







第一章:E-R图
E-R图组成元素:对象(entity)、关系(relation)、属性、连接(对象与属性的连线)
E-R图可分为三种类型:1:1、1:m、m:n
1、1:1关系
两个对象的一一对应的关系,如丈夫对妻子、公民与身份证。
数学模型解释:y=x(一次函数)
映射关系:从左到右成立,从右到左也成立
2、1:m关系
一对多关系,如班级对学生
数学模型解释:y=x^2(二次函数)
3、m:n关系
多对多关系,如学生与课程(一名学生可以选多门课程,一门课程可以被多名学生选择)
数学模型解析:x^2+y^2=1(圆)
主键(primary key)设置原则:当无法找到主属性时,为实体添加ID
实体和关系都有属性:如学生实体包含学号、姓名等;学生实体与课程实体通过选课通过“选课”关系联系起来,选课也有属性,如学生名、课程名、成绩等。
名词解释:
关系:一张表
元组:表中的一行
属性:一列
候选码:能唯一确定一个元组
主码:多个候选码中,选一个作为关系的主码
E-R图向关系模型的转换
实体、实体的属性和实体之间的联系转换为关系模式:
(1)一个实体转换为一个关系模式(下划线表示主码)
学生(学号,姓名,年龄,性别)
班级(班级编号,班级名称)
课程(课程编号,课程名称,前置课程,学分)
身份证(身份证号,地址)
实体间的联系
(2)1:1联系转换为一个独立的关系模式,也可以于某一段实体对应的关系模式合并。
独立的关系模式:与该联系相连的各实体的码以及联系本身的属性 转换为 关系的属性,每个实体的码均是联系的候选码
举例(学生拥有身份证)
拥有(学号,身份证号)
合并:在关系模式的属性中中加入另一个关系模式的码和联系本身的属性
学生(学号,姓名,年龄,性别)
学生(学号,姓名,年龄,性别, 身份证号)
(3)1:m的联系 转换为一个独立的关系模式,也可以与m端对应的关系模式合并
独立的关系模式:与该联系相连的各实体的码以及联系本身的属性 转换为 关系的属性,关系的码为m端的码
举例(学生属于班级)
属于(学号,班级编号)
优化:具有相同码的关系模式可以合并
(4)m:n联系 与该联系相连的各实体的码以及联系本身的属性 转换为 关系的属性,关系的码为各实体码的组合
举例(学生选择课程)
选择(学号,课程编号,考试分数)
关系模式转化为关系模型
关系完整性:实体完整性、参照完整性、用户自定义完整性
实体完整性
若属性A时基本关系R的主属性,则属性A不能去空值
(1)实体完整性是针对基本关系而言的
(2)现实世界中,实体是可以进行区分的,即具有某种唯一的标识性
(3)关系模型中,以主码作为唯一标识
(4)主码中的属性即主属性不能取空值
参照完整性
现实世界中,实体之间往往存在着某种联系,在关系模型中,实体及实体之间的联系是用关系联系起来的。
(1)设置外键保证参照性
(2)填写外键值时保证该值在引用表中存在
用户自定义完整性
第二章 数据库
关系代数
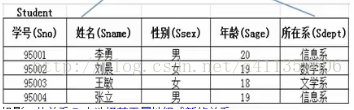
选择:又称限制。选择运算实际上是从关系R中选取逻辑表达式F为真的元组。
查询信息系的全体学生:δ Sdept=‘信息系’(student)
查询年龄小于20的信息系的学生信息:δSage<20&Sdept='信息系'(student)
投影:从关系R上选择若干属性组成新的关系
查询学生的姓名和所在的系 π SName,Sdept(student)
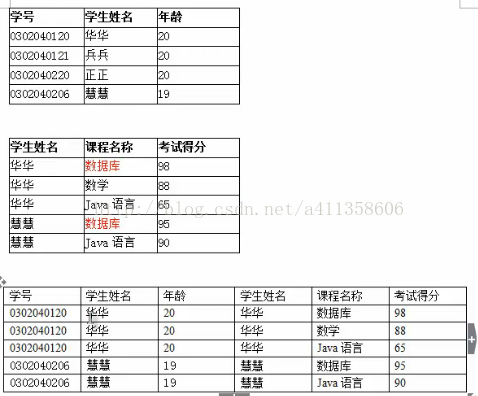
连接:从两个关联的表中选择属性间满足一定条件的元组
查询语句:
SELECT:投影[列1,列2,列3...,列n]
FROM:确定使用的关系R
WHERE:制定选择的条件
单表查询
SELECT 列1,列2....
FROM tablename
WHERE 条件1=true OR/AND 条件2=true
1、排序
order by
ASC 升序排列,默认
DESC 降序排列
2、范围
between and
3、模糊查询
like + 通配符
通配符:
% 任意多的任意字符
_ 一个任意字符
[a-z] 一个小写字母
[A-Z] 一个大写字母
[0-9] 一个数字
[^0-9] 一个非数字
4、为空判断
is null
连接:一般需要结合表中的外键,将外键作为表连接的条件
内连接 inner join
语法:select column1,column2,,,column from table ta inner join table tb on ta.colum = tb.colum
左外连接 left join
以左表为参照,右表中有满足条件的信息则显示信息,如果没有,则用null代替
语法:SELECT * FROM table ta LEFT JOIN table1 tb ON ta.id = tb.id
右外连接 right join
视图
一般情况下:视图只用来查询
分页
函数:limit
要素:起始的位置,选择的条数
SELECT * FROM vw_student_course_score LIMIT 1,1
聚合函数:能达到一定的数学运算目的,如求和、统计、平均值、最大值、最小值
特点:每一种函数,返回的值都是一个统计值
函数:求和->sum(expression | 经过运算的expression),
统计->count(expression | 经过运算的expression),
平均值->avg(expression),
最大值->max(expression),
最小值->min(expression)
分组查询:结合了普通查询和聚合函数
要点:1、聚合函数;2、分组
语法:group by
1、除了 聚合函数外,select中其他部分都应该出现在group by中作为分组的依据
2、对于分组之后的结果进行筛选,使用的不再是where,而是having
SELECT SName,CourseName,AVG(Score) FROM vw_student_course_score
[WHERE Score > 90]
[GROUP BY SName]
[HAVING AVG(Score) > 94]
[ORDER BY AVG(Score) DESC]
注:方括号表示可省略
插入数据:insert into
修改数据:update
删除数据:delete
INSERT INTO table(colum1,colum2,...,colum) VALUES (value1,value2,...,value)
注意点:1、value与column一一对应,数量、类型
2、可以为空列,指定NULL
UPDATE table SET colum1=value1,colum2=value2,...,colum=value WHERE CONDITION
注意点:1、一定要提供where条件
DELETE FROM TABLE WHERE CONDITION
注意点:1、一定要提供where条件
2、清空数据表不加where
数据库范式
数据规范:
1、数据必须不能继续拆分(原子性)········1NF
2、数据表中,不能存在对主码的部分依赖················2NF
姓名(学号、身份证号、班级编号)--------部分依赖 (班级编号 决定 班级名称,把班级名称去掉)
3、数据表中,不能存在对主码的传递依赖················3NF
学号-->班级编号-->所属系统(列三张表)
索引
1、维护建立在库中的一个有序的表
2、存储了每条记录的位置,类似于c语言中的指针
3、索引提升了查询的效率,但降低了数据的维护效率














 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









