







这两天在极客学院看视频,感觉在网上看好不方便,所以写了个爬虫来下载视频。
具体思路是:
1.先登录极客学院
2.获取指定页面中的课程网址
3.获取每个课程中的视频的地址
4.下载视频
首先要访问这个网址:
http://passport.jikexueyuan.com/sso/login然后post用户名、密码跟刚刚得到的参数导这个网址:
http://passport.jikexueyuan.com/submit/login?is_ajax=1
细心的人会发现,在网页登录时其实是有验证码的,其实之前也有写获取验证码,手动输入,后来因为验证码看不清楚,所以随便输入,发现也能登录成功,所以,其实验证码参数为空也是可以登录的。
最好是添加一个useragent
request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36')
我这里就不这么麻烦了,直接用正则表达式匹配里面是否含有“登录成功”来判断
之后就是获取课程网址,我用了多线程:
# 最多开4个线程
moreThread = 4
p = 1
while p <= page:
# len = threading.activeCount()
# if(len == moreThread):
# continue
if len(threads) == moreThread:
continue
thread = CourseUrlsThread(startUrl + str(p), workQueue, p)
thread.start()
threads.append(thread)
p += 1# 获取网址的线程类
class CourseUrlsThread(threading.Thread):
def __init__(self, url, q, i):
threading.Thread.__init__(self)
self.url = url
self.q = q
self.i = i
def run(self):
print('开始---获取第%d页的课程网址...' % self.i)
request = urllib.request.Request(self.url)
# 给一个useragent
request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36')
request = urllib.request.urlopen(request)
html = request.read().decode('utf-8')
request.close()
courseUrls = re.findall(r'class="lesson-info-h2"><a href="(.*?)"', html)
queueLock.acquire()
for courseUrl in courseUrls:
self.q.put(courseUrl)
threads.remove(self)
queueLock.release()
print('结束---第%d页的课程网址已获取...' % self.i)
time.sleep(1)# 存储视频的Path: 总路径/课程名/每一节的名称
urllib.request.urlretrieve(videoUrl, __folderPath + str(i) + name + '.mp4', self.reporthook)# 回调函数,显示下载进度
def reporthook(self, blocknum, blocksize, totalsize):
'''回调函数
@blocknum: 已经下载的数据块
@blocksize: 数据块的大小
@totalsize: 远程文件的大小
'''
percent = 100.0 * blocknum * blocksize / totalsize
if percent > 100:
percent = 100
downsize = blocknum * blocksize
if downsize >= totalsize:
downsize = totalsize
l = 0
s = '['
while l <= int(self.length * percent / 100):
s += "="
l += 1
l = 0
s += ">"
while l <= int(self.length * (100 - percent) / 100):
s += " "
l += 1
s += "]%.2f%%---" % (percent)
s += "%.2f" % (downsize / 1024 / 1024) + "M/" + "%.2f" % (totalsize / 1024 / 1024) + "M \r"
sys.stdout.write(s)
sys.stdout.flush()
if percent == 100:
print('')效果如下:
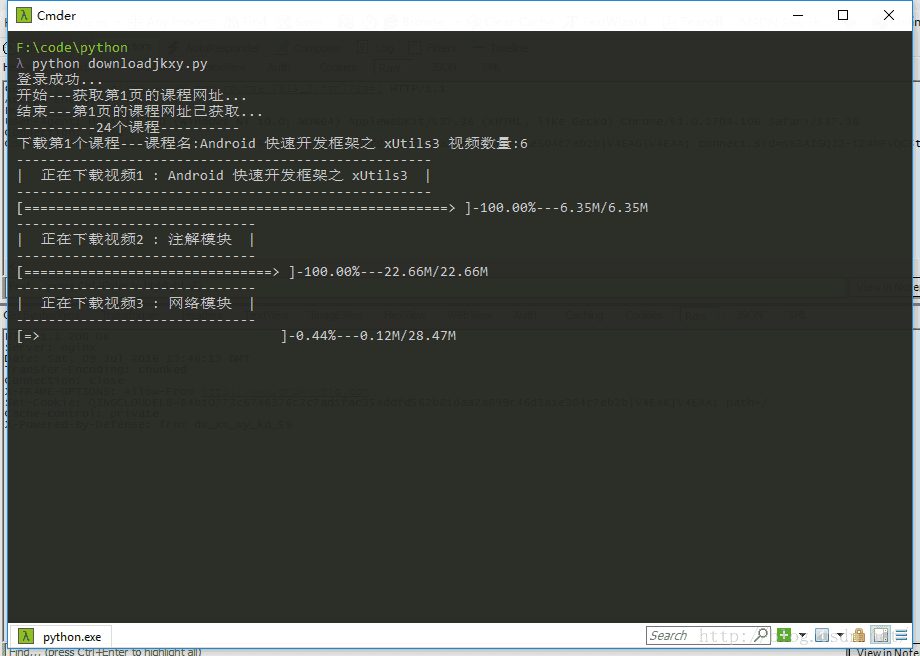
由于代码太多,这里就不多贴了,详细可以到git下载:














 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









