







用了三周的时间把斯坦福机器学习的视频过了一遍,根据自己记的随堂笔记同时参考海大黄博的个人笔记,想把机器学习的内容再好好梳理一下。刚刚接触这一块,有不足之处,欢迎批评指正!
机器学习是什么?机器学习是一种利用数据,训练出模型,然后使用模型预测输出的一种方法。“训练”产生“模型”,“模型”指导“预测”。机器学习存在不同类型的学习算法,最主要的两种类型是:监督学习和非监督学习。
监督学习的基本思想是,数据集中的每个样本都有相应的正确答案,根据这些样本拟合出模型,对数据进行预测。主要有线性回归、逻辑回归、神经网络、支持向量机等算法。
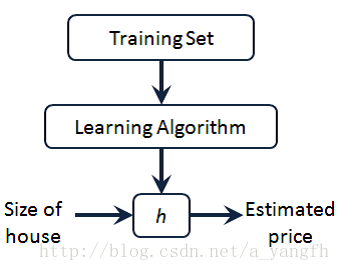
上图就是监督学习算法的工作方式,将训练集传给算法,算法拟合出假设函数,然后使用假设函数预测输入数据的结果。这里的输入数据就是房子的大小,然后预测房子的价格。
无监督学习是学习策略,交给算法大量数据,并让算法从数据中找出某种结构。主要有聚类、降维、异常检测等算法。
线性回归
这里要介绍的第一个算法是线性回归算法,它是一种监督学习算法。在介绍线性回归算法之前,先介绍下在机器学习中常用的变量及其简化的表达形式。
- m 代表训练集中样本的数量
n 代表特征的个数- x 代表输入变量,也叫特征变量
y 代表输出变量,也叫目标变量- (x,y) 代表训练集中的一个样本
- (x(i),y(i)) 代表第i个训练样本
-
x(i)j
代表第
i
个训练样本的第
j 个特征 - hθ(x) 代表学习算法中的解决方案,叫做假设函数
1、单变量线性回归
单变量指的是输入变量的特征只有一个,即只有一个特征参与模型的拟合。它的假设函数,也就是拟合出来的适应训练集的函数表达式为:
hθ(x)=θ0+θ1x
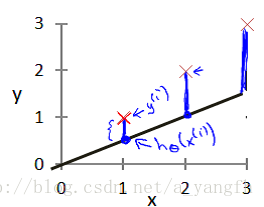
图中红色的点是训练样本,黑色的线是假设函数绘制出的线,红色点到假设函数的竖直方向的距离表示的就是目标变量与假设函数预测值之间的误差, 我们需要做的是通过合理的选择参数
θ 0
和
θ 1
,使假设目标变量与假设函数预测值之间的误差最小。这里引入了代价函数,代价函数也叫平方误差函数,其表达式为:
J(θ0,θ1)=12m∑mi=1(hθ(x(i))−y(i))2
优化目标就是通过合理的选择参数 θ 0 和 θ 1 ,使代价函数最小,优化目标表示为:
minimizeθ0,θ1J(θ0,θ1)
2、多变量线性回归
多变量线性回归是指输入变量的特征有很多个。它的假设函数表达式为:
hθ(x)=θ0+θ1⋅x1+θ2⋅x2+…+θn⋅xn
这个公式中有 n+1 个参数,特征矩阵X的维度是 m∗(n+1) ,目标变量的维度是 m∗1 。因此假设函数可以向量化简化为:
hθ(x)=θTX
代价函数:
J(θ0,θ1…θn)=12m∑mi=1(hθ(x(i))−y(i))2
3、特征和多项式回归
线性回归并不适用于所有数据,有时我们需要曲线来使用数据,比如一个二次方模型:
hθ(x)=θ0+θ1⋅x1+θ2⋅x22
或者三次方模型:
hθ(x)=θ0+θ1⋅x1+θ2⋅x22+θ3⋅x33
所以,通常需要先观察数据,然后再决定准备怎样的尝试。
求最优化目标常用的方法有两种:
梯度下降法
标准方程法
在下一篇博客里会做详细的介绍。














 4142
4142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









