







nodejs + nginx + redis cluster 高并发解决方案
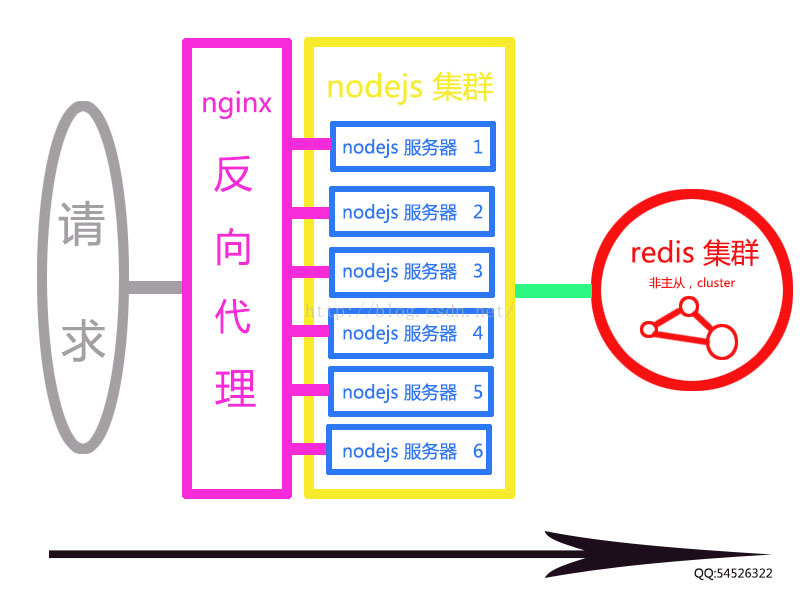
nodejs :应用服务器。
nginx :负载均衡反向代理。
redis cluster : 非主从的集群方案。
背景:
每当我们的应用服务,在网络上有许许多多的用户时。我们首先考虑到的是,我们的服务器能否承载同一时间高吞吐量的处理,我们的应用服务器架构应该如何去搭建。本文就是作者自己对于高性能web服务器的部分见解。
一、数据。
针对于用户使用数据而言,我们应该会对数据进行分级。例如简单的两级,用户会经常访问的(例如自己的id,地理信息);用户不会经常访问的(例如历史订单)。因此我们设计系统时就应该去考虑消除冗余,让经常使用的数据有更多的访问速度资源,不会经常使用的数据尽可能少的速度资源。最通俗的做法就是,经常访问的放在内存中,不经常访问的放入持久层,当然,经常访问的也应该在持久层中存根,不过用户访问的时候会先去访问内存中的数据,看是否是自己需要的。
传统的java 处理办法是在service中加个变量,缺点:
1.服务器挂掉后,登录状态和会话数据丢失,体验差。
2.java虚拟机自身缺陷,存储空间有限,需要进行jvm优化。
3.丢失后不可恢复,风险大。
面对传统的缺陷应运而生的 redis 主从处理方案出现了,它支持双机热备,1台处理,1台备份,在一定程度上可以防止数据丢失,对的你没看错,是一定程度上。为什么,分析下,在高并发环境中,一次吞吐量很大,主redis 正在处理新数据的时候挂掉了,从redis能一定保证把最新的数据备份下来了么?很显然不可能,所以一定会丢失。而且一台redis如果和n台web服务器交互,压力是很大的,挂掉的概率,啧啧啧。当然后来出现了keepalived 做负载均衡的,一定程度上减少了服务器的压力,但是这种方案,始终是下策(为什么是下策,如果两台服务器都有对方没有的新数据,突然挂掉了。。。再或者承载keepalived的这太机器出了问题。。。。)。风险还是太大了。
于是出现了redis cluster --集群,集群首先考虑的就是数据最小丢失,因此,采用的是数据分片技术,每台redis上存储的都是不同的数据,redis越多,数据分离的越细,一次丢失内容更少,没有代理层,性能稳定。XXXX等等一大堆优势,就不说了。
二、服务器集群只做数据处理,不做状态维持。
数据处理是很消耗计算机资源的,而状态维持相对较少。因此,大多高性能服务器都做状态和数据分离。nginx就是用来做会话状态维持,如图,整个系统中只有一个nginx。而会话状态中的数据,存储在redis集群中。
这里有个梗,如之前所说redis集群中,数据是以分片的形式存储在几台redis中,如果我需要的数据所在的redis正好挂掉了,怎么办。这就需要架构师对应用层编码进行规范,如何规范,需要专门的人员进行编写这种redis数据,数据提取策略是,如果这个数据从redis中获取不到,则直接从数据库中再次读取,再存储进入redis。
例如session对象内存储的数据,存储了一个user(点到为止,看不懂这个的,还需要多写写代码)。
废话不说了,上nginx配置代码(nginx如何配置安装,百度有大巴高手写过,小弟也是抄抄,不敢多写):
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 集群服务器配置
upstream sxt.com{
# weight 表示权重,其实就是被访问的概率。例如3002是3000的6倍是3001的3倍。
server 127.0.0.1:3000 weight=1;
server 127.0.0.1:3001 weight=2;
server 127.0.0.1:3002 weight=6;
}
server {
listen 80;
server_name localhost;
location / {
# 配置代理
proxy_pass http://sxt.com;
proxy_redirect default;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
作者只对跟负载均衡,反向代理相关的地方进行了注释。
这样配置之后,当访问nginx所在机器(例如192.168.1.200)的80端口时(http://192.168.1.200)
启动阿婆主的 nodejs服务器和 nginx服务器 并访问:
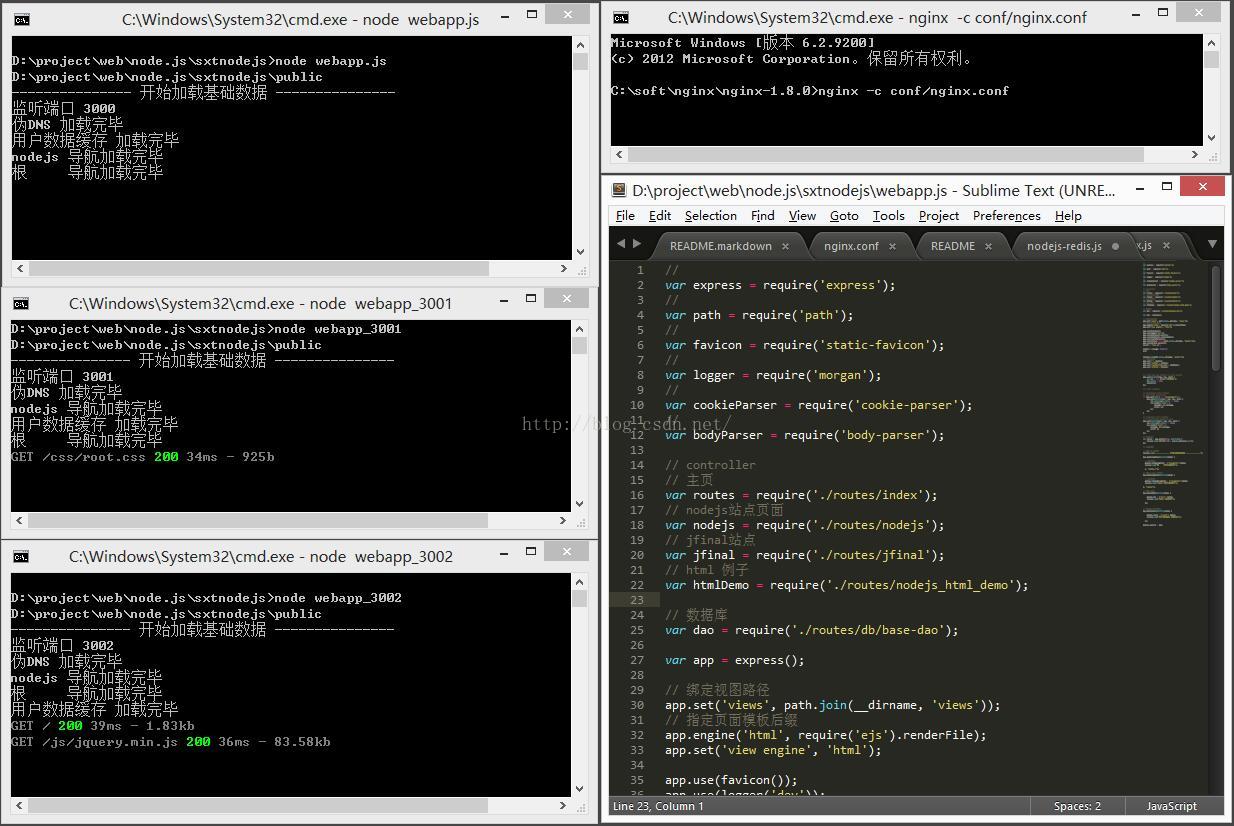
得到如上图中的结果:
发现---一共3次请求,3台nodejs服务器接受到的请求数目不相同。
一共请求了一个html 一个css文件和一个js文件。
这就是weight (权重)起到的作用。此时,面向客户的负载均衡和反向代理,已经部署完毕。由3台服务器共同承担一个定向地址的请求。
那么问题来了,如何知道这个用户是否登录过了呢?这个问题就是会话状态维持,会话状态实际上,是由session-cookies 来绑定维持的,做过移动的webView的同学应该都知道这个,所以,前端nginx和后端任意一台nodejs服务器都不用关心会话,因为这个数据是存储在redis集群上的,nodejs直接去集群上获取比对session-cookies数据,相同则登陆过,不同则没有登陆过,放心session-cookies是不会变的,因为用户是唯一与nginx进行交互的,只要nodejs或者如果java服务器程序猿,不去自己手动获取session对象,就能保证会话一致。
搞定了nginx 和 nodejs应用服务器之后,接下来就是nodejs服务器获取redis集群的部分了。
配置redis集群的方式,本文就不详述了,百度好多meet分片的文章。其实就是修改conf中几个参数,再手动修改分片文件进行分片就可以。当然也可以命令分片。

笔者在自己的虚拟机里,配置并启动了三台redis,构建成了一个cluster集群。
分别是:
192.168.1.200:7000
192.168.1.200:7001
192.168.1.200:7002
接下来就是需要注意的地方:
cluster集群与主从的redis有很大出入的地方:
1,java代码中:
import java.util.HashSet;
import java.util.Set;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
/***
* 测试redis
* @author sxt
*
*/
public class TestJedis {
/**
* @param args
*/
public static void main(String[] args) {
// 集群地址
Set<HostAndPort> jedisClusterNodes = new HashSet<HostAndPort>();
jedisClusterNodes.add(new HostAndPort("192.168.1.200", 7000));
jedisClusterNodes.add(new HostAndPort("192.168.1.200", 7001));
jedisClusterNodes.add(new HostAndPort("192.168.1.200", 7002));
// 实例化集群
JedisCluster jedis = new JedisCluster(jedisClusterNodes);
// 向集群中绑定值
jedis.set("name","shixiaotian");
// 从集群中获取值
String result = jedis.get("name");
// 输出结果
System.out.println(result);
}
}
如上图代码中所示,官方给出的最简单的获取方式中,cluster并没有让我们指定从哪台redis中获取数据。为什么?
redis cluster 采用的是数据分片技术,并没有热备份。每个数据都是存在固定的位置的,因此你访问任何一台机器,都会给你重新定向到存储你需要数据的那台redis上,所以不存在并发问题,因为,你横竖都得到这台机器上来。这与之前接触到的主从完全不一样,这里讲究的是分片后的最小丢失,主从讲究的是不丢失(想法总是很好的)。
因此,你完全不需要对cluster做负载均衡,集群自己处理(很赞,这才是合格的产品,屏蔽让别人觉得麻烦的东西,不需要自己去挂个代理了)。
nodejs中读取redis集群的方式也要进行相应的改变,为了区分两种的编码方式,下面都给出:
1.主从读取方式
//redis 链接
var redis = require('redis');
var client = redis.createClient('7000', '192.168.1.200');
// redis 链接错误
client.on("error", function(error) {
console.log(error);
});
// 向特定的redis机器上绑定数据
cluster.set('foo', 'bar');
// 从特定redis上获取数据
cluster.get('foo', function (err, res) {
console.log(res);
});// 注意,不一样的模块
var Redis = require('ioredis');
// 不一样的创建方式,多台获取,出来就是集群
var cluster = new Redis.Cluster(
[{
port: 7000,
host: '192.168.1.200'
}, {
port: 7001,
host: '192.168.1.200'
}, {
port: 7002,
host: '192.168.1.200'
}]
);
// 设置数据相同
cluster.set('foo', 'bar');
// 获取数据相同
cluster.get('foo', function (err, res) {
console.log(res);
});我们这里使用的是第二种方式,因为是cluster集群。
接下来,编写应用程序,所有使用到的session 数据,全部使用cluster中获取到的,或者存入的,即可。
对的。。你看见开篇第一章图上面的那个绿色的管子的么?有没有什么不一样。














 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









