







学习一种算法最直接也是最有效的方法是从实例中学习。当然,实例越通俗越简单最好,至少对于初步掌握一种算法是这样的。这是本文的出发点。为了更加具有操作性,本文还附上了可直接编译执行的java源代码,希望对各位读者有帮助。
现在就开始吧。
假如现在有以下数据,time表示所花的时间,score表示相应的分数。
| time | score |
| 9 | 39 |
| 15 | 56 |
| 25 | 93 |
| 14 | 61 |
| 10 | 50 |
| 18 | 75 |
现在我要你根据上面的数据预测假如某个学生花的时间为12,那么他会得到多少分?
我相信很多人马上就会想到很多的方法,比如比例:12*39/9=52.看上去似乎也可以,但是仅仅利用了其中的一条记录,显然不合适。我相信大多数人会想到:建立一个函数表示time→score之间的关系。嗯,time和score之间存在着关系。那么用个什么样的函数来假定这种关系呢?它们可能存在线性关系,或者其他形式的关系。
现在我们可以来介绍线性回归了。在上面的例子中,简单的说,线性回归就是用一个线性函数来假定time和score之间的关系(也就是假定两者存在线性关系)。
假定这个线性函数表示如下:
score=a*time+b.显然,为了预测当time=12时,score=?。需要有方法求得参数a,b。可能有人立马又会跳出来说,这好办,将上表中的前两条记录代进去,得到两个方程,两个未知数,解方程组就可以得出a,b了。显然,这一得到的函数关系能100%准确预测time=9,time=15时对应的score,但是哪怕对于表中的其他项,预测可能就会存在很大的偏差,自然是不能用来预测的。
那么使用什么方法呢?
我们不妨把上表的数据先画到一个坐标系上去
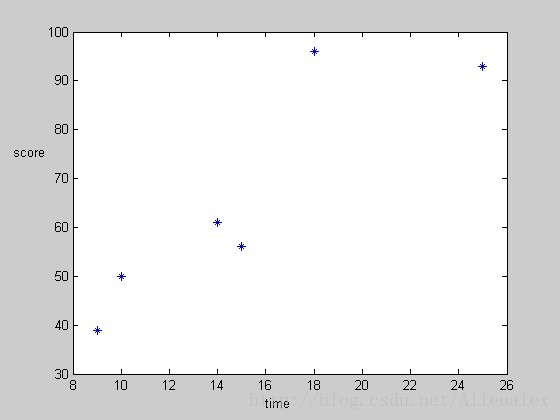
现在我们的目的(线性规划的目的)是要在坐标系上找到一条直线能够很好的拟合坐标中的6个点,这样time=12(x轴)在该直线上对应的轴坐标就是我们要预测的score。
如何实现这个目的呢?线性规划的数学描述告诉我们,要拟合这些点,也就是这些点到假定的直线的(垂直x轴,为什么是垂直x轴呢?想想:预测值最大程度接近真实值)距离和要达到最小。用数学表示,同时考虑计算上的便利,也就是要使下式最小:
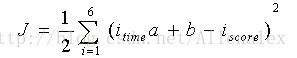
其中i指的是表的第i列,相应的为i列的time和score。用图直观的表示如下,也就是要图中垂直(与x轴)的几条线的“和”达到最小。
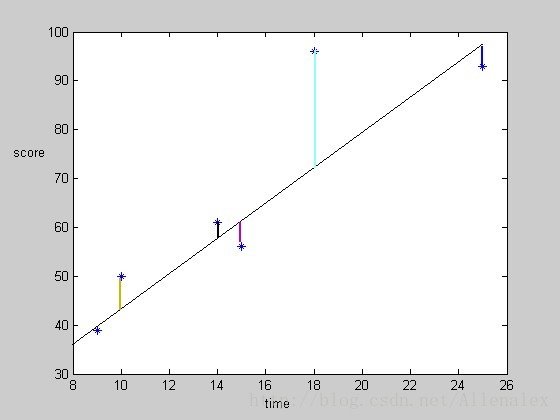
如何找到这条直线呢?下面介绍的梯度下降法可以实现。
梯度下降法
继续承上面的例子来说明梯度下降,我们的目的其实就是要找到合适的a,b的值,使得J最小。为了实现这个目的,梯度下降的思想是先给a,b随机假定一个初始值,然后重复改变a,b的值,使得J变小,直到收敛到某个值使得J已经达到最小。这里面有两个问题需要解决:1,如果改变a,b的值才能实现使J变小。2,怎样判断J已经达到最小值。我们先将梯度下降算法总结如下再回答这两个问题:
1.随机给a,b分配值;
2,改变a,b的值,使得J按梯度下降的方向的减小:
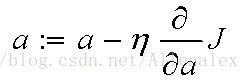
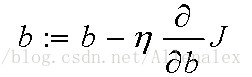
迭代改变a,b的值,直到J达到最小。其中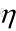
上面第二步回答了第一个问题,至于第二个问题。一种选择的方法就是判断某一步迭代后,J的值是否还会继续下降。
梯度下降通常又可以分为批量梯度下降和随机梯度下降,关于它们的介绍和两者的区别,读者可以参考斯坦福的公开课——《机器学习》
此外,本文是从一个实际的例子来讲解线性规划和梯度下降。在事例中,我们只考虑了一个预测变量(predictor variable)——time的情况。实际中可能会包括多个预测变量。更多更详细的介绍,读者仍然可以参考《机器学习》公开课。
下面附上代码,该部分代码不仅适用于本文讲的例子,对于多个预测变量(如h=a1x1+a2x2+a3x3+...+b)的例子同样适用。
import java.text.DecimalFormat;
public class Gradient_Descent {
/**
* gradient descent algorithm
* this program can only for one criterion variable
* but many predictor variable
* @pred_size predictor variable's size
* @train_size size of the training data
* @pred_var predictor variable
* @crit_var criterion variable
* @para parameter
* @rate learning rate
*/
static DecimalFormat df =new DecimalFormat("#.000000000");
static int pred_size=1,train_size=6;
/*
* predictor variable(can be more than one)
* h=ax+b,one predictor variable,have two parameter:a,b.the pred_var value for the b is
* {1,1,1,1,...}.because h=ax+b'y','y'==1
*/
static double[][] pred_var;
static double[] crit_var;
/*
* for example,h=ax1+bx2+c,para[0]=a,para[1]=b,para[2]=c
*/
static double[] para=new double[pred_size+1];
//learning rate
static double rate=0.0002;
//cost function
static double cost_fun=0;
public static void main(String args[]){
pred_var=new double[][]{{9,15,25,14,10,18},{1,1,1,1,1,1}};
crit_var=new double[]{39,56,93,61,50,75};
/*test:score=4*a+1
pred_var=new double[][]{{9,15,25,14,10,18},{1,1,1,1,1,1}};
crit_var=new double[]{37,61,101,57,41,73};*/
//initialize the parameter
for (double d : para) {
d=0;
}
Gradient_Descent.obtainParaByGD();
for (int i=0;i<pred_size+1;i++) {
System.out.print("para["+i+"]="+df.format(para[i])+" ");
}
System.out.println();
System.out.println("cost:"+df.format(cost_fun));
}
/**
*
* @hy_value h(a)=a0+a1x1+a2x2+...
* @flag iterations
* @temp_para accumulated value in Gradient_D
* @min_fun The minimum loss function
*/
public static void obtainParaByGD(){
double hy_value;
for(int i=0;i<train_size;i++)
{
hy_value=0;
for(int j=0;j<=pred_size;j++)
{
hy_value+=para[j]*pred_var[j][i];
}
cost_fun+=(hy_value-crit_var[i])*(hy_value-crit_var[i]);
}
cost_fun=cost_fun/2;
double min_fun=cost_fun;
int flag=0;
while(true)
{
double[] temp_para=new double[pred_size+1];
for (double d : temp_para) {
d=0;
}
for(int j=0;j<=pred_size;j++)
{
for(int i=0;i<train_size;i++)
{
hy_value=0;
for(int h=0;h<=pred_size;h++){
hy_value+=para[h]*pred_var[h][i];
}
temp_para[j]+=((hy_value-crit_var[i])*pred_var[j][i]);
}
}
for(int i=0;i<=pred_size;i++){
para[i]=para[i]-rate*temp_para[i];
//System.out.println(para[i]+" ");
}
for(int i=0;i<train_size;i++)
{
hy_value=0;
for(int j=0;j<=pred_size;j++)
{
hy_value+=para[j]*pred_var[j][i];
}
cost_fun+=(hy_value-crit_var[i])*(hy_value-crit_var[i]);
}
cost_fun=cost_fun/2;
if(cost_fun<min_fun)
{
min_fun=cost_fun;
flag=0;
}else {
flag++;
}
if(flag==1000)
break;
}
}
}














 3927
3927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









