







import nltk
from nltk.book import * #导入book这个语料
#text1.concordance('monstrous')
text4.dispersion_plot(["citizens","democracy","freedom","duties","America","you"])
#text4.generate()
len(text4)#获取文本长度
set(text3)#统计text3的词汇
sorted(set(text3))#统计text3的词汇并排序
len(set(text3))#统计text3的词汇并获取词汇表长度
text3.count("smote")#统计"smote"在文本中出现的次数
text5.count("lol")
#文本->词汇的链表
sent1=['I','love','you']
sent2 = ['I','love','you','too']
sent2.append('a')#追加
len(sent1+sent2)#可以使用加法连接多个链表
sent2[0]#根据索引访问
sent2[1:3]#切片
导入语料
在IDE中执行以下代码,把语料导入
from nltk.book import *

搜索文本
统计词汇分布
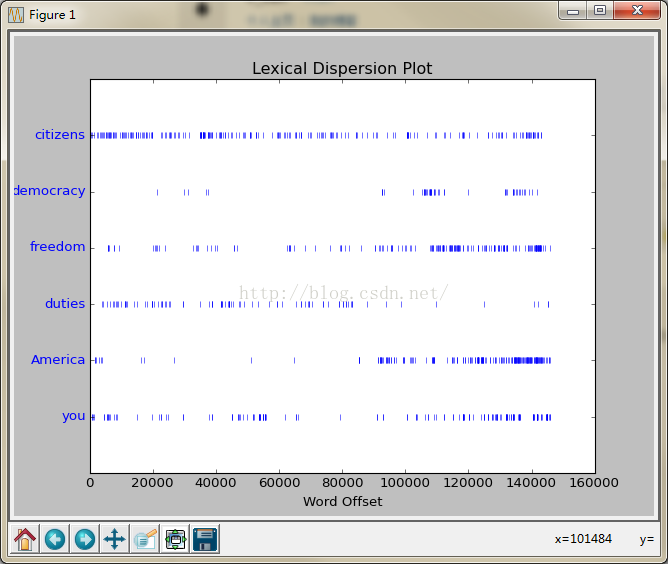
计数词汇
统计文本词汇表
统计text3的词汇并排序
统计text3的词汇并获取词汇表长度
统计"smote"在文本中出现的次数
把文本看作是词汇的链表














 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









