







一、环境说明
scala-2.9.3
spark-0.8.1-incubating-bin-hadoop2
二、安装配置
2.1、
mkdir -p /opt/spark
tar -zxvf scala-2.9.3.tgz
ln -s scala-2.9.3 scala
修改/etc/profile
export SCALA_HOME=/opt/spark/scala
export PATH=$PATH:$SCALA_HOME/bin
tar -zxvf spark-0.8.1-incubating-bin-hadoop2.tgz
ln -s spark-0.8.1-incubating-bin-hadoop2 spark
修改 /etc/profile
export SPARK_HOME=/opt/spark/spark
export PATH=$PATH:$SPARK_HOME/bin
2.2、
cd /opt/spark/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_60
export SCALA_HOME=/opt/spark/scala
export HADOOP_HOME=/opt/hadoop
vi slaves
bigdata1
bigdata2
bigdata3
cp log4j.properties.template log4j.properties
同步
三、安装验证
启动Spark
cd $SPARK_HOME/sbin/
start-all.sh
3.1、Java进程
master上:
org.apache.spark.deploy.master.Master
slave上:
org.apache.spark.deploy.worker.Worker
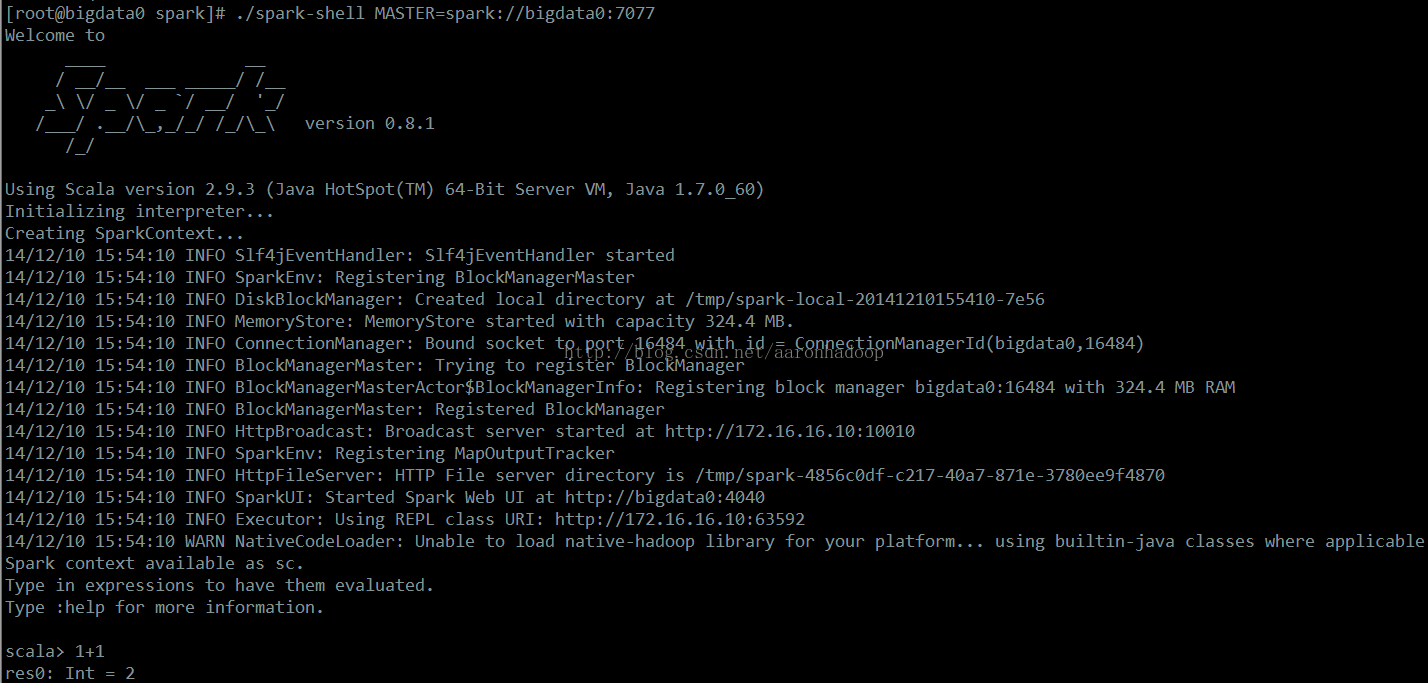
3.2、进入Spark shell
./spark-shell MASTER=spark://bigdata0:7077
3.3、Spark WebUI
http://bigdata0:8080

四、测试
(1)、本地模式
#./run-example org.apache.spark.examples.SparkPi local
(2)、普通集群模式
#./run-example org.apache.spark.examples.SparkPi spark://bigdata0:7077
#./run-example org.apache.spark.examples.SparkLR spark://bigdata0:7077
#./run-example org.apache.spark.examples.SparkKMeans spark://bigdata0:7077 file:/home/jianxin/spark/kmeans_data.txt 2 1
(3)、结合HDFS的集群模式
进入Spark Shell交互界面
cd $SPARK_HOME
./spark-shell MASTER=spark://bigdata0:7077
scala> val file = sc.textFile("hdfs://bigdata1:9000/wordcount/wc_in/test1.txt")
scala> val count = file.flatMap(line => line.split("\t")).map(word => (word, 1)).reduceByKey(_+_)
scala> count.collect()
scala> count.saveAsTextFile("hdfs://bigdata1:9000/wordcount/wc_out6")
scala> :quit
(4)、基于YARN模式
# SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly_2.9.3-0.8.1-incubating-hadoop2.2.0.jar \
./spark-class org.apache.spark.deploy.yarn.Client \
--jar examples/target/scala-2.9.3/spark-examples_2.9.3-assembly-0.8.1-incubating.jar \
--class org.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers 3 \
--master-memory 4g \
--worker-memory 2g \
--worker-cores 1
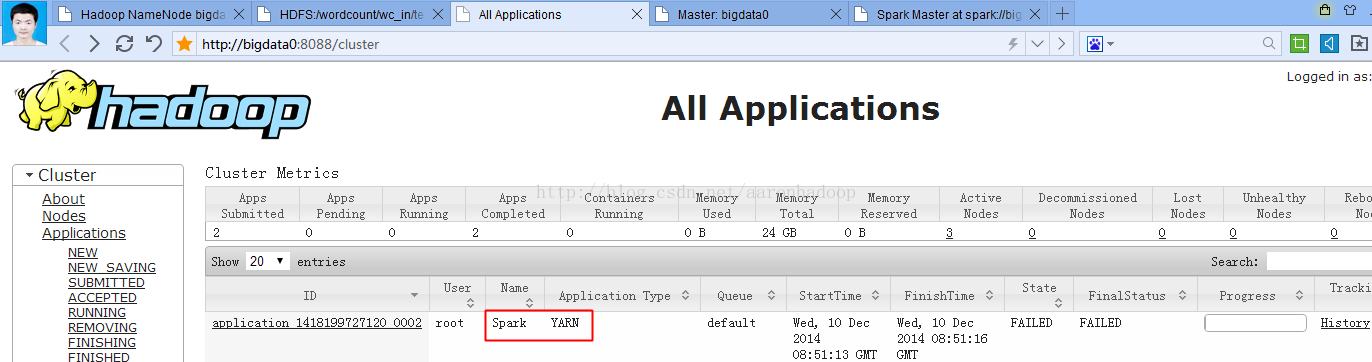
Application report from ASM:
application identifier: application_1418199727120_0002
appId: 2
clientToAMToken: null
appDiagnostics: Application application_1418199727120_0002 failed 2 times due to AM Container for appattempt_1418199727120_0002_000002 exited with exitCode: -1000 due to: java.io.IOException: Resource file:/opt/spark/spark-0.8.1-incubating-bin-hadoop2/examples/target/scala-2.9.3/spark-examples_2.9.3-assembly-0.8.1-incubating.jar changed on src filesystem (expected 1386716856000, was 1418192873000
.Failing this attempt.. Failing the application.














 3482
3482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









