






最近在阅读张良均、王路等人出版的书《python数据分析与挖掘实战》,其中有个案例是介绍航空公司客户价值的分析,其中用到的聚类方法是K-Means方法,我一直把学习的重心放在监督学习上,今天就用这个案例练习一下非监督学习。由于书上将这个案例介绍的比较详细,导致网上的好多博客都是直接将代码复制到博客上甚至是直接截图粘贴,还都说是自己原创, 真好笑。本文只是部分参考,不喜勿喷。
书中给出了关于62988个客户的基本信息和在观测窗口内的消费积分等相关信息,其中包含了会员卡号、入会时间、性别、年龄、会员卡级别、在观测窗口内的飞行公里数、飞行时间等44个特征属性。
为了便于观察数据,采用anaconda的notebook进行分析及可视化
首先导入分析中用到的各种第三方工具包
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt接着将数据读取到程序中,并查看每个特征属性的相关信息,以便对“脏”数据进行处理
datafile = "air_data.csv"
data = pd.read_csv(datafile, encoding="utf-8")
print(data.shape)
print(data.info())(62988, 44) <class 'pandas.core.frame.DataFrame'> RangeIndex: 62988 entries, 0 to 62987 Data columns (total 44 columns): MEMBER_NO 62988 non-null int64 FFP_DATE 62988 non-null object FIRST_FLIGHT_DATE 62988 non-null object GENDER 62985 non-null object FFP_TIER 62988 non-null int64 WORK_CITY 60719 non-null object WORK_PROVINCE 59743 non-null object WORK_COUNTRY 62962 non-null object AGE 62568 non-null float64 LOAD_TIME 62988 non-null object FLIGHT_COUNT 62988 non-null int64 BP_SUM 62988 non-null int64 EP_SUM_YR_1 62988 non-null int64 EP_SUM_YR_2 62988 non-null int64 SUM_YR_1 62437 non-null float64 SUM_YR_2 62850 non-null float64 SEG_KM_SUM 62988 non-null int64 WEIGHTED_SEG_KM 62988 non-null float64 LAST_FLIGHT_DATE 62988 non-null object AVG_FLIGHT_COUNT 62988 non-null float64 AVG_BP_SUM 62988 non-null float64 BEGIN_TO_FIRST 62988 non-null int64 LAST_TO_END 62988 non-null int64 AVG_INTERVAL 62988 non-null float64 MAX_INTERVAL 62988 non-null int64 ADD_POINTS_SUM_YR_1 62988 non-null int64 ADD_POINTS_SUM_YR_2 62988 non-null int64 EXCHANGE_COUNT 62988 non-null int64 avg_discount 62988 non-null float64 P1Y_Flight_Count 62988 non-null int64 L1Y_Flight_Count 62988 non-null int64 P1Y_BP_SUM 62988 non-null int64 L1Y_BP_SUM 62988 non-null int64 EP_SUM 62988 non-null int64 ADD_Point_SUM 62988 non-null int64 Eli_Add_Point_Sum 62988 non-null int64 L1Y_ELi_Add_Points 62988 non-null int64 Points_Sum 62988 non-null int64 L1Y_Points_Sum 62988 non-null int64 Ration_L1Y_Flight_Count 62988 non-null float64 Ration_P1Y_Flight_Count 62988 non-null float64 Ration_P1Y_BPS 62988 non-null float64 Ration_L1Y_BPS 62988 non-null float64 Point_NotFlight 62988 non-null int64 dtypes: float64(12), int64(24), object(8) memory usage: 21.1+ MB None
print(data[0:5])MEMBER_NO FFP_DATE FIRST_FLIGHT_DATE GENDER FFP_TIER WORK_CITY \ 0 54993 2006/11/02 2008/12/24 男 6 . 1 28065 2007/02/19 2007/08/03 男 6 NaN 2 55106 2007/02/01 2007/08/30 男 6 . 3 21189 2008/08/22 2008/08/23 男 5 Los Angeles 4 39546 2009/04/10 2009/04/15 男 6 贵阳 WORK_PROVINCE WORK_COUNTRY AGE LOAD_TIME ... \ 0 北京 CN 31.0 2014/03/31 ... 1 北京 CN 42.0 2014/03/31 ... 2 北京 CN 40.0 2014/03/31 ... 3 CA US 64.0 2014/03/31 ... 4 贵州 CN 48.0 2014/03/31 ... ADD_Point_SUM Eli_Add_Point_Sum L1Y_ELi_Add_Points Points_Sum \ 0 39992 114452 111100 619760 1 12000 53288 53288 415768 2 15491 55202 51711 406361 3 0 34890 34890 372204 4 22704 64969 64969 338813 L1Y_Points_Sum Ration_L1Y_Flight_Count Ration_P1Y_Flight_Count \ 0 370211 0.509524 0.490476 1 238410 0.514286 0.485714 2 233798 0.518519 0.481481 3 186100 0.434783 0.565217 4 210365 0.532895 0.467105 Ration_P1Y_BPS Ration_L1Y_BPS Point_NotFlight 0 0.487221 0.512777 50 1 0.489289 0.510708 33 2 0.481467 0.518530 26 3 0.551722 0.448275 12 4 0.469054 0.530943 39 [5 rows x 44 columns]
通过观测可知,数据集中存在票价为零但是飞行公里大于零的不合理值,但是所占比例较小,这里直接删去
data = data[data["SUM_YR_1"].notnull() & data["SUM_YR_2"].notnull()]
index1 = data["SUM_YR_1"] != 0
index2 = data["SUM_YR_2"] != 0
index3 = (data["SEG_KM_SUM"] == 0) & (data["avg_discount"] == 0)
data = data[index1 | index2| index3]
print(data.shape)(62044, 44)
删除后剩余的样本值是62044个,可见异常样本的比例不足1.5%,因此不会对分析结果产生较大的影响。
原始数据集的特征属性太多,而且各属性不具有降维的特征,故这里选取几个对航空公司来说比较有价值的几个特征进行分析,这里并没有完全按照书中的做法选取特征,最终选取的特征是第一年总票价、第二年总票价、观测窗口总飞行公里数、飞行次数、平均乘机时间间隔、观察窗口内最大乘机间隔、入会时间、观测窗口的结束时间、平均折扣率这八个特征。下面说明这么选的理由:
- 选取的特征是第一年总票价、第二年总票价、观测窗口总飞行公里数是要计算平均飞行每公里的票价,因为对于航空公司来说并不是票价越高,飞行公里数越长越能创造利润,相反而是那些近距离的高等舱的客户创造更大的利益。
- 当然总飞行公里数、飞行次数也都是评价一个客户价值的重要的指标
- 入会时间可以看出客户是不是老用户及忠诚度
- 通过平均乘机时间间隔、观察窗口内最大乘机间隔可以判断客户的乘机频率是不是固定
- 平均折扣率可以反映出客户给公里带来的利益,毕竟来说越是高价值的客户享用的折扣率越高
filter_data = data[[ "FFP_DATE", "LOAD_TIME", "FLIGHT_COUNT", "SUM_YR_1", "SUM_YR_2", "SEG_KM_SUM", "AVG_INTERVAL" , "MAX_INTERVAL", "avg_discount"]]
filter_data[0:5]| FFP_DATE | LOAD_TIME | FLIGHT_COUNT | SUM_YR_1 | SUM_YR_2 | SEG_KM_SUM | AVG_INTERVAL | MAX_INTERVAL | avg_discount | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2006/11/02 | 2014/03/31 | 210 | 239560.0 | 234188.0 | 580717 | 3.483254 | 18 | 0.961639 |
| 1 | 2007/02/19 | 2014/03/31 | 140 | 171483.0 | 167434.0 | 293678 | 5.194245 | 17 | 1.252314 |
| 2 | 2007/02/01 | 2014/03/31 | 135 | 163618.0 | 164982.0 | 283712 | 5.298507 | 18 | 1.254676 |
| 3 | 2008/08/22 | 2014/03/31 | 23 | 116350.0 | 125500.0 | 281336 | 27.863636 | 73 | 1.090870 |
| 4 | 2009/04/10 | 2014/03/31 | 152 | 124560.0 | 130702.0 | 309928 | 4.788079 | 47 | 0.970658 |
对特征进行变换:
data["LOAD_TIME"] = pd.to_datetime(data["LOAD_TIME"])
data["FFP_DATE"] = pd.to_datetime(data["FFP_DATE"])
data["入会时间"] = data["LOAD_TIME"] - data["FFP_DATE"]
data["平均每公里票价"] = (data["SUM_YR_1"] + data["SUM_YR_2"]) / data["SEG_KM_SUM"]
data["时间间隔差值"] = data["MAX_INTERVAL"] - data["AVG_INTERVAL"]
deal_data = data.rename(
columns = {"FLIGHT_COUNT" : "飞行次数", "SEG_KM_SUM" : "总里程", "avg_discount" : "平均折扣率"},
inplace = False
)
filter_data = deal_data[["入会时间", "飞行次数", "平均每公里票价", "总里程", "时间间隔差值", "平均折扣率"]]
print(filter_data[0:5])
filter_data['入会时间'] = filter_data['入会时间'].astype(np.int64)/(60*60*24*10**9)
print(filter_data[0:5])
print(filter_data.info())入会时间 飞行次数 平均每公里票价 总里程 时间间隔差值 平均折扣率 0 2706 days 210 0.815798 580717 14.516746 0.961639 1 2597 days 140 1.154043 293678 11.805755 1.252314 2 2615 days 135 1.158217 283712 12.701493 1.254676 3 2047 days 23 0.859648 281336 45.136364 1.090870 4 1816 days 152 0.823617 309928 42.211921 0.970658 入会时间 飞行次数 平均每公里票价 总里程 时间间隔差值 平均折扣率 0 2706.0 210 0.815798 580717 14.516746 0.961639 1 2597.0 140 1.154043 293678 11.805755 1.252314 2 2615.0 135 1.158217 283712 12.701493 1.254676 3 2047.0 23 0.859648 281336 45.136364 1.090870 4 1816.0 152 0.823617 309928 42.211921 0.970658 <class 'pandas.core.frame.DataFrame'> RangeIndex: 62988 entries, 0 to 62987 Data columns (total 6 columns): 入会时间 62988 non-null float64 飞行次数 62988 non-null int64 平均每公里票价 62299 non-null float64 总里程 62988 non-null int64 时间间隔差值 62988 non-null float64 平均折扣率 62988 non-null float64 dtypes: float64(4), int64(2) memory usage: 2.9 MB None没找到更好的处理timedatle的方法,这里自己用笨方法找了一下规律,暂且这样处理吧。
由于不同的属性相差范围较大,这里进行标准化处理
filter_zscore_data = (filter_data - filter_data.mean(axis=0))/(filter_data.std(axis=0))
filter_zscore_data[0:5]| 入会时间 | 飞行次数 | 平均每公里票价 | 总里程 | 时间间隔差值 | 平均折扣率 | |
|---|---|---|---|---|---|---|
| 0 | 1.441178 | 14.104488 | 0.609218 | 26.887901 | -0.975255 | 1.294751 |
| 1 | 1.312523 | 9.122093 | 1.806504 | 13.193844 | -1.006818 | 2.862354 |
| 2 | 1.333768 | 8.766208 | 1.821278 | 12.718386 | -0.996389 | 2.875087 |
| 3 | 0.663343 | 0.794378 | 0.764434 | 12.605032 | -0.618769 | 1.991687 |
| 4 | 0.390687 | 9.976218 | 0.636894 | 13.969099 | -0.652816 | 1.343389 |
def distEclud(vecA, vecB):
"""
计算两个向量的欧式距离的平方,并返回
"""
return np.sum(np.power(vecA - vecB, 2))
def test_Kmeans_nclusters(data_train):
"""
计算不同的k值时,SSE的大小变化
"""
data_train = data_train.values
nums=range(2,10)
SSE = []
for num in nums:
sse = 0
kmodel = KMeans(n_clusters=num, n_jobs=4)
kmodel.fit(data_train)
# 簇中心
cluster_ceter_list = kmodel.cluster_centers_
# 个样本属于的簇序号列表
cluster_list = kmodel.labels_.tolist()
for index in range(len(data)):
cluster_num = cluster_list[index]
sse += distEclud(data_train[index, :], cluster_ceter_list[cluster_num])
print("簇数是",num , "时; SSE是", sse)
SSE.append(sse)
return nums, SSE
nums, SSE = test_Kmeans_nclusters(filter_zscore_data)簇数是 2 时; SSE是 296587.688611 簇数是 3 时; SSE是 245317.292202 簇数是 4 时; SSE是 209299.798194 簇数是 5 时; SSE是 183885.938906 簇数是 6 时; SSE是 167465.10385 簇数是 7 时; SSE是 151869.163041 簇数是 8 时; SSE是 142922.824005 簇数是 9 时; SSE是 135003.92238
#画图,通过观察SSE与k的取值尝试找出合适的k值
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['font.size'] = 12.0
plt.rcParams['axes.unicode_minus'] = False
# 使用ggplot的绘图风格
plt.style.use('ggplot')
## 绘图观测SSE与簇个数的关系
fig=plt.figure(figsize=(10, 8))
ax=fig.add_subplot(1,1,1)
ax.plot(nums,SSE,marker="+")
ax.set_xlabel("n_clusters", fontsize=18)
ax.set_ylabel("SSE", fontsize=18)
fig.suptitle("KMeans", fontsize=20)
plt.show()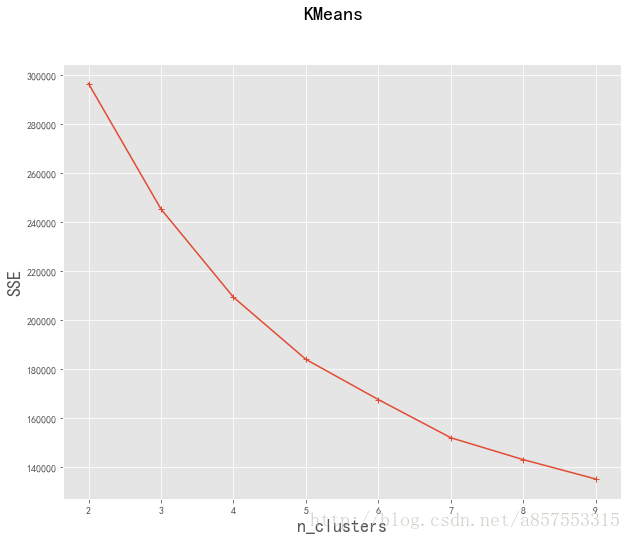
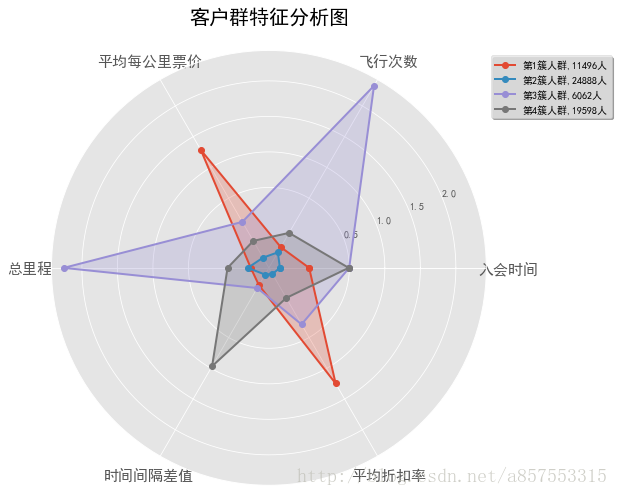
观察图像,并没有的所谓的“肘”点出现,是随k值的增大逐渐减小的,这里选取当k分别取4, 5, 6时进行,看能不能通过分析结果来反向选取更合适的值,k取值4时的代码如下
kmodel = KMeans(n_clusters=4, n_jobs=4)
kmodel.fit(filter_zscore_data)
# 简单打印结果
r1 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) #找出聚类中心
# 所有簇中心坐标值中最大值和最小值
max = r2.values.max()
min = r2.values.min()
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(filter_zscore_data.columns) + [u'类别数目'] #重命名表头
# 绘图
fig=plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, polar=True)
center_num = r.values
feature = ["入会时间", "飞行次数", "平均每公里票价", "总里程", "时间间隔差值", "平均折扣率"]
N =len(feature)
for i, v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面
angles=np.linspace(0, 2*np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭起来,需要下面的步骤
center = np.concatenate((v[:-1],[v[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 绘制折线图
ax.plot(angles, center, 'o-', linewidth=2, label = "第%d簇人群,%d人"% (i+1,v[-1]))
# 填充颜色
ax.fill(angles, center, alpha=0.25)
# 添加每个特征的标签
ax.set_thetagrids(angles * 180/np.pi, feature, fontsize=15)
# 设置雷达图的范围
ax.set_ylim(min-0.1, max+0.1)
# 添加标题
plt.title('客户群特征分析图', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True)
# 显示图形
plt.show()
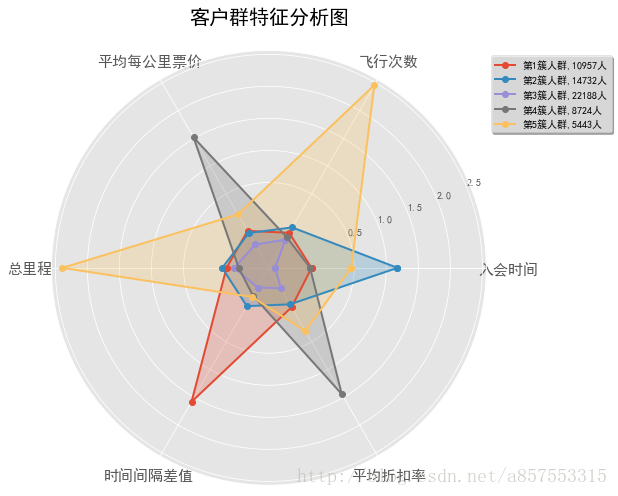
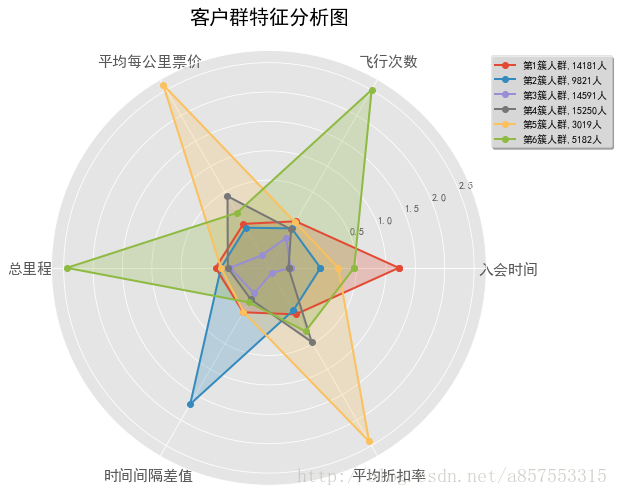
k取值5,6时的代码与上述类似,不再给出,直接给出结果图:
通过观察可知:
当k取值4时,每个人群包含的信息比较复杂,且特征不明显
当k取值5时,分析的结果比较合理,分出的五种类型人群都有自己的特点又不相互重复
当k取值6时,各种人群也都有自己的特点,但是第4簇人群完全在第5簇人群特征中包含了,有点冗余的意思
综上,当k取值为5时,得到最好的聚类效果,将所有的客户分成5个人群,再进一步分析可以得到以下结论:
- 1.第一簇人群,10957人,最大的特点是时间间隔差值最大,分析可能是“季节型客户”,一年中在某个时间段需要多次乘坐飞机进行旅行,其他的时间则出行的不多,这类客户我们需要在保持的前提下,进行一定的发展;
- 2.第二簇人群,14732人,最大的特点就是入会的时间较长,属于老客户按理说平均折扣率应该较高才对,但是观察窗口的平均折扣率较低,而且总里程和总次数都不高,分析可能是流失的客户,需要在争取一下,尽量让他们“回心转意”;
- 3.第三簇人群,22188人,各方面的数据都是比较低的,属于一般或低价值用户
- 4.第三簇人群,8724人,最大的特点就是平均每公里票价和平均折扣率都是最高的,应该是属于乘坐高等舱的商务人员,应该重点保持的对象,也是需要重点发展的对象,另外应该积极采取相关的优惠政策是他们的乘坐次数增加
- 5.第五簇人群,5443人, 总里程和飞行次数都是最多的,而且平均每公里票价也较高,是重点保持对象














 6142
6142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









