









1.背景介绍:
现在很多网页都采用AJAX这种异步加载的网页结构,简单的页面爬取不了这些数据。如http://book.qidian.com/info/1003354631,里面的评分信息,
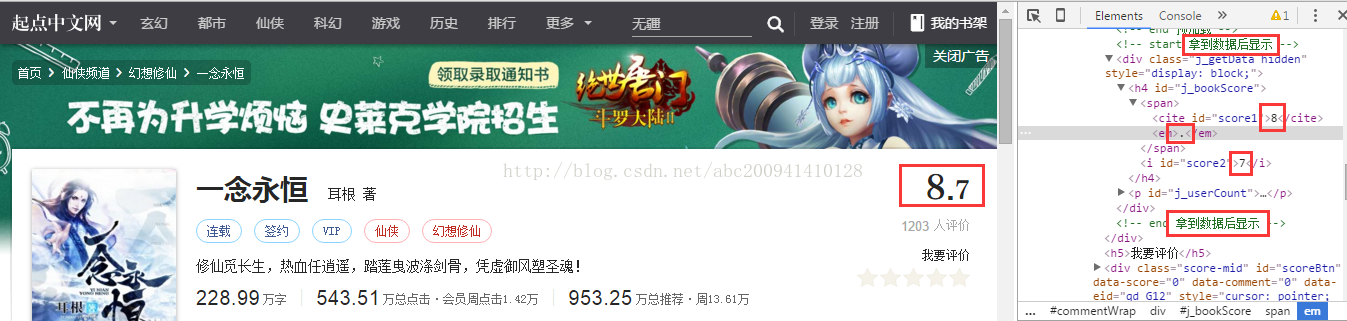
我们在浏览器看到的评分和评价人数是加载后的信息;查看源代码的话,会发现是没有数据的

实际情况是否如此呢?我们开始试试是抓到的是8.7分,还是0.0分,首先常规直接抓取
library(XML)
library(RCurl)
library(rvest)
URL="http://book.qidian.com/info/1003354631"
doc<-htmlParse(URL,encoding="UTF-8")
rootNode<-xmlRoot(doc)
book_name<-xpathSApply(rootNode,"//div[@class='book-information cf']/div/h1/em",xmlValue)#书名
author<-xpathSApply(rootNode,"//div[@class='book-information cf']/div/h1/span/a",xmlValue)#作者
scores=xpathSApply(rootNode,"//div[@class='book-information cf']/div/div/div/h4",xmlValue)#评分
votes=xpathSApply(rootNode,"//p[@id='j_userCount']/span",xmlValue)#评价人数
book_name
#一念永恒
author
#耳根
scores
#0.0
2、包RSelenium包和Rwebdriver的介绍安装
RSelenium和Rwebdriver作用是用R调用Selenium Server。而什么又是Selenium Server呢?Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击,滚动,滑动,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来替代人工进行测试一个开发软件的各种功能。在处理爬虫任务中,经常遇到需要输入文字,进行下拉菜单选择,以及鼠标点击等情景。Selenium Server允许你在不同的浏览器上打开网址,对网页进行操作,并爬取网页元素的独立JAVA程序。在处理爬虫任务中,经常遇到需要输入文字,进行下拉菜单选择,以及鼠标点击等情景。通过Selenium Server我们可以对网页进行操作,然后爬取操作后的数据,从而进行爬取动态页面。
RSelenium和Rwebdriver个人刚接触不久,除了语法不太一样以为,都是调用的Selenium Server。一个是2012年发布的包,一个是比较新的包需要在github下载。个人推荐使用Rwebdriver,不仅因为新,跟python里的RSelenium函数很多非常相似。也是《Automated_Data_Collection_with_R》推荐的包。这里以此包为例说一下。
安装配置安装jre:
下载地址:http://www.Java.com/en/download/manual.jsp#win
配置jre环境变量这个也一堆资料,自己上网搜索哈(https://jingyan.baidu.com/article/09ea3ede2b5f86c0aede39b9.html)
下载selenium,并放至指定位置下载地址:
http://www.seleniumhq.org/download/
启动selenium打开命令提示符进入selenium所在路径
输入java -jar selenium-server-standalone-3.4.0.jar
启动selenium,
【注意】最好将相应浏览器的驱动也下载好,在selenium下载页面的“Third Party Drivers, Bindings, and Plugins”,下载相应的驱动,建议直接放到相应浏览器的安装文件地址,并且配好环境变量(将浏览器安装地址添加到环境变量上)即可。如果你浏览器已经有了驱动也就不需要这一步了,我自己的是需要的。
R安装包
library(devtools)#如果没有安装要下载安装
install_github(repo = "Rwebdriver", username = "crubba")准备完成开始抓取!!!
3、代码实现
library(XML)
library(RCurl)
library(rvest)
library(Rwebdriver)
URL="http://book.qidian.com/info/1003354631"
start_session(root = "http://localhost:4444/wd/hub/", browser ="firefox")#启动浏览器
post.url(url=URL)#用浏览器打开网址
pageSource <- page_source() #存储浏览器的信息
#后面都跟常规爬取一样
doc<-htmlParse(pageSource,encoding="UTF-8")
rootNode<-xmlRoot(doc)
book_name<-xpathSApply(rootNode,"//div[@class='book-information cf']/div/h1/em",xmlValue)#书名
author<-xpathSApply(rootNode,"//div[@class='book-information cf']/div/h1/span/a",xmlValue)
status<-xpathSApply(rootNode,"//div[@class='book-information cf']/div/p[1]/span[1]",xmlValue)#只取第一个,看是否完结
types<-xpathSApply(rootNode,"//div[@class='book-information cf']/div/p[1]/a[1]",xmlValue)#只取第一个,看什么类型小说
words=xpathSApply(rootNode,"//div[@class='book-information cf']/div/p[3]/em[1]",xmlValue)#看多少万字
cliks=xpathSApply(rootNode,"//div[@class='book-information cf']/div/p[3]/em[2]",xmlValue)#看多少万点击
reoms=xpathSApply(rootNode,"//div[@class='book-information cf']/div/p[3]/em[3]",xmlValue)#看多少万推荐
scores=xpathSApply(rootNode,"//div[@class='book-information cf']/div/div/div/h4",xmlValue)#看评分
votes=xpathSApply(rootNode,"//p[@id='j_userCount']/span",xmlValue)#看平均人数
quit_session()
score
#8.7
votes
#1203不仅python能抓取负责页面,R也可以。不过R需要保证selenium一直处于启动状态。
Rwebdriver的一些函数如下截图:
具体教材,参看《Automated_Data_Collection_with_R》第9.19节。
下次再说python中用selenium!!!用浏览器模拟速度比较慢。还在优化。
本人第一篇博客,写的简陋,慢慢会改正。
下次再说python中用selenium!!!用浏览器模拟速度比较慢。还在优化。
本人第一篇博客,写的简陋,慢慢会改正。














 4321
4321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









