










以下内容主要基于《Latent Dirichlet Allocation》,JMLR-2003一文,另加入了一些自己的理解,刚开始了解,有不对的还请各位指正。
LDA-Latent Dirichlet Allocation
JMLR-2003
摘要:本文讨论的LDA是对于离散数据集,如文本集,的一种生成式概率模型。LDA是一个三层的贝叶斯分层模型,将数据集中每一项,如每个文本,建模为某些未知的topic组成的集合的混合。每个topic又建模为某种混合概率分布。在文本建模中,话题的概率就提供了每个doc的具体表示。
个人理解:1.生成式模型,就好像我们要写出一篇文章(生成一篇文档),我们在下笔的时候脑袋里要先有这个文章的主题,然后在这个主题下再构建合适的词来组成文档。这样的过程就是这篇文章里‘生成’的过程。
2.doc->mixture of topics; 每个topic->mixture of words,文中的Dirichlet分布也体现在这个分布的分布上,原因后续讲解。
基础知识,如果都懂,可以跳过:
一、tf-idf scheme
tf-idf scheme: 首先选中一个基字典basic vocabulary, 然后对每一个文档doc,查找每个词word的出现次数,然后进行归一化,最后得到的表示形式为一个term-by-document的矩阵X,而将任意长度的doc表示成固定长度的一个向量,而所有的doc则可以用一个list,也就是矩阵X,来表示:
word_1
word _2
……
word _|V|
其中xij=#num of word_i / # num of total words in doc_j .
优点:可以简明易懂的将每个文档表示出来,而且无论每个文档本身长度如何,都缩减为固定长度(|V|)的向量;
缺点:1.如果选择的词典vocabulary比较大,那这个表示矩阵的维度也会比较大,而且其list的长度会随着库中文本数目的增加而增加;2.另外,这样的表示没有考虑文档与文档之间以及各文档内部的结构信息。
个人理解:除以上缺点外,这种方法的相似性判断建立的基础是认为文档之间重复的词语越多越相似,然而有一些属于语义层的相关,而并非表面的词语的相关,例如‘电脑’与‘微型计算机’这两个词并不相同,但意思相同,这时候如果用tf-idf方法通过统计单词个数比较相似性的方法,效果就不会太好。而主题模型就解决了这个问题,它的相关性体现在隐藏的主题的相关性上,而不是仅仅由表面的词语的重复度来决定。,如下图所示(摘自Thomas Huffman_ppt)。
二、LSI-Latent Semantic Indexing
针对缺点1,LSI(1990)将矩阵X进行奇异值分解,然后只取一部分作为其特征,此过程其实就相当于对X进行pca降维。将原始的向量转化到一个低维的隐含语义空间中,而保留下来的维度(根据奇异值大小决定)所对应的奇异值就对应了每个‘隐含语义’的权重,去掉的那些维度就相当于把那些不重要的‘隐含语义’的权重赋值为0.
LSI的作者Deerwester称由LSI得到的特征能够捕获一些基本的语义概念,例如同义词等。个人理解,这是由pca的性质决定的,。
LSI如其名字Latent Semantic Indexing, 旨在在词频矩阵X的基础上找出latent semantic,潜藏的语义信息。
其缺点是:不能解决多义词问题;
个人理解:这种方法就像词包模型一样,有一定的道理,但没有明确化,不像概率模型一样具体化。原文中说‘Given a generative model of text, however, it is not clear why one should adopt the LSI methodology’,个人觉得就是说他的理论基础不够明白,所以后续推出PLSI,就是能够从数学上,从理论上具有严格意义的说明是怎么回事,到底是为什么有效,又怎么得出理论解。
三、pLSI-probabilistic LSI
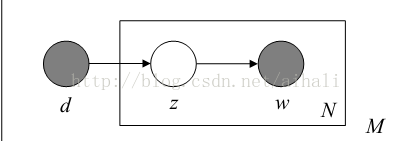
(pLSI图模型表示)
pLSI如上图,其中D,Z,W分别表示文档doc,主题topic,和单词word,在pLSI中对每一个都进行了建模,从文档到主题,建模为混合模型,从主题到单词也是一个混合模型,每个单词都是从这个混合模型中抽取出来的,不过在pLSI中每个混合模型的成分都是multinomial分布,根据上图,其中后验概率可以表示为:
p(z_k|d,w)=p(w|z_k)p(z_k|d)/sum_l(p(w|z_l)p(z_l|d))
用EM算法可以求解出各成分的参数。
个人理解:1.在pLSI中,每个doc已经可以有多个topic,每个topic出现的概率不等,这一点在LDA中也有。只不过LDA比pLSI多了一层。
2.上述混合模型的理解:类比于混合高斯模型一样,在混合高斯模型GMM中,是由多个高斯分布混合mixture而成的,在这里,每个混合模型的分量不是高斯分布,而是multinomial分布-多项式分布而已,而且区别于普通GMM,这里是有两层结构的,每一层都是一个混合模型,doc->topic层是一个混合模型,topic->word层也是一个混合模型,每个混合成分都是一个多项式分布,然后每个混合模型中包含了各个成分本身的参数和各个成分的权重的参数。
2.从上面这个图可以看出在pLSI中已经有了topic的概念,而且对于文档-主题和主题-单词两个层面都进行了建模(混合模型),但是也可以看出这个模型是对每一个文档集的,每一个文档集都对应着模型的一堆参数,如果新来一个文档(不在原来的训练集里),就没法处理。而LDA就可以不仅对已有的文本进行估计,也会对其他新的相似的文本给一个较高的probability。(注:在pLSI模型中,假设有k个topic,vocabulary长度为V,对于这k个topic有M个mixture,那总共有kV+kM个参数,这个数目是随着M的增加而增加的,当文本集中文档数目太大时就会overfitting)。
3.每个文档的表示就是一个list,其中的每个number表示了每个topic在其中的比例(mixing proportions)。这种表示,当文本集很大时,仍然会有很长的一个list。
四、LDA-latent dirichlet allocation
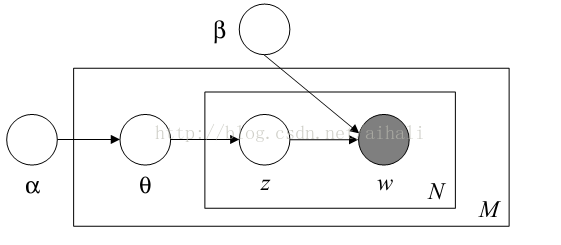
(LDA的图模型表示)

然后,由其概率模型图可以比较容易的得到模型如下:
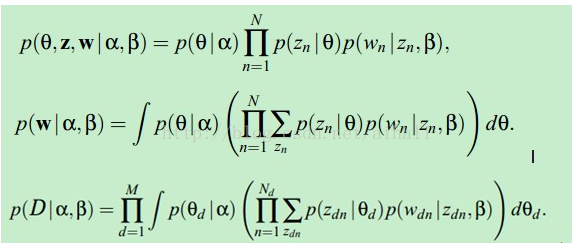
推断:
计算后验概率:
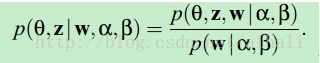
似然函数
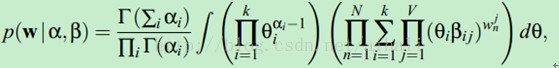
这个式子中对于beta和aplha都有指数幂而相互耦合,两个参数求导后都不能消掉,因此没办法直接用最大似然或者em求解,这时候引入变分推断(variational inference)。变分推断就是为了顾及后验分布,在无法直接对似然函数求解的情况下寻找一个似然函数的下界。然后利用EM的思想进行迭代,让这个下界逐次增大,达到最后收敛。
基础:无论是LSI,PLSI还是LDA都有一个假设,就是无序性假设(exchangeability),即认为文档中的word的出现位置先后没有关系,文档集中的各个doc的位置也不计较先后关系。
的Dirichlet先验分布中sample出来的Multinomial分布(注意词典由term构成,每篇文章由word构成,前者不能重复,后者可以重复)。对于每篇文章,他首先会从一个泊松分布中sample一个值作为文章长度,再从一个参数为
的Dirichlet先验分布中sample出一个Multinomial分布作为该文章里面出现每个Topic下词的概率;当他想写某篇文章中的第n个词的时候,首先从该文章中出现每个Topic下词的Multinomial分布中sample一个Topic,然后再在这个Topic对应的词的Multinomial分布中sample一个词作为他要写的词。不断重复这个随机生成过程,直到他把m篇文章全部写完。这就是LDA的一个形象通俗的解释。”
推断:后验概率p(theta,z|alpha,beta,w)中theta与beta有指数幂不能直接求解,为此得用近似推断的方法,文章中用的是变分推断。变分推断就是要找一个与原来的不能直接求解的后验概率等价或近似的函数q,这个函数要好解,一般最简单直接的方法就是假设q中各个参数独立,形成q=product_n(q_n),这篇文章中选取的q为:
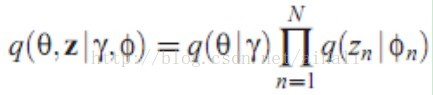
对应的图模型为
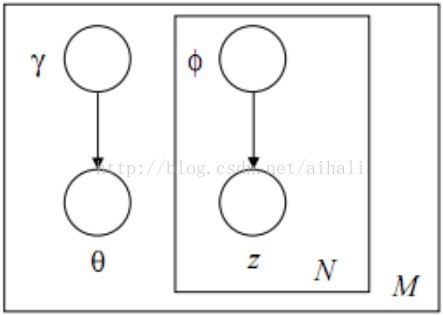
在得到近似函数后,就通过求解最优近似函数q的参数来得到原后验的参数。
本文来自于新浪博客上的一篇文章,该地址为:http://blog.sina.com.cn/s/blog_5033f3b40101flbj.html
杂七杂八说了这么多,下面介绍几个参考资料:
其他值得参考的资料:
1.http://blog.csdn.net/yangliuy/article/details/8330640,这里是一个系列,总共有5篇文章,从PLSA、em到LDA都有介绍,其中有pLSA的详细实现过程;
2. http://hi.baidu.com/hehehehello/item/677f9446b729a72210ee1e8b ,pLSI与LDA详细的区别;
3. http://hi.baidu.com/linecong/item/8c115b196232147a7b5f2598
4.百度搜索官方博客:http://stblog.baidu-tech.com/?p=1190
5.丕子博文
6.关于LSA中用到的SVD奇异值分解可以参考之前转的一篇文章:
7.plsa
其他资源:以下摘自网络:
(2)T. L. Griffiths and M. Steyvers, "Finding scientific topics," Proceedings of the National Academy of Sciences, vol. 101, pp. 5228-5235, 2004.
(3)D. M. Blei, et al., "Hierarchical Topic Models and the Nested Chinese Restaurant Process," NIPS, 2003.(4)Blei的LDA视频教程:http://videolectures.net/mlss09uk_blei_tm/
(5)Teh的关于Dirichlet Processes的视频教程:http://videolectures.net/mlss07_teh_dp/
(6)Blei的毕业论文:http://www.cs.princeton.edu/~blei/papers/Blei2004.pdf
(7)Jordan的报告:http://www.icms.org.uk/downloads/mixtures/jordan_talk.pdf
(8)G. Heinrich, "Parameter Estimation for Text Analysis," http://www.arbylon.net/publications/text-est.pdf
基础知识:
(1)P. Johnson and M. Beverlin, “Beta Distribution,” http://pj.freefaculty.org/ps707/Distributions/Beta.pdf
(2)M. Beverlin and P. Johnson, “The Dirichlet Family,” http://pj.freefaculty.org/stat/Distributions/Dirichlet.pdf
(3)P. Johnson, “Conjugate Prior and Mixture Distributions”, http://pj.freefaculty.org/stat/TimeSeries/ConjugateDistributions.pdf
(4)P.J. Green, “Colouring and Breaking Sticks:Random Distributions and Heterogeneous Clustering”, http://www.maths.bris.ac.uk/~mapjg/papers/GreenCDP.pdf
(5)Y. W. Teh, "Dirichlet Process", http://www.gatsby.ucl.ac.uk/~ywteh/research/npbayes/dp.pdf
http://www.stat.berkeley.edu/tech-reports/770.pdf
(7)T. P. Minka, "Estimating a Dirichlet Distribution", http://research.microsoft.com/en-us/um/people/minka/papers/dirichlet/minka-dirichlet.pdf
(8)北邮论坛的LDA导读:[导读]文本处理、图像标注中的一篇重要论文Latent Dirichlet Allocation,http://bbs.byr.edu.cn/article/PR_AI/2530?p=1
(9)Zhou Li的LDA Note:http://lsa-lda.googlecode.com/files/Latent Dirichlet Allocation note.pdf
(10)C. M. Bishop, “Pattern Recognition And Machine Learning,” Springer, 2006.
代码:
(1)Blei的LDA代码(C):http://www.cs.princeton.edu/~blei/lda-c/index.html
(2)BLei的HLDA代码(C):http://www.cs.princeton.edu/~blei/downloads/hlda-c.tgz
(3)Gibbs LDA(C++):http://gibbslda.sourceforge.net/
(4)Delta LDA(Python):http://pages.cs.wisc.edu/~andrzeje/research/deltaLDA.tgz
(5)Griffiths和Steyvers的Topic Modeling工具箱:http://psiexp.ss.uci.edu/research/programs_data/toolbox.htm
(6)LDA(Java):http://www.arbylon.net/projects/
(7)Mochihashi的LDA(C,Matlab):http://chasen.org/~daiti-m/dist/lda/
(8)Chua的LDA(C#):http://www.mysmu.edu/phdis2009/freddy.chua.2009/programs/lda.zip
(9)Chua的HLDA(C#):http://www.mysmu.edu/phdis2009/freddy.chua.2009/programs/hlda.zip














 4139
4139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









