







记得小时候玩的游戏机在没有投币的时候会自动播放预先录制的游戏视频,然后屏幕上会闪烁着”DEMONSTRATION”的字样,当时不理解是预先录制的游戏视频,认为是机器可以自己操控自己玩游戏,因为那时没有什么探索的方式(比如图书馆或者搜索引擎),但还是会占用上课的时间去思考机器自己和自己玩游戏是怎么实现的。好奇心重的人真的每天都生活在坑里,一个接着一个的坑。
这一期我来演示一个机器通过深度学习的方式和自己玩游戏的小例子,也许通过深度学习的方式,整个游戏外挂行业正在快速迭代中。在检索素材的过程中发现 Udacity 提供的 “Udacity’s Self-Driving Car Simulator” 模型最适合演示,它提供了一个模拟器,可以支持模拟器中汽车的训练和自动驾驶功能,项目使用 MIT 协议开源 https://github.com/udacity/self-driving-car-sim . 可以将源代码下载并用 Unity 工具构建一下,因为不太感兴趣构建的过程,所以我使用官方编译好的bin文件,如果不能下载可以从我的网盘下载 https://pan.baidu.com/s/1dE5PrHJ 将 beta-simulator-linux.zip 解压并赋予执行权限就可以运行模拟器。可以先运行一下,画质和 NFS3 很像,毕竟只是演示画面没有那么细腻。
在进行演示之前需要安装一个和 pip + virtualenv 很像的另外一种科学实验环境管理器:conda ;虽然 Anaconda 像 MATLAB 一样带有浓厚的商业气息,但 conda 还是完全开源和免费的社区型项目(https://github.com/conda/conda/wiki/Conda-Community),不要被 Anaconda 的臃肿和商业性所遮眼, 将 conda 最小化包装的开源项目 Miniconda 真的可以更大的提升实验环境的部署效率。通过下面的链接可以下载 miniconda:
https://conda.io/miniconda.html
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
conda 的实验环境搭建是在用户级别的,它的创意之处就在于它把 Python 也当成自己的一个小组件,可以任意指定版本,所以用不到 sudo 之类的操作。使用下面的命令安装 miniconda ,各种 Enter 即可完成
bash Miniconda3-latest-Linux-x86_64.sh 如果网络质量不给力可以修改 conda 的源为国内镜像,具体步骤请参考 https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
模拟器的训练和自动驾驶,我们使用 https://github.com/naokishibuya/car-behavioral-cloning 提供的方法,网络模型构建依据 Nvidia 的 End-to-End Deep Learning 模型 https://devblogs.nvidia.com/parallelforall/deep-learning-self-driving-cars/
下载运行脚本文件 https://github.com/aggresss/GPUDemo/tree/master/car-behavioral-cloning
conda 通过一个 yml(Yet anther Markup Language) 文件就可以实现环境的部署
conda env create -f environment-gpu.yml激活实验环境,然后运行驾驶脚本
source activate car-behavioral-cloning
python drive.py model.h5当出现提示”wsgi starting up on http://0.0.0.0:4567“时说明自动驾驶服务已经开启成功,然后在shell 中执行 beta_simulator.x86_64 选择 Autonomous Mode
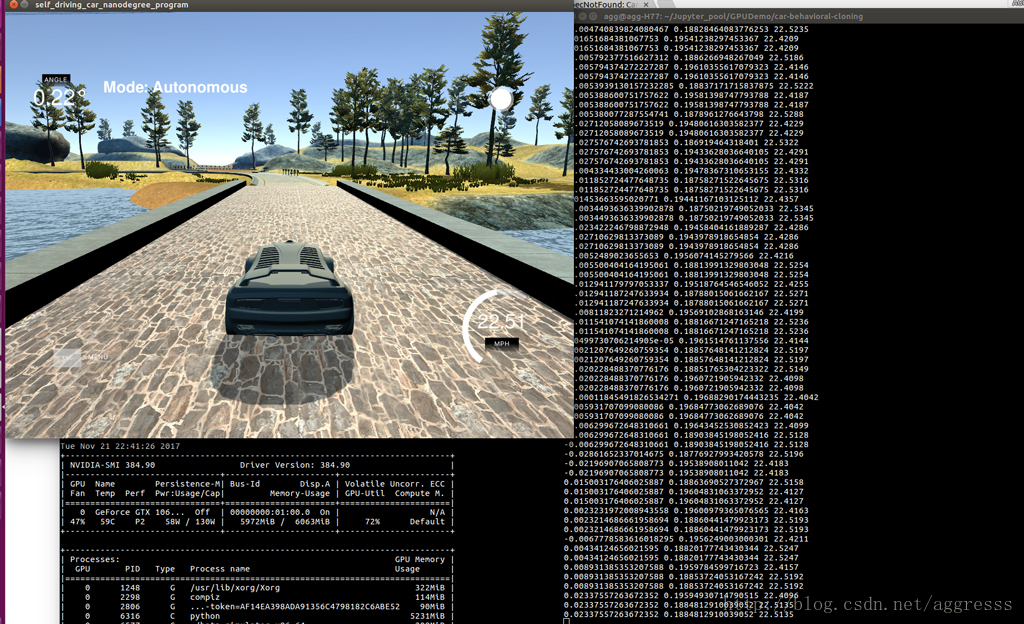
原理并不复杂,在选择自动驾驶模式时,模拟器会把每一帧图片提交给 一个 wsgi 服务,这个服务通过将图片传入我们构建的神经网络计算出这张图片应该对应的车辆操作,比如油门刹车和方向盘角度,然后返回给模拟器,模拟器通过返回指令操作车辆。
深度学习的神经网络通过 Keras 实现非常通俗易懂,5层卷积层和4层全连接层。
def build_model(args):
"""
Modified NVIDIA model
"""
model = Sequential()
model.add(Lambda(lambda x: x/127.5-1.0, input_shape=INPUT_SHAPE))
model.add(Conv2D(24, 5, 5, activation='elu', subsample=(2, 2)))
model.add(Conv2D(36, 5, 5, activation='elu', subsample=(2, 2)))
model.add(Conv2D(48, 5, 5, activation='elu', subsample=(2, 2)))
model.add(Conv2D(64, 3, 3, activation='elu'))
model.add(Conv2D(64, 3, 3, activation='elu'))
model.add(Dropout(args.keep_prob))
model.add(Flatten())
model.add(Dense(100, activation='elu'))
model.add(Dense(50, activation='elu'))
model.add(Dense(10, activation='elu'))
model.add(Dense(1))
model.summary()
return model 刚才我们使用的weight文件 model.h5 是预先训练好的,经常会自己开到坑里,我们也可以自己重新训练一下这个网络:在目录下创建 data 文件夹 然后运行模拟器选择Train mode ,进入驾驶模式后点击 RECORD 然后选择 data 文件夹,开始驾驶,结束后在点击暂停按钮,模拟器会自动将刚才驾驶过程中的图片与车轮角度的对应关系生成数据文件,用于下一步的网络训练。
退出后执行 python model.py 就会训练网络,然后通过训练后的 weight 值提交给 drive.py 体验自己训练的网络的准确度。
实验结束后可以通过如下方式退出并删除实验环境:
source deactivate
conda env remove --name car-behavioral-cloning













 1133
1133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









