原文链接
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
今天我们就以JAVA抓取网站一个页面上的全部全部邮箱为例来做具体说明,人一直很懒,不在做GUI了,大家看看明白原理就行。
——————————————————————————————————————————————————
百度上随便找一个网页,又想多的最好,这次以 点击打开链接 这个贴吧网页为例进行说明
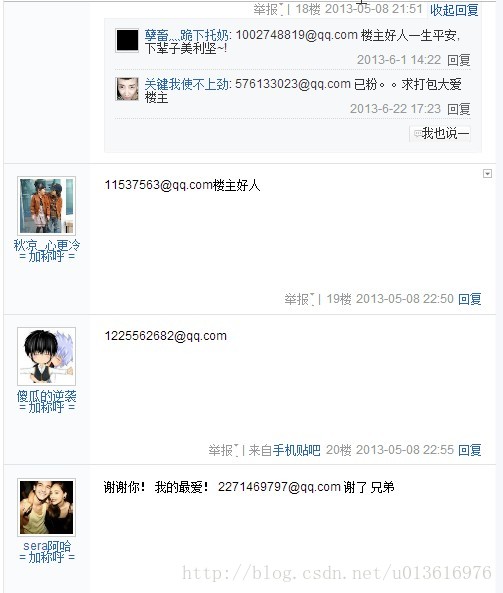
从图片和网页可见上面有许多邮箱,我粗略看了看十几页大概有几百个吧,如果你是楼主你肯定很难办,你要是一个一个发吧太多了工作量太大了,一个一个邮箱的复制真的会累死人的。可是,如果你不发,肯定会被吧友鄙视。
怎么办呢?当然,如果有一个工具能过自动识别网页上的邮箱并将它们取出来那该多好啊……
他就是网页爬虫,可是按照一定的规则抓取网页数据,(像什么百度,谷歌 做SEO 大多是网页数据的抓取与分析)并将这些数据保存起来,方便数据的处理和使用。
废话太多,上教程‘。
—————————————————————————————————————————————————
思路分析:
1.要想获取网页的数据必须取得与网页的链接
2.要想获得网页上的邮箱地址必须由获得邮箱地址相应的规则
3.要想把数据去除必须由取得数据相关类的操作
4.要想保存数据必须实现保存数据的操作
—————————————————————————————————————————————————
- package tool;
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileWriter;
- import java.io.InputStreamReader;
- import java.io.Writer;
- import java.net.URL;
- import java.net.URLConnection;
- import java.sql.Time;
- import java.util.Scanner;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class Demo {
- public static void main(String[] args) throws Exception {
- Long StartTime = System.currentTimeMillis();
- System.out.println("-- 欢迎使用飞扬简易网页爬虫程序 --");
- System.out.println("");
- System.out.println("--请输入正确的网址如http://www.baidu.com--");
- Scanner input = new Scanner(System.in);
-
- String webaddress = input.next();
- File file = new File("D:" + File.separator + "test.txt");
-
-
-
-
- Writer outWriter = new FileWriter(file);
-
- URL url = new URL(webaddress);
-
- URLConnection conn = url.openConnection();
-
- BufferedReader buff = new BufferedReader(new InputStreamReader(
-
- conn.getInputStream()));
-
- String line = null;
- int i=0;
- String regex = "\\w+@\\w+(\\.\\w+)+";
-
- Pattern p = Pattern.compile(regex);
-
- outWriter.write("该网页中所包含的的邮箱如下所示:\r\n");
- while ((line = buff.readLine()) != null) {
-
- Matcher m = p.matcher(line);
-
- while (m.find()) {
- i++;
- outWriter.write(m.group() + ";\r\n");
- }
- }
- Long StopTime = System.currentTimeMillis();
- String UseTime=(StopTime-StartTime)+"";
- outWriter.write("--------------------------------------------------------\r\n");
- outWriter.write("本次爬取页面地址:"+webaddress+"\r\n");
- outWriter.write("爬取用时:"+UseTime+"毫秒\r\n");
- outWriter.write("本次共得到邮箱:"+i+"条\r\n");
- outWriter.write("****谢谢您的使用****\r\n");
- outWriter.write("--------------------------------------------------------");
- outWriter.close();
- System.out.println(" —————————————————————\t");
- System.out.println("|页面爬取成功,请到D盘根目录下查看test文档|\t");
- System.out.println("| |");
- System.out.println("|如需重新爬取,请再次执行程序,谢谢您的使用|\t");
- System.out.println(" —————————————————————\t");
- }
- }
代码如上,每一行都有注释,实在看不懂的可以联系我。
直接在命令行下
编译-->运行
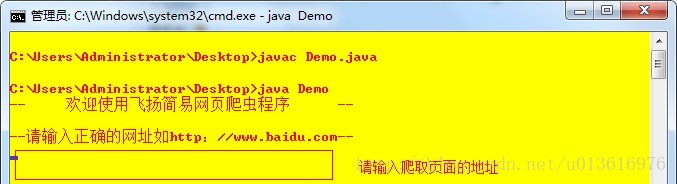
输入爬去取页面的地址。

打开D盘目录找到test.xt文件.
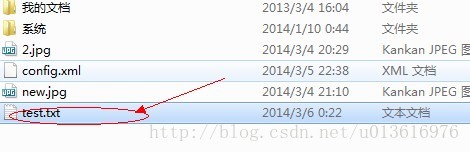
文件内的邮箱默认加上了“;”方便大家发送操作

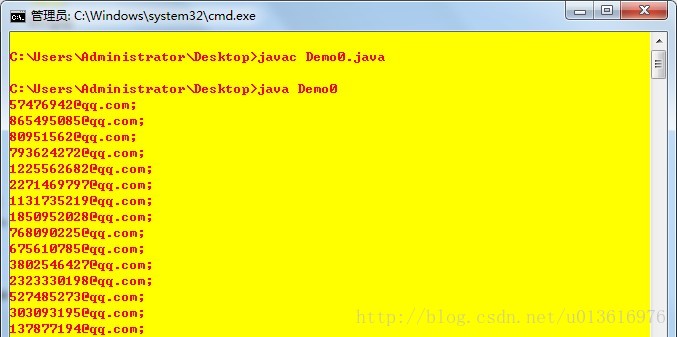
当然,爬取本地文件内的数据就更简单了
不再过多解释直接上代码。
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileReader;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class Demo0 {
- public static void main(String[] args)throws Exception {
- BufferedReader buff=new BufferedReader(new FileReader("D:"+File.separator+"test.txt"));
-
- String line=null;
- String regex="\\w+@\\w+(\\.\\w+)+";
- Pattern p=Pattern.compile(regex);
- while ((line=buff.readLine())!= null) {
- Matcher m=p.matcher(line);
- while (m.find()) {
- System.out.println(m.group()+";");
-
- }
- }
- }
- }























 8268
8268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









