







 本文深入探讨了HashMap为何在多线程环境下会出现线程不安全的问题,详细解析了其内部结构及工作原理,特别是put操作和扩容机制,并指出了可能导致的数据丢失等问题。
本文深入探讨了HashMap为何在多线程环境下会出现线程不安全的问题,详细解析了其内部结构及工作原理,特别是put操作和扩容机制,并指出了可能导致的数据丢失等问题。
一直以来都知道HashMap是线程不安全的,但是到底为什么线程不安全,在多线程操作情况下什么时候线程不安全?
让我们先来了解一下HashMap的底层存储结构,HashMap底层是一个Entry数组,一旦发生Hash冲突的的时候,HashMap采用拉链法解决碰撞冲突,Entry内部的变量:
final Object key;
Object value;
Entry next;
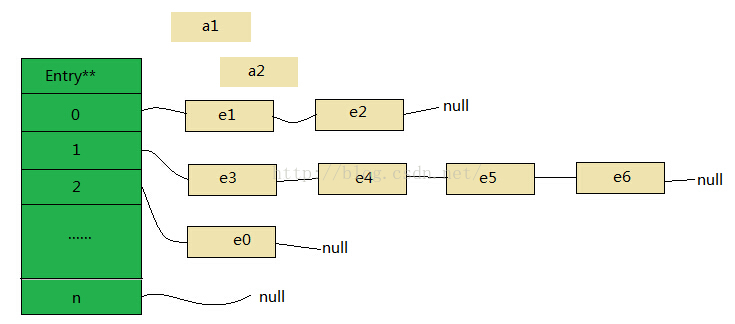
int hash;通过Entry内部的next变量可以知道使用的是链表,这时候我们可以知道,如果多个线程,在某一时刻同时操作HashMap并执行put操作,而有大于两个key的hash值相同,如图中a1、a2,这个时候需要解决碰撞冲突,而解决冲突的办法上面已经说过,对于链表的结构在这里不再赘述,暂且不讨论是从链表头部插入还是从尾部初入,这个时候两个线程如果恰好都取到了对应位置的头结点e1,而最终的结果可想而知,a1、a2两个数据中势必会有一个会丢失,如图所示:
再来看下put方法
public Object put(Object obj, Object obj1)
{
if(table == EMPTY_TABLE)
inflateTable(threshold);
if(obj == null)
return putForNullKey(obj1);
int i = hash(obj);
int j = indexFor(i, table.length);
for(Entry entry = table[j]; entry != null; entry = entry.next)
{
Object obj2;
if(entry.hash == i && ((obj2 = entry.key) == obj || obj.equals(obj2)))
{
Object obj3 = entry.value;
entry.value = obj1;
entry.recordAccess(this);
return obj3;
}
}
modCount++;
addEntry(i, obj, obj1, j);
return null;
}put方法不是同步的,同时调用了addEntry方法:
void addEntry(int i, Object obj, Object obj1, int j)
{
if(size >= threshold && null != table[j])
{
resize(2 * table.length);
i = null == obj ? 0 : hash(obj);
j = indexFor(i, table.length);
}
createEntry(i, obj, obj1, j);
}
void resize(int i)
{
Entry aentry[] = table;
int j = aentry.length;
if(j == 1073741824)
{
threshold = 2147483647;
return;
} else
{
Entry aentry1[] = new Entry[i];
transfer(aentry1, initHashSeedAsNeeded(i));
table = aentry1;
threshold = (int)Math.min((float)i * loadFactor, 1.073742E+009F);
return;
}
}可以看到扩容方法也不是同步的,通过代码我们知道在扩容过程中,会新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。
当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









