致虚拟机加载SingletonHolder类,此时 sInstance 才会被初始化,。 - 确保线程安全。
缺点:
- 不能给构造函数传递参数。
- 需要考虑反序列化问题(见下文的补充材料)。
5、枚举方式实现
public enum Singleton {
INSTANCE;
public void otherMethod(){
//do something.
}
}优点:
- 写法简单;
- 线程安全(得益于枚举实例的创建是线程安全的);
- 不用考虑反序列话问题。
三、使用场景
- 要求生成唯一序列号的环境。
- 在整个项目中需要一个共享的访问点或者共享数据。
- 创建一个对象需要耗费的资源过多,如要访问IO或者数据库资源。
- 需要定义大量的静态常量和静态方法的环境(也可以直接声明为static的方式)。
四、单例模式优缺点
1、优点
- 减少了内存开支。单例模式在内存中只有一个实例,特别是一个对象需要频繁的创建和销毁的时候,而且创建和销毁时性能又无法优化时,单例模式的有点就非常明显。
- 减少系统的性能开销。当一个对象的产生需要较多的资源的时候,如读取配置文件、产生其他依赖对象的时候,则可以在应用启动的时候直接创建一个单例,然后用永久留内存的方式解决(注意JVM的垃圾回收机制)。
- 避免了对资源的多重占用。如一个写文件操作,就避免了多个对象对同一对象的写入操作。
- 可以在系统设置安全的访问点,优化和共享资源的访问。
2、缺点
- 单例模式一般没有接口,扩展很困难,如若想扩展就只能修改代码。
- 测试不方便。并行开发环境下,如果单例模式没有写完,是不能进行测试的。
- 单例模式与单一职责原则有冲突的。一个类应该只实现一个逻辑,而不关心它是否是单例的,单例模式把”要单例“和业务逻辑融合在一个类中(但是我个人认为这并不是一个缺点,毕竟原则是死的,人是活的,一切都要从实际环境出发)。
五、补充
补充 1、反序列化问题
通过序列化可以将一个单例的对象写到磁盘里,然后再读出来,从而获得一个实例,即使构造函数是私有的,反序列化时依然可以通过特殊的途径去创建类的一个新的实例(两者的hashcode是不同的)。
那如何解决这个问题呢,如何才能保证单例类对象在反序列化时候不会重新构建对象呢?
反序列化操作提供了一个很特别的钩子函数,类中具有一个私有的、被实例化的方法readResolve(),这个方法可以让开发人员控制对象的反序列化。要杜绝单例对象在被反序列化时重新生成新的对象,那么只需要在单例类中加入如下代码:
private Object readResolve() throws ObjectStreamException {
return sInstance;
}方法readResolve会在ObjectInputStream已经读取一个对象并在准备返回前调用。ObjectInputStream 会检查对象的class是否定义了readResolve方法。如果定义了,将由readResolve方法指定返回的对象。返回对象的类型一定要是兼容的,否则会抛出ClassCastException 。这部分的源代码(可以在ObjectInputStream类里找到)以及分析如下:
/**
* Reads and returns "ordinary" (i.e., not a String, Class,
* ObjectStreamClass, array, or enum constant) object, or null if object's
* class is unresolvable (in which case a ClassNotFoundException will be
* associated with object's handle). Sets passHandle to object's assigned
* handle.
*/
private Object readOrdinaryObject(boolean unshared)
throws IOException
{
if (bin.readByte() != TC_OBJECT) {
throw new InternalError();
}
ObjectStreamClass desc = readClassDesc(false);
desc.checkDeserialize();
//获取单例类的Class对象
Class<?> cl = desc.forClass();
if (cl == String.class || cl == Class.class
|| cl == ObjectStreamClass.class) {
throw new InvalidClassException("invalid class descriptor");
}
Object obj;
try {
//构造单例对象
obj = desc.isInstantiable() ? desc.newInstance() : null;
} catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
passHandle = handles.assign(unshared ? unsharedMarker : obj);
ClassNotFoundException resolveEx = desc.getResolveException();
if (resolveEx != null) {
handles.markException(passHandle, resolveEx);
}
//数据的读取
if (desc.isExternalizable()) {
readExternalData((Externalizable) obj, desc);
} else {
readSerialData(obj, desc);
}
//执行到了这一步说明已经利用从磁盘里读取的数据成功创建了单例对象。
handles.finish(passHandle);
//注意这个if的最后一个判断条件。
if (obj != null &&
handles.lookupException(passHandle) == null &&
desc.hasReadResolveMethod())
{
//只用单例类里面创建了readResolve方法,才会执行到这一步。
Object rep = desc.invokeReadResolve(obj);
if (unshared && rep.getClass().isArray()) {
rep = cloneArray(rep);
}
if (rep != obj) {
// Filter the replacement object
if (rep != null) {
if (rep.getClass().isArray()) {
filterCheck(rep.getClass(), Array.getLength(rep));
} else {
filterCheck(rep.getClass(), -1);
}
}
//用readResolve返回的对象重新赋值给obj对象。
handles.setObject(passHandle, obj = rep);
}
}
return obj;
}补充 2、双重检查(DCL)机制失效问题
先附上DCL实现的单例模式(未加volatile关键词)代码以供查看:
public class Singleton {
private static Singleton sInstance = null;
private Singleton() {
}
public static Singleton getInstance() {
if (sInstance == null) {
synchronized (Singleton.class) {
if (sInstance == null) {
sInstance = new Singleton();
}
}
}
return sInstance;
}
}为什么会出现DCL失效问题呢?我们来分析下。假设线程A执行到sInstance = new Singleton();语句,这里看起来是一句代码,但实际上他并不是一个原子操作,这句代码会被编译成多条汇编指令(如何查看class的汇编代码请看补充3),主要做下面三件事:
- 给
Singleton的实例分配内存。 - 调用
Singleton()的构造函数,初始化成员字段。 - 将
sInstnce对象指向分配的内存空间(此时sInstance就不是null了)。
由于Java编译器允许处理器乱序执行,以及JDK1.5之前JMM(Java Memory Model,即Java内存模型)中Cache、寄存器到主内存回写顺序的规定,上面的第二步骤和第三步骤是不能保证的,也就是说上述步骤的执行顺序可能是1-2-3也可能是1-3-2。如果是后者,并且在3执行完毕、2未执行的情况下,sInstance已经非null,此时如果切换到B线程,由于sInstance已经非null,所以线程B会直接取走sInstance,再使用时候会出错,因为他的成员字段还未初始化,这就是DCL失效问题的原因。
那么,该 如何解决 DCL失效问题呢?SUN官方在JDK1.5之后调整了JVM,具体化了volatile关键词,因此在JDK1.5或者之后的版本中只要将sInstance的定义修改成private volatile static Singleton sInstance = null;就可以保证sInstance对象每次都是从主内存里读取,继而解决了DCL失效的问题。
那么,volatile解决这个问题的原理是什么呢?原因是volatile的两个特性:
- 保证了此变量的对所有线程的可见性,当一个线程修改了这个变量的值,新值对于其他线程是立即可见的。而普通的变量的值在线程间传递均需要通过主内存来完成,例如,线程A修改了一个普通变量的值,然后向主内存进行回写,另外一个线程B在线程A回写完成了之后再从主内存进行读取操作,新变量值才会对线程B可见。
volatile禁止指令重排序优化,普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中执行的顺序一致。通过查看汇编代码会发现,加了volatile的时候,汇编代码会多执行一个lock操作,这个操作相当于一个内存屏障(指重排序的时候不能把后面的指令重排序到内存屏障之前的位置),这个lock的作用是使得本CPU 的Cache写入了主内存,相当于对Cache中的变量做了一次store和write操作,该写入操作也会引起别的CPU或者别的内核无效化其Cache,通过这个操作,可以使得volatile变量的修改对其他CPU立即可见。
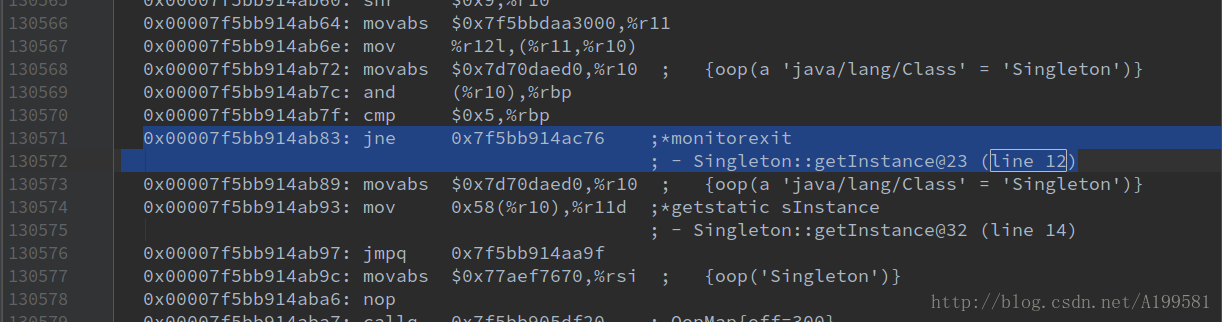
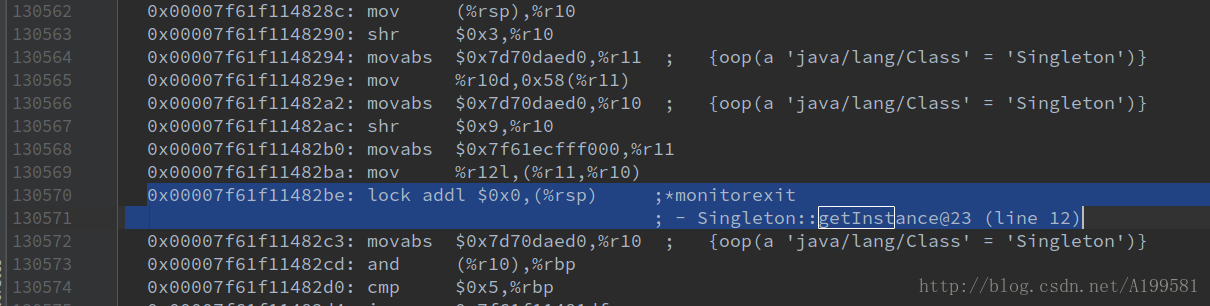
下面附上本篇博文中DCL实现单例模式的汇编代码(如何查看class的汇编代码请看补充3)
1、没有加 volatile关键字
2、加了 volatile关键字
补充 3、查看class文件的汇编代码
先说一下我的环境:
Open Jdk1.7
Ubantu 16.04
(其他环境请点这个链接或者这个链接)。
下面是详细步骤
- 在单例模式代码中加入main方法,里面需要调用
getInstance方法,完整代码如下:
public class Singleton {
private static volatile Singleton sInstance;
private Singleton() {
}
public static Singleton getInstance() {
if (sInstance == null) {
synchronized (Singleton.class) {
sInstance = new Singleton();
}
}
return sInstance;
}
public static void main(String[] args) {
//这里必须要调用getInstance方法,调用后才会对其进行编译,从而才能查看汇编代码。
Singleton.getInstance();
}
}- 终端执行
sudo apt-get install libhsdis0-fcml,目的是下载缺少的库。 - 终端执行
java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,*Singleton.getInstance -Xcomp Singleton > 1.txt,执行完这步,便可以在文件 1.txt 里查看汇编代码了(java -XX参数的设定可以参考这里)。
学习资料:
- 《设计模式之禅》;
- 《Android 源码设计模式解析与实战》;
- 《深入理解Java虚拟机》;














 2904
2904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









