







前言:
最近一直在看《算法导论》。算法这块难啃的硬骨头,向来令我头疼不已,尤其是图算法这一部分愈发觉得难啃。在冥思苦想几日之后虽不能说豁然开朗,但也算是小有斩获,稍加整理思绪之后便有此文。所以以下的内容呢,源于我在阅读《算法导论》期间对自己思考过程的总结。
言归正传,今天我要说的主题是单源最短路径问题。比如说,你想知道怎样应该怎样从武汉去北京,那么你可以拿起你的手机登陆Google Maps,输入起点武汉,终点北京,Google会告诉你最佳的选择。撇开交通工具的差异(如果是飞机,估计您老就按照两点之间,线段最短的路径直接飞过去了),我们把地图上每一个城市想象成一个点,从一个城市去另一个城市的公路想象成一条线,那么怎样从武汉去北京的问题就变成怎样从起点经过这么多条不同的线路抵达终点的问题了。那么在如此错综复杂的地图上,我们应该如何寻求两点之间的最短路线呢?
很遗憾的是,当前还没有单纯的解决地图上从A点去B点最短路线的问题,我们往往需要求出从A点出发到所有地方的最短线路之后,才能确定从A到B的最短路线。这是一个很令人头疼的问题,你想如果我们从武汉去北京,犯得着思考怎样从武汉去广州吗?所以说目前的单源最短路径算法在这个境遇上显得十分笨拙。(其实这个问题被我严重化了,可以通过很简单的剪枝避免大量重复的计算)。
思考:
解决单源最短路径最通用的算法是Dijkstra算法,但是在此之前,我们还是先从Bellman-Ford算法说起。毕竟历史的轨迹是如此发展的,先有Bellman-Ford算法,后才有Dijkstra的改进算法。这样的顺序也方便于我们思考:解决同一个问题,我们是否能做得更好。
在正式进入出题之前,我们先给定单源最短路径问题的形式化定义:给定一个带权有向图G=(V, E),对于任意边(u, v)∈E,加权函数ω:E→R赋予边(u, v)一个实数权值ω(u,v)。计算出从给定源点s到图中其余顶点的最短路径。
另外对数据结构还有一些补充。对于任意顶点v∈V,除了存储顶点v至其邻接顶点的边之外,还存储了从源点s到顶点v的最短路径p=<s, v0, v1, …, vk, v>中v的前驱顶点vk和p的路径长度,分别用π[v]和d[v]表示,即π[v]=vk,d[v]=ω(p)。对于从源点到s到顶点v的最短路径,我们只用从顶点v递归寻找其前驱顶点,到s终止时即为其最短路径。我们用δ(s, v)表示从源点s到顶点v的最短路径长度。
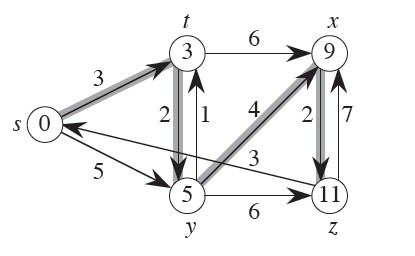
对于这张图,我们设定源点为s,图中被阴影加粗的边都是最短路径所经过的边,
顶点内部的数值代表了其最短路径长度。
例如从s到z的最短路径p=<s, t, y, x, z>,其最短路径长度δ(s, z)=11
Bellman-Ford算法的基底来自于动态规划。根据《算法导论》中总结出是否能运用动态规划的两点特征:最优子结构和重叠子问题。我们可以证明最短路径问题是可以使用动态规划的,以下将用Cut & Paste这一技术来证明最短路径问题满足最优子结构。
最短路径的子路径也是最短路径: 假设p=<v1, v2, ...,vn>是从v1到vn的最短路径,对于任意i, j,其中1 ≤ i ≤ j ≤ n,那么在路径p中从顶点vi到顶点vj的子路径也是从vi到vj的最短路径。
我们把最短路径p分解为v1→vi→vj→vn,考虑从vi到vj的路径q,如果存在另外一条路径q'的路径长度比最短路径p中vi→vj的路径长度还要小,那么我们只用将这条路径q'替换掉原有最短路径p中vi→vj的部分,即可构造一个更短的路径。但这与我们假设p是从v1到vk的最短路径的前提矛盾,所以上述结论成立。至于重叠子问题就更好理解了,如果我们要求从v1到vk的最短路径,那么我们也需依次求出从v1到v2, v3, ..., vk-1的最短路径,每一次求解的过程中都会出现重叠的子问题。
在具体讲解Bellman-Ford算法之前,我们先引入三角不等式。因为正是通过不断的判定三角不等式是否成立,我们才能确切的求出从源点到图中每个顶点的最短路径。
三角不等式:对任意边(u, v)∈E,有δ(s, v) ≤ δ(s, u)+ ω(u, v)。
我们很容易就能证明三角不等式成立。对于从源点s到顶点v的最短路径p,假如存在另外一条经过顶点u到达v的路径p‘,并且p’比原有的最短路径p的路径长度更短,这就与最短路径的前提矛盾,所以不等式必然成立。我们在算法执行过程中始终维持三角不等式成立,并且不断修正顶点v∈V中d[v]和π[v]的值,继而求出最短路径,我们称这样的步骤为松弛(Relax),以下为松弛步骤的伪代码:
Relax(u, v, ω)
{
if d[v]> d[u] + ω(u, v)
then d[v] ← d[u] + ω(u, v)
π[v] ← u
}
Bellman-Ford算法:
接下来正式是Bellman-Ford算法了。我们判定从源点s到图中任意顶点的最短路径所经历的边数都不会超过|V|-1(其中|V|为图中顶点的个数),否则就会出现回路。我们从最短路径所经历的边数入手,从源点s出发,自底向上构造经历边数依次为1,2,...,|V|-1的最短路径,结束时就能保证从源点s到图中任意顶点的路径都为其最短路径。似乎说起来并不难理解,接下来我们用数学归纳法来证明这一算法的正确性。
对于从源点s出发的最短路径所经历的边数n,
基础步骤:当n=1时,从源点s到其邻接顶点的路径都是边数为1的最短路径。这一点很显然,对于图中除源点外的任意顶点v,要么与源点邻接,其路径长度为这条边的权值ω(s, v);要么不与源点邻接,其路径长度为∞(表示两顶点不可相互抵达)。
归纳步骤:假设当n=k时,我们已经构造了从源点s出发,经历边数为1,2,...,k的最短路径。那么任取这样的一条路径p=<s, v1, v2, ...,vk>,有d[vi]=δ(s, vi),i≤k。如果从源点s到顶点vk+1的最短路径由p'=<s,v1, v2, ..., vk, vk+1>组成,在松弛边(vk, vk+1)后,d[vk+1]的路径长度即为δ(s, vk+1)。如果不是,这就与路径p是从s到vk的最短路径的前提矛盾。故当n=k+1时,也满足从源点s出发,经历边数为k+1的路径也为最短路径。
综上所述,当已经构造完毕经历边数为|V|-1的最短路径之后,我们就确立了从源点s到图中任意顶点v∈V的最短路径。
或者更为通俗的讲,我们判定从s到图中每个顶点v∈V存在一条这样的最短路径,其路径长度为δ(s, v) = min { p: p为从s到v的可达路径 },否则就是不可抵达,其路径长度为∞。如果我们依照路径p的顺序,保证每次从s出发到v的子路径都是一条最短路径,那么最终我们就能够得到一条这样的最短路径。
但是我在观看MIT的教学视屏时发现,往往我们并不需要这样运行|V|-1次才能确定单源最短路径,一方面是图中所有顶点确立的最短路径所经历的边数达不到|V|-1;另一方面是在算法执行过程中,假如运行到第i次,我们并不只是松弛从s出发到vi的路径所经历的i条边,相反我们松弛了所有边。这样导致的结果是:也许在第i次运行时巧合的发现,我们不仅确立了从s到vi的最短路径,同时也确立了从vi到vj的最短路径。那么我们就直接确立了从s到vj的最短路径,第i次以后的过程也许就不会产生实质的影响了(事实上是额外且多余的时间开销)。
如果换一种思路,假设我们事先就能确立从s到任意顶点v的最短路径所经历的每个顶点的顺序,即对于最短路径p=<s, v1, v2, ... vk>而言,我们知道v1,v2,..., vk确切对应的是哪一个顶点,并且按照这条路径途经顶点的顺序进行松弛,同样也可以得出从源点s到图中任意顶点的最短路径。这就好比做一项工作,如果你事先知道按照怎么样的顺序去做这项工作的每一部分最能省时间,并且你按照这样的顺序完成这项工作,那么当工作做完时花费的时间也是最少的。而我们确立这样的顺序所需要做的仅仅只是一次拓扑排序罢了。这样就能将Bellman-Ford算法的时间复杂度O(VE)降为O(V+E)。
Dijkstra算法:
现在应该是我们重头戏登场的时候了:Dijkstra算法。作为目前最为广泛使用的单源最短路径算法,Dijkstra算法不仅执行速度高效,而且程序结构堪称精妙。美中不足的是,Dijkstra算法在求解时采取了贪心策略,为了能够维持贪心选择性质,算法要求给定的带权有向图中所有边的权值不小于0。如果图中存在一条权值为负值的边,Dijkstra算法就不能保证其正确性了。但是如果我们把目光置于现实生活,我们会发现在解决类似问题的情形下几乎不存在负数,譬如公路,街道的距离就不可能是负数。更为苛刻的讲,我们很难描述一条被赋值为负权的边的实际模型,虽然在理论上这是确切存在的。所以除去这点原因,Dijkstra算法在实际应用中解决单源最短路径问题时可谓游刃有余。
Dijkstra算法通过维持一个动态集合S,不断将已经确定最短路径的顶点添加至S,当S已经包含图中所有顶点时算法结束。我们在前文说过,Dijkstra算法使用了贪心策略,因为在每次选取集合S外的顶点时,我们总是选取一个当前路径长度最小的顶点加入S。通过不断选取当前路径长度最小的顶点,我们期望在算法结束时能满足从源点到每个顶点的路径都为最短路径。我们仍然使用数学归纳法证明这一事实的成立。
对于集合S中顶点的个数n,
基础步骤:当n=1时,我们在初始化时将源点的路径长度d[s]置为0,其余顶点的路径长度置为∞,所以S中的唯一顶点必定是源点s。因为不存在负权边,所以δ(s, s)=0,源点s的确已经确立了最短路径。
归纳步骤:假设当n=k时,我们已经确立了S中k个顶点的最短路径。那么我们依次遍历还不在S中的其余顶点(即集合V-S),选取其中路径长度最小的顶点v。
⒈ 如果顶点v的路径长度d[v]=∞,说明集合S的所有顶点都无法抵达顶点v。又因为顶点v是集合V-S中路径长度最小的顶点,所以集合V-S中的所有顶点的路径长度都为∞,我们可以断言从源点s到集合V-S中的所有顶点都不可达。对于v'∈V-S,δ(s, v')=∞,因此我们确立了顶点v的最短路径。那么当n=k+1时结论仍然成立。
⒉ 如果顶点v的路径长度d[v]≠∞,说明集合S中存在一条路径抵达顶点v,对于这条路径p=<s, v0, ..., vk, v>,我们一分为二:假设p'=<s, v0, ..., vi>,i≤k,是在集合S中形成的一条路径,即路径p'经过的每个顶点都属于集合S;那么另外一条路径q'=<vi, vi+1, ..., vk, v>则是在集合S-V中形成的一条路径。因为顶点v是集合V-S中路径长度最小的顶点,所以满足d[v]≤d[vi+1]。又因为图中不存在负权边,根据路径p',我们推导出d[v]≥d[vi+1]。综合两者,我们得到:d[v]=d[vi+1],ω(q')=0,q'毫无疑问是从vi+1到v的最短路径。所以在这个时候,无论是选择v或是vi+1(事实上,他们很有可能是同一顶点),我们都能确立他们的最短路径。特别的,对于顶点v,我们确立了其最短路径,那么当n=k+1时结论仍然成立。
综上所述,当集合S包含图中所有顶点时,已经确立了从源点s到任意顶点v∈V的最短路径。
或者更为通俗的讲,为什么每次选取当前路径长度最小的顶点就能保证全局最优呢?归根结底是前提的设定:图中不存在负权边。对于在集合V-S中的顶点而言,选取路径长度最小的顶点v意味着不可能还有比当前路径长度更小的路径到达顶点v,否则那条路径的权值为负值。对于Dijkstra算法的改进多半是从选取最小路径长度的顶点入手,用二叉最小堆实现的优先级队列的时间复杂度为O((V+E) * lgV),倘若用斐波那契堆来实现优先队列的时间复杂度能优化为O(VlgV+ E)。除此之外,原本的Dijkstra算法在程序结构上是无法进一步优化的。
我们在以上的分析过程中一直对负权回路避而不谈,是因为如果给定图中存在一条负权回路,我们就可以不断在这条回路中循环,得到我们期望的任意小的路径长度。如此这般也就不存在最短路径,其路径长度只能用-∞表示,因此单源最短路径问题也就没有了意义。
后记:
事实上,以上的内容多半与《算法导论》原书无异,甚至还存在偏差和疏漏的地方。我的想法呢,是想把自己这么一路来的思考过程给记录下来,理清一下思路。毕竟当你能把一件复杂的事情给讲明白时,多半你自己就真弄明白了。原本我也想贴一下代码,具体给个实现。但是在写的过程中发现如果这样做,重心就偏向于讲解,而非是我自己的思考了(讲不讲得好就另当别论,再说估计也好不到哪去)。我的目的很单纯,希望能彻底掌握单源最短路径的解法,也算是为以后的程序员之路奠定基础吧。














 4531
4531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









