







一、前言
很以前就搭建过hadoop的伪分布式环境,为了搭建环境特意弄的双系统,还把毕业论文给毁了。不过当时使用的是 hadoop1.x 的,而且因为一些原因,就搭建了环境,而没继续学习了。现在开始,准备好好的学习一下hadoop
二、Hadoop 简介
- Hadoop 是Apache软件基金会旗下的一个开源分布式计算平台
- 是云计算中 PaaS(平台即服务)一层的实现
- HDFS 和 MapReduce 共同组成了Hadoop分布式系统体系结构的核心
注:hadoop 具体介绍,留待以后说,现在主要介绍环境搭建
三、Hadoop 环境搭建
虽然hadoop目前主要分为两种版本,1.x 和 2.x。二者有区别,但是在环境搭建中,其步骤基本还是一致的。
主要分为如下4步:
1. 修改主机名
2. 配置 SSH 无密码登录
3. 安装Java
4. 安装Hadoop
注:当然,还可以加上一步,就是创建 hadoop 用户和 hadoop 用户组。不过,由于本人使用的是腾讯云服务器 CenOS6.5 系统,上面 su 命令找不到,因此,省去了这一步,而直接使用 root 用户操作
3.1 修改主机名
修改主机名
在终端上,执行命令 vi /etc/sysconfig/network,将主机名改为 hadoop(你自己喜欢就行).

重启系统,查看主机名
修改好后,我们需要重启系统,以使刚刚的配置生效。重启后,我们通过命令查看配置是否生效了。执行命令:hostname

从结果中可以看到,配置成功了。
让 ip 绑定主机名
配置好主机名后,我们接下来就应该让系统的 ip 与主机名绑定了。(这也是为什么要修改主机名的原因之一)。执行命令:vi /etc/hosts

注:我们可以通过 ipconfig 查看到我们机器的 ip 地址是多少,以此来配置。当然,对于云服务器,我们也可以从云服务器控制台看到 ip,不过,记住是使用私网 ip,而不是公网 ip
3.2 配置 SSH 无密码登录
生成私钥和公钥
执行命令:ssh-keygen -t rsa,一路回车就行
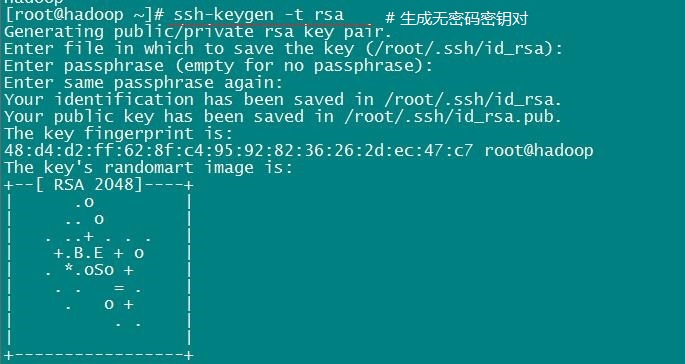
命令执行完毕后,会在当前用户目录下生成一个 .ssh 的目录

追加授权,生成 authorized_keys
切换到 .ssh 目录下,执行命令:cp id_rsa.pub authorized_keys,这样,我们就把 id_rsa.pub 追加到授权的 key 里面了

注:
① 该文件最高权限必须是 644 或者 600
② 文件名必须是 authorized_keys,不能改
测试
执行命令:ssh localhost,结果如下:

我们发现,它居然要我们输入密码!这是为啥?原因很简单,因为我们在使用 SecureCRT 连接云服务器时,启动了密码认证,而 root 用户这时是有密码的。因此我们准确的输入密码,就好了。
不过,问题在于,这样就表示我们 SSH 无密码登录还是失败了。当我们启动 Hadoop 时,各守护进程的启动时,需要手动键入密码,很蛋疼。。如下:

查看 .ssh 目录
重新切入到 .ssh 目录下,然后执行 ls -al,发现新出来了一个文件 knwo_hosts,查看其内容可以看到如下所示:

补充:为什么要进行 SSH 无密码登录?
因为 Hadoop 运行过程中需要管理远端Hadoop守护进程,NameNode 在管理 DataNode 时,以及 JobTracker 和 TaskTracker 之间,使用的通信协议就是 SSH 协议。 SSH 无密码登录的配置,可使得伪分布式环境下,Hadoop各守护进程之间进行联系时,不需要输入密码认证。所以需要配置无密钥登录,否则每次都需要手工输入密钥
注:所有守护进程彼此间是使用 SSH 协议进行通信的
补充:为什么会出现 ssh 无密钥登录认证失败?以及解决办法
对于SSH无密钥配置失败,最首先我没管,因为反正是使用云服务器,启动一次 hadoop 不关掉就好了。后面还是花时间排查了下错误,改好了。
故障排查:我们发现云服务器控制台中,SSH公钥和我们当前.ssh 下 id_rsa.pub 中的是一样的,那么为什么还是失败?经仔细排查,我们发现问题就在于之前我们使用 SecureCRT 进行远程登录云服务器时,我们使用的是密码认证,我们启动了 PasswordAuthentication yes,就是这个配置,让我们的 SSH 无密钥登录认证失败了。
既然知道了原因,那么事情就很好解决了。
① 修改 /etc/ssh/sshd_config 文件,执行命令:vi /etc/ssh/sshd_config
② 将 PasswordAuthentication 的 yes 改为 no,并启动另外三项配置。只需将前面的 # 号去掉就行
[具体配置]
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥认证
AuthorizedKeysFile .ssh/authorized_keys # 启用公钥认证
PasswordAuthentication no # 禁止密码认证
③ 我们再次执行 ssh-keygen -t rsa,覆盖掉之前的文件,并使用 cp id_rsa.pub authorized_keys 命令,重新覆盖之前的文件(因为每次执行 ssh-keygen -t rsa 产生的私钥文件都会不同,为了保险,我们覆盖旧的文件)。然后使用 ssh localhost 测试下,结果如下:

3.3 Java 环境准备
现在就是Java 安装了,这个部分就不多说了,可以查看我以前的文章我们就只来查看下 JAVA_HOME 环境变量,看 Java 环境是否配置好?
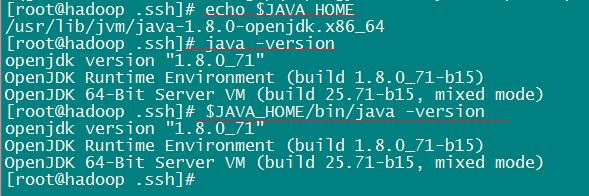
结果显而易见,正常
3.4 安装 Hadoop
现在就是正戏的最后一部分了,这部分 ok了,就舒爽了。
解压 hadoop 压缩文件
利用 FileZilla 将我们在本地下好的 hadoop-2.7.1.tar.gz 上传到云服务器,然后执行命令 tar -zxvf hadoop-2.7.1.tar.gz 将其解压
移动并重命名
① 我们将解压包移动到 /opt/soft_install 目录下。执行命令: mv hadoop-2.7.1 /opt/soft_install
② 然后将其重命名为 hadoop。 。执行命令:mv hadoop-2.7.1 hadoop
配置 HADOOP_HOME
修改 /etc/profile 文件,加入 HADOOP_HOME 环境变量。执行命令:vi /etc/profile

然后,执行命令 source /etc/profile 使得配置文件生效
配置 hadoop-env.sh
接下来,我们修改 hadoop-env.sh 脚本文件,在其中加入 JAVA_HOME 配置

注:
1. 在 2.x 版本中,hadoop 的配置文件在安装目录下的 etc/hadoop 下
2. 我们必须要显示的指明 Java 安装路径,而不是去掉 export 前面的 # 号,使用 shell 变量
配置 core-site.xml
修改 core-site.xml 核心配置文件,我们在此配置 NameNode 的主机和端口号

注:若没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为 /tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。因此我们自己指定一个目录。
配置 hdfs-site.xml
在该配置文件中,我们修改 HDFS 的配置:配置 HDFS 副本数和权限配置

注:若是进行 Hadoop 集群配置,那就副本数至少要为 3,因为 slave(从机器) 少于 3 台就会报错
Hadoop 启动测试
① 格式化 NameNode:前面 3 个配置文件配好后,我们就可以切入到 bin目录下,执行 NameNode 的格式化。执行命令:./hdfs namenode -format


② 启动 NameNode、DataNode、SecondaryNameNode 三个守护进程:在sbin目录下,执行命令:./start-dfs.sh
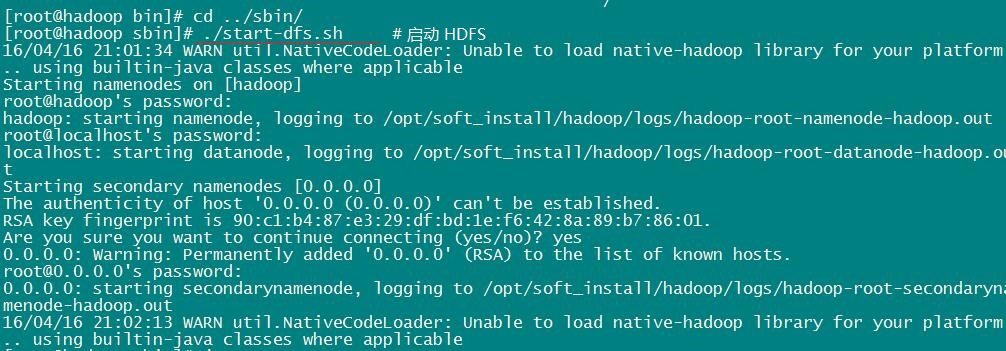
注意:这里要输入密码,是因为 SSH 无密码登录认证配置失败。在这时我还并未去修改这个 bug。若是登录认证成功配置,则不会有这个问题。
③ 查看是否成功启动:怎么验证是否成功了呢?很简单,使用 Java 自带的小工具 jps 就行。直接执行 jps 命令,查看下进程。执行命令:jps

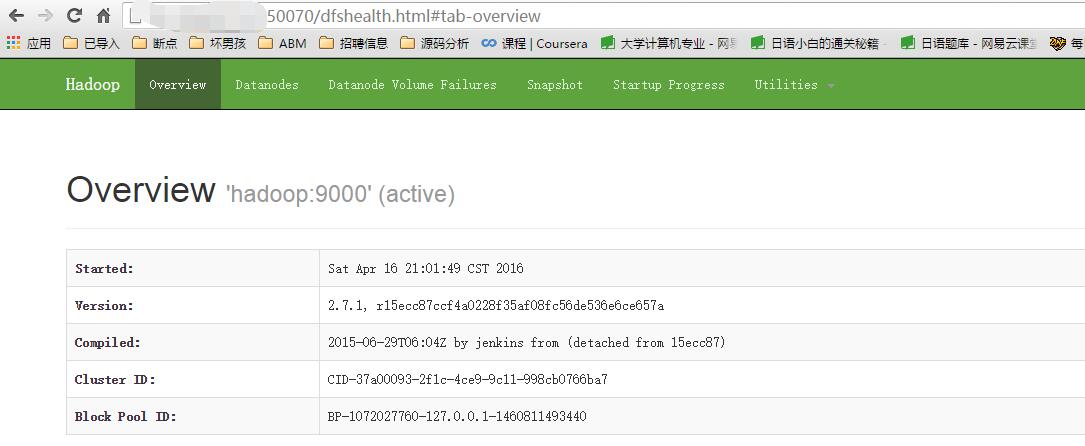
④ 通过 Web 界面查看:成功启动后,我们也可以通过服务器公网来访问下 Web 界面。本机地址栏输入 http://服务器公网IP:50070 查看 NameNode 和 DataNode 信息
配置 mapred-site.xml
对于 2.x 来说,MapReduce 是有很大的不同的,我们在配置时,可以不需要配置 JobTracker 和 TaskTracker 了,因为 2.x 使用了 YARN 框架,我们使用它来进行资源管理与任务调度。前面 ./start-dfs.sh 启动 hadoop 只是启动了 MapReduce 环境,我们可以启动 YARN,让其负责资源管理与任务调度。

注:在 2.x 中,默认是没有 mapred-site.xml 文件的,但是有 mapred-site.xml.tempalte 文件,因此我们使用 cp 命令,复制出一份 mapred-site.xml 文件,然后加入配置。
配置 yarn-site.xml
修改该文件,加入如下配置。

启动 YARN
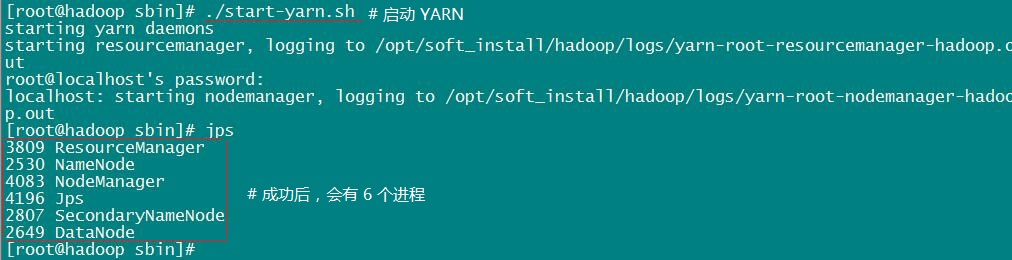
① 启动 YARN:配置好了,我们就可以启动 YARN 了,执行命令:./start-yarn.sh。
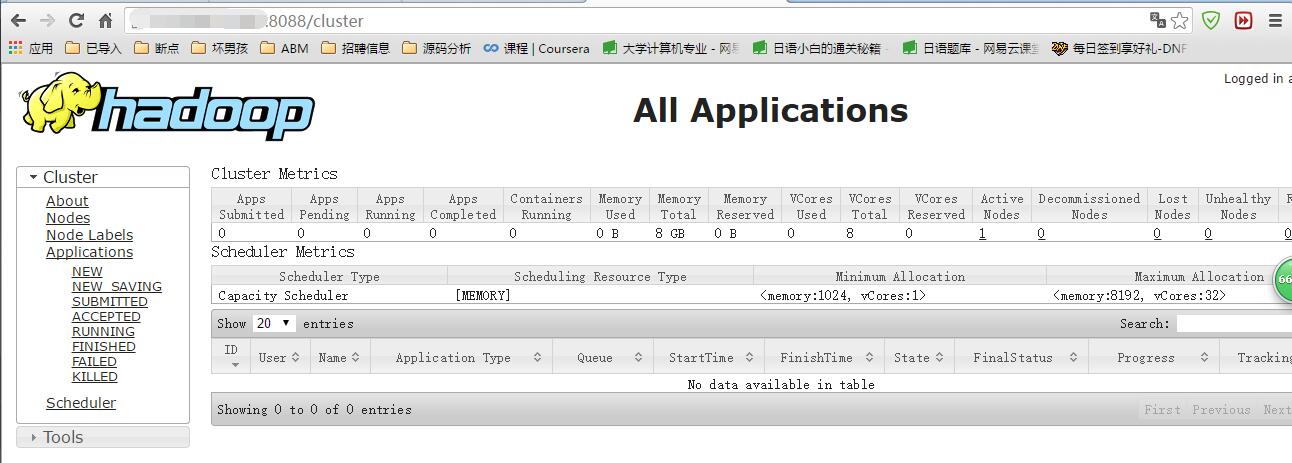
② 查看:启动成功了,我们同样可以通过web界面查看任务运行情况。在本地机器上,访问 http://服务器公网IP:8088/cluster,可以看到如下界面
小结
至此,Hadoop 伪分布式算是成功搭建完成了。接下来,我们就是来试试 hadoop 自带的实例 WordCount。PS:这个实例,其实在启动 NameNode、DataNode、SecondaryNameNode 三个守护进程后,就可以运行的。














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









