







索引结构图:
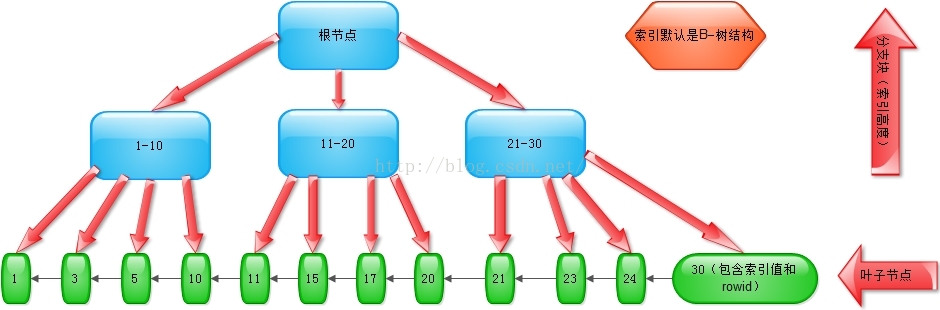
B-树索引实现类似于倒置的树形结构,包括根节点,分支节点,叶子节点,并且使用树遍历算法来搜索列值。叶子节点中包含一对值(索引值,行编号rowid),索引值对应索引键列,行编号则表示行在表中数据块中内存地址;分支节点包含叶子几点目录及存储在其中叶子节点的值范围;根节点包含分支节点目录以及这些分支节点所包含的值范围。
B-树索引适合于具有较低选择度的列。如果列的选择度不够低,索引扫描就会很慢。并且,选择度不够低的列将会从叶子块中取出大量的行编号从而导致对表进行过多的但数据块访问,从而降低效率。
索引默认按升序排列。
索引分类:
默认的索引类型B-树;索引建立在表中的一个或多个列或者列的表达式上,将列值和行编号(rowid)一起存储。
在索引中,除了存储每个索引值外,还存储此索引对应行的rowid;
索引扫描的步骤:a、扫描索引找到对应的rowid值;b、通过rowid从表中读到具体数据;
rowid:唯一标示一行数据(该数据实际存储地址),该行对应的数据块是通过一次I/O得到的,此情况下该次I/O只会读取一个块;rowid包含2个地址:一个是该行所在数据块的地址;另一个是可以直接定位到数据行自身在这个数据块中的地址;
rownum:查询结果集对应的伪列;
1、table access full 全表扫描;
全表扫描(和快速全扫描)时,为了提高系统吞吐量,减少I/O次数,oracle采用一次读入多个数据块,提高全表扫描效率;
注意:只要在全表扫描时,才使用一次读入多个数据快;
2、table access by index rowid 通过rowid扫描;
表明对于表数据块的访问。
3、index scan 索引扫描;
3.1、index range scan 索引范围扫描;
在唯一索引上使用索引范围扫描的情况是:where限制条件中使用了:>, <, <>, >=, <=, between时;
在非唯一索引上使用“=”也可能返回多条数据,所以在非唯一索引上都使用索引范围扫描;
使用索引范围扫描的3中情况:
a、在唯一索引上使用range操作符(>, <, <>, >=, <=, between);
b、在组合索引上,只使用了部分列查询,导致查询出多行;
c、在非唯一索引上进行任何查询;
3.2、index unique scan 索引唯一扫描;
当谓语中包含使用unique和primary key索引的列作为条件的时候就会选用索引唯一扫描。
3.3、index skip scan 索引跳跃扫描;
当谓语中包含位于索引中非引导列上的条件,并且引导列的值是唯一的时候;
3.4、index full scan 索引全扫描;
索引全表扫描将会扫描索引结构中的每一个叶子块,读取每个条目的行编号(rowid),并取出数据行;
索引全表扫描通常比全表扫描效率高,因为每一个索引快要比表数据块包含更多的条目,从而总的需要访问的块数也就相应的较少;
几种情况下将会使用:a、没有谓语但是所需获取的列的列表可以通过其中一列的索引来获得;
b、谓语中包含一个位于索引中非引导列的条件;
c、数据可以通过一个排过序的索引来获取并且会省去单独的排序步骤;
3.5、index full fast scan 索引快速扫描;
当选择用索引快速扫描时,所有的索引块都将通过多块读取来读取;
索引快速扫描并不能用来避免排序,因为数据块是通过无序的多块读取来读取的;
使用情况:当用来在查询列表中所有字段都包含在索引中并且索引中至少有一列具有非空约束时替代全表扫描的;
分页查询优化:
oracle如何查看执行计划:plsql工具的explain window;命令窗口执行sql:
打开set autotrace traceonly explain;执行sql;关闭set autotrace off;
大数据表分页查询优化:最近在做迁移数据,一个表有150万条数据,分页查询出来,然后多线程结构化数据,插入新表中。跑了14个小时,只迁移了一半左右。一看日志时间都花费在了查询数据上。刚开始执行时,每分钟迁移有8000条左右,到早上过来看,每分钟只有500条左右。
执行比较慢的原sql:
select *
from (select row_.*, rownum rownum_
from (select id, mid, fraud_result_string from t) row_
where rownum <= 40)
where rownum_ > 20b、查看执行计划是全表扫描:TABLE ACCESS FULL;
这个必须要优化下,不然跑到猴年马月:
优化方案一:优化后的sql,每页取500条,sql如下:先分页查询出主键ID(走 index fast full scan索引,相对快多了),然后根据ID找到这些记录。
select nfr.id, nfr.mid, nfr.result
from t nfr
where nfr.id in (
select s.id from
(select row_.*, rownum rownum_ from (select id from t) row_ where rownum <= #endNum#) s
where rownum_ > #startNum#)
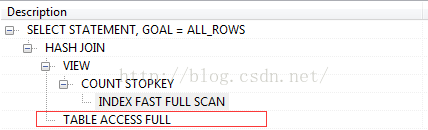
优化后的执行计划,似乎全是全部走索引,但实际不全是,在分页查询,页码比较小时,是这样;页码比较大时,会变成table access full。最后150万2个小时迁移完毕。
小页码时执行计划,如下图:
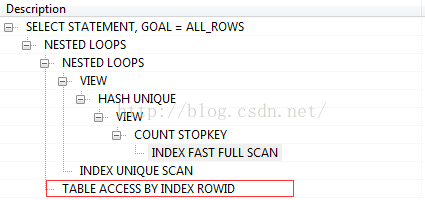
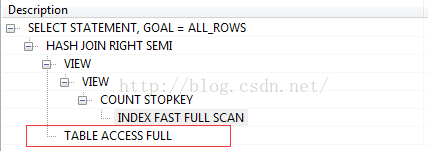
大页码的执行计划,似乎简洁了许多。如下图:
优化方案二:网上找的,使用rowid,这个方案没有实际测试效果,从执行计划看,比方案一要好。而且使用的rowid是数据记录存储的实际地址,获取记录会更快些。优化sql如下
select *
from t t1,
(select rid
from (select rownum rn, t.rid
from (select
rowid rid
from t
) t
where rownum <= 500)
where rn > 0) t2
where t1.rowid = t2.rid小页码执行计划,如下图:
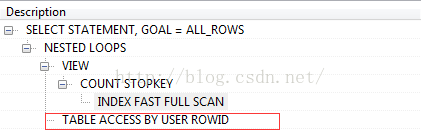
大页码执行计划,如下图:














 3611
3611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









