







初衷
刚接触java不到2礼拜的小白试图通过阅读jdk的源码来学习java。如有理解或表达不对的地方,欢迎各位大佬指正,谢谢。
0. Character类的用途
1.对基本类型char进行包装,个人感觉从某种意义上来讲Character类是char的装饰器。
2.对外开放的丰富的功能能够好的处理char型数据(基于unicode),提高代码的复用。
1. Character类的继承和实现体系
Character类的继承和实现体系如下图所示:
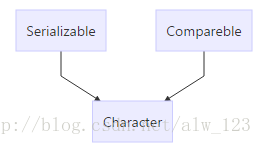
其中Serializable接口是启用其序列化功能的空接口。实现Serializable接口的类是可序列化的。没有实现此接口的类将不能使它们的任一状态被序列化或逆序列化。而Compareble是一个泛型的接口,且接口中只有一个compareTo方法,也就是说Character实现了compareTo方法来实现Character的对象在容器中时能够进行自然排序。(好比在C++中,vector中的元素是类A的对象,想要调用vector的sort函数对其进行排序时,需要类A重载<操作符。只不过在Java中更OO)
2. unicode是什么
计算机发明后,为了在计算机中表示字符,人们制定了一种编码,叫ASCII码。ASCII码由一个字节中的7位(bit)表示,范围是0x00 - 0x7F 共128个字符。
后来他们突然发现,如果需要按照表格方式打印这些字符的时候,缺少了“制表符”。于是又扩展了ASCII的定义,使用一个字节的全部8位(bit)来表示字符了,这就叫扩展ASCII码。范围是0x00 - 0xFF 共256个字符。
中国人利用连续2个扩展ASCII码的扩展区域(0xA0以后)来表示一个汉字,该方法的标准叫GB-2312。后来,日文、韩文、阿拉伯文、台湾繁体(BIG-5)……都使用类似的方法扩展了本地字符集的定义,现在统一称为 MBCS 字符集(多字节字符集)。这个方法是有缺陷的,因为各个国家地区定义的字符集有交集,因此使用GB-2312的软件,就不能在BIG-5的环境下运行(显示乱码),反之亦然。
为了把全世界人民所有的所有的文字符号都统一进行编码,于是制定了UNICODE标准字符集。UNICODE 使用2个字节表示一个字符,现在的unicode的合理取值范围已经从0x0000-0xffff扩展到了0x0000-0x10ffff。
在unicode中,称0x0000-0xffff的字符集为基本多文种平面,俗称BMP。而值大于0xffff的字符称为增补字符。在java中一个char的值能够表示着BMP中的一个代码点(也包括代理代码点或者代理单元的UTF-16编码)。而一个int的值可以表示所有的unicode的所有的代码点,当然也包括那些补足字符。一个int(32位)的右边的21位用来表示unicode的代码点,而前面的11位除非一些特殊情况(有补足字符和代理代码点),全部填充为0。
3. UnicodeBlock
UnicodeBlock是一个根据unicdoe数据库和unicode标准对字符集划分子集的一个抽象。每个字符最多被指向为一个UnicodeBlock。比如Basic Latin的范围是0x0000-0x007f,那么就有一个UnicodeBlock来对其进行抽象。
3.1 UnicodeBlock构造函数
UnicodeBlock的构造函数主要接受一个字符子集的名字(String)或者字符子集的别名(String)来填充map(一个HashMap)。代码如下:
private static Map<String, UnicodeBlock> map = new HashMap<>(256);
private UnicodeBlock(String idName) {
super(idName);
map.put(idName, this);
}
private UnicodeBlock(String idName, String alias) {
this(idName);
map.put(alias, this);
}
//一个字符子集可能有多个别名
private UnicodeBlock(String idName, String... aliases) {
this(idName);
for (String alias : aliases)
map.put(alias, this);
}
//实例化各种UnicodeBlock
public static final UnicodeBlock BASIC_LATIN =new UnicodeBlock("BASIC_LATIN","BASIC LATIN","BASICLATIN");
public static final UnicodeBlock LATIN_1_SUPPLEMENT =new UnicodeBlock("LATIN_1_SUPPLEMENT","LATIN-1 SUPPLEMENT","LATIN-1SUPPLEMENT");
...类似部分省略3.2 of方法
如果想要根据一个给定的字符(char)或者一个代码点(int)来查找出这个字符做对应的UnicodeBlock的话,of方法可以实现这个功能。代码如下:
public static UnicodeBlock of(int codePoint) {
if (!isValidCodePoint(codePoint)) {
throw new IllegalArgumentException();
}
int top, bottom, current;
bottom = 0;
top = blockStarts.length;
current = top/2;
// invariant: top > current >= bottom && codePoint >= unicodeBlockStarts[bottom]
while (top - bottom > 1) {
if (codePoint >= blockStarts[current]) {
bottom = current;
} else {
top = current;
}
current = (top + bottom) / 2;
}
return blocks[current];
}
//这个方法不支持补足字符,因为用int强转了char。
public static UnicodeBlock of(char c) {
return of((int)c);
}我们来分析一下是怎样从codePoint然后映射出UnicodeBlock的。
1.判断codePoint是否有效
判断codePoint是否有效的代码是这样的:
public static boolean isValidCodePoint(int codePoint) {
// Optimized form of:
// codePoint >= MIN_CODE_POINT && codePoint <= MAX_CODE_POINT
int plane = codePoint >>> 16;
return plane < ((MAX_CODE_POINT + 1) >>> 16);
}这段代码的判断思路是判断codePoint是否在MIN_CODE_POINT(0x000000)和MAX_CODE_POINT(0X10FFFF)之间,但代码作者对这个判断进行了优化。之所以这样优化是因为非增补字符的范围是0x0000-0xffff,高16位都是0,而增补字符就不一定了。所以
codePoint >>> 16可以提取出高16位的位信息。又由于codePoint的合理的最大值是MAX_CODE_POINT(0X10FFFF),自然而然的plane < ((MAX_CODE_POINT + 1) >>> 16)就是用来判断codePoint的高16位是否比MAX_CODE_POINT+1的高16位小。这就达成了codePoint <= MAX_CODE_POINT的判断效果。那么codePoint >= MIN_CODE_POINT的判断从何而来?其实plane < ((MAX_CODE_POINT + 1) >>> 16)已经做到了codePoint >= MIN_CODE_POINT的效果,因为如果是非增补字符,那么plane妥妥的是0,如果codePoint是个负数,那么plane < ((MAX_CODE_POINT + 1) >>> 16)妥妥的不会成立。(此时的低16位的高位为1)
2.二分查找UnicodeBlock
通过使用二分查找codePoint所对应的UnicodeBlock。其中blockStarts是一个int数组,每个坑都记录了对应UnicodeBlock的codePoint的最小值,并且是最小值是升序排列,代码如下:
private static final int blockStarts[] = {
0x0000, // 0000..007F; Basic Latin
0x0080, // 0080..00FF; Latin-1 Supplement
0x0100, // 0100..017F; Latin Extended-A
0x0180, // 0180..024F; Latin Extended-B
0x0250, // 0250..02AF; IPA Extensions
0x02B0, // 02B0..02FF; Spacing Modifier Letters
0x0300, // 0300..036F; Combining Diacritical Marks
0x0370, // 0370..03FF; Greek and Coptic
0x0400, // 0400..04FF; Cyrillic
0x0500, // 0500..052F; Cyrillic Supplement
0x0530, // 0530..058F; Armenian
0x0590, // 0590..05FF; Hebrew
0x0600, // 0600..06FF; Arabic
0x0700, // 0700..074F; Syriac
//下面的已省略
}4. UnicodeScript
Unicode中一种Script通常就是一个字符或者其他书写符号的集合,代表着一种或多种writing systems。有些Script仅支持一种文字类型,有些可以支持多种,例如 Latin Script 支持 supports English, French, German, Italian, Vietnamese, Latin等等。
如果说UnicodeBlock是按代码点的二进制编码来对字符集进行划分的话,那么UnicodeScript则相当于按照使用的角度来对字符集进行划分。
在jdk的源码中,UnicodeScript只是一个枚举,并不像UnicodeBlock一样是一个内部类。但同样有of方法,能够根据代码点返回对应的Script。代码如下:
public static UnicodeScript of(int codePoint) {
if (!isValidCodePoint(codePoint))
throw new IllegalArgumentException();
int type = getType(codePoint);
// leave SURROGATE and PRIVATE_USE for table lookup
if (type == UNASSIGNED)
return UNKNOWN;
int index = Arrays.binarySearch(scriptStarts, codePoint);
if (index < 0)
index = -index - 2;
return scripts[index];
}整个算法就是一个二分查找,但要注意的是,binarySearch时经常会找不到codePoint,然后会返回codePoint的插入点,所以index=-index-2。
5. 代码点的各种判断
5.1 public static boolean isBmpCodePoint(int codePoint)
判断代码点是不是BMP,其实只要看高16位是否为0即可,代码如下:
public static boolean isBmpCodePoint(int codePoint) {
return codePoint >>> 16 == 0;
// Optimized form of:
// codePoint >= MIN_VALUE && codePoint <= MAX_VALUE
// We consistently use logical shift (>>>) to facilitate
// additional runtime optimizations.
}5.2 public static boolean isSupplementaryCodePoint(int codePoint)
判断代码点是不是补足字符,其实只是检查代码点的范围,代码如下:
public static boolean isSupplementaryCodePoint(int codePoint) {
//0x010000~0X10FFFF
return codePoint >= MIN_SUPPLEMENTARY_CODE_POINT
&& codePoint < MAX_CODE_POINT + 1;
}5.3 public static boolean isHighSurrogate(char ch)和public static boolean isLowSurrogate(char ch)
判断字符属不属于高低代理(UTF-16遇到补足字符时会用到),其实也是检查字符的范围,代码如下:
public static boolean isHighSurrogate(char ch) {
// Help VM constant-fold; MAX_HIGH_SURROGATE + 1 == MIN_LOW_SURROGATE
return ch >= MIN_HIGH_SURROGATE && ch < (MAX_HIGH_SURROGATE + 1);
}
public static boolean isLowSurrogate(char ch) {
return ch >= MIN_LOW_SURROGATE && ch < (MAX_LOW_SURROGATE + 1);
}下面将对代理和UTF-16的概念进行描述:
代理: 所谓的代理就是Unicode标准将代理项对定义为由两个代码单元序列组成的单个抽象字符的编码字符表示形式。 代理项对的第一个值是高代理项,它是一个介于 U+D800和U+DBFF之间的16位代码值。代理项对的第二个值是低代理项,它是一个介于U+DC00和U+DFFF之间的值。这两个代理区域不是有效的代码点,而是给UTF-16保留下来的,主要用途就是让UTF-16能够对BMP之外的字符,也就是补足字符进行编码。UTF-16中采用的这种设计方法分配1024值给16位高代理,将另外的1024值分配给16位低代理。它使用一个代理对来表示65536(0x10000)和1114111(0x10FFFF) 之间的1048576个(0x100000)值(1024和1024的乘积)。
UTF-16: UTF-16是Unicode的一种编码方式,它用两个字节来编码BMP里的代码点,用四个字节编码其余平面里的代码点(暂不考虑字节顺序)。由于BMP里只有65535个代码点,所以直接把代码点转换成2个字节就可以了。BMP之外的平面稍微复杂一点,需要先将代码点转化为一个代理对,然后再转为4个字节。举个栗子:假设要编码的补足字符集内的代码点为X,具体的编码过程为:
1. X必定在0x010000到0x10FFFF之间
2. 将X减去0x010000,得到的数在0x0到0xFFFFF之间,正好可以用20个bit来表示
3. 将高位的10个bit和0xD800相加,将地位的10个比特和0xDC00相加,得到的正好是一个代理对,也就是四个字节。
5.4 public static boolean isSurrogate(char ch)
检查字符属不属于代理(UTF-16遇到补足字符时会用到),当一个char属于代理时当且仅当char属于高代理或者低代理,代码如下:
public static boolean isSurrogate(char ch) {
return ch >= MIN_SURROGATE && ch < (MAX_SURROGATE + 1);
}5.5 public static boolean isSurrogatePair(char high, char low)
检查两个字符是不是属于一代理对。代码如下:
public static boolean isSurrogatePair(char high, char low) {
return isHighSurrogate(high) && isLowSurrogate(low);
}5.4 public static boolean isSurrogate(char ch)
检查字符属不属于代理(UTF-16遇到补足字符时会用到),当一个char属于代理时当且仅当char属于高代理或者低代理,代码如下:
public static boolean isSurrogate(char ch) {
return ch >= MIN_SURROGATE && ch < (MAX_SURROGATE + 1);
}5.5 public static boolean isSurrogatePair(char high, char low)
检查两个字符是不是属于一代理对。代码如下:
public static boolean isSurrogatePair(char high, char low) {
return isHighSurrogate(high) && isLowSurrogate(low);
}5.6 public static int charCount(int codePoint)
返回所给代码点所需要的字符数,如果是补充字符则为2个字符,否则为1个字符(非补充字符只需要2个字节,也就是1个字符)。代码如下:
public static int charCount(int codePoint) {
return codePoint >= MIN_SUPPLEMENTARY_CODE_POINT ? 2 : 1;
}5.7 public static int toCodePoint(char high, char low)
将一对代理项对转换成一个代码点,其实转换过程就是将代码点转换成代理项对的逆过程(5.3中提到过)。代码如下:
public static int toCodePoint(char high, char low) {
// Optimized form of:
// return ((high - MIN_HIGH_SURROGATE) << 10)
// + (low - MIN_LOW_SURROGATE)
// + MIN_SUPPLEMENTARY_CODE_POINT;
return ((high << 10) + low) + (MIN_SUPPLEMENTARY_CODE_POINT
- (MIN_HIGH_SURROGATE << 10)
- MIN_LOW_SURROGATE);
}














 6875
6875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











