







一、同步异步、阻塞非阻塞的概念区分
首先,一个 输入操作通常包括两个不同的阶段:
(1)等待数据准备好
(2)从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从缓冲区复制到应用进程缓冲区。
1.同步与异步
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由调用者主动等待这个调用的结果。
而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
2.阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
举个例子来帮助理解同步异步、阻塞非阻塞:
假如你用水壶烧水。
(1)你把普通水壶放在电磁炉上,站在一旁等水开。(同步阻塞)
(2)你把普通水壶放在电磁炉上,然后去客厅看电视了,时不时去厨房看看水开了没有。(同步非阻塞)
(3)你把煮开时会发出提示声的改进水壶放在电磁炉上,站在一旁等水开。(异步阻塞)
(4)你把煮开时会发出提示声的改进水壶放在电磁炉上,然后去客厅看电视了,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
对于访问数据,阻塞非阻塞是说针对在得知访问的数据是否就绪这一问题,进程/线程是否需要等待(在此期间不能做其它事),同步异步是说进程/线程是否需要主动读写数据,同步则是需要主动读写数据,在读写数据的过程中还是会阻塞,异步则是只需要I/O操作完成的通知,进程/线程并不主动读写数据,由操作系统内核完成数据的读写。
二、Unix下的5种IO模型
- 阻塞式IO
- 非阻塞式IO
- IO复用
- 信号驱动式IO
异步IO
POSIX把同步IO和异步IO定义如下:
- 同步IO操作导致请求进程阻塞,直到IO操作完成。
- 异步IO操作不导致请求进程阻塞。
这五种IO模型里前四种都属于同步IO。
(一)阻塞式IO模型
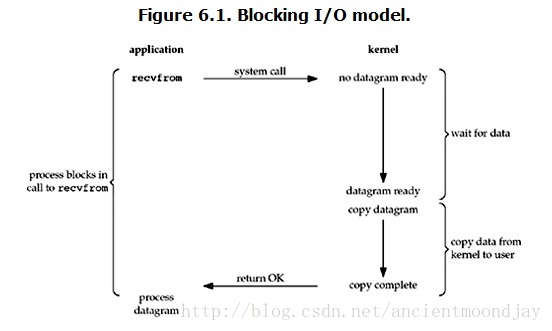
最流行的IO模型是阻塞式IO,默认情形下,所有套接字都是阻塞的。
如图,此处recvfrom视为一个系统调用用以IO操作。当进程调用recvfrom时,内核就开始了IO的第一个阶段:准备数据。对于网络IO来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候内核就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当内核一直等到数据准备好了,它就会将数据从内核中拷贝到用户空间,然后内核返回结果,用户进程才解除阻塞的状态,开始处理数据。
所以,阻塞式 IO的特点就是在IO执行的两个阶段都被block了。这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
(二)非阻塞式IO模型
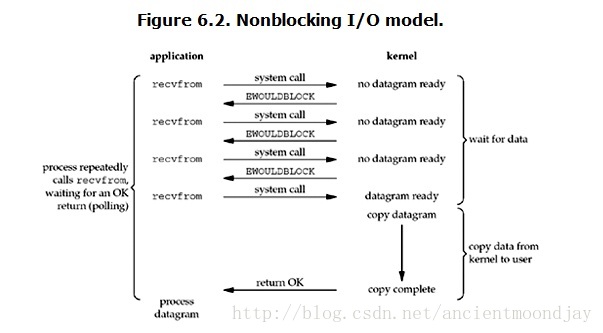
进程把一个套接字设置成非阻塞是在通知内核:当所请求的IO操作非得把本进程投入睡眠才能完成时,不要把本进程投入睡眠,而是返回一个错误。
也就是说,当用户进程发出recvfrom操作时,如果内核中的数据还没有准备好,那么它并不会阻塞用户进程,而是立刻返回一个EWOULDBLOCK错误。从用户进程角度讲 ,它发起一个recvfrom操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送recvfrom操作。一旦某次再次调用recvfrom时内核中的数据准备好了,那么内核马上就将数据拷贝到了用户空间,然后返回。
所以,整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。
(三)IO复用模型
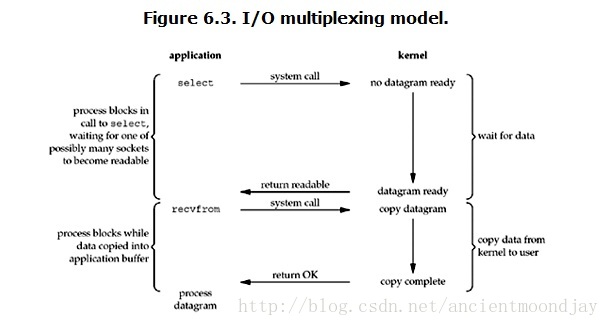
有了IO复用,我们就可以调用select或poll或epoll,阻塞在这三个函数之上,而不是阻塞在真正的IO系统调用上。就拿select来说吧,进程阻塞于select调用 ,此时内核会监视所有select负责的套接字,当任何一个socket中的数据准备好了,select就会返回可读条件,之后用户进程就可以调用recvfrom直接让内核将数据拷贝到用户空间。使用select需要两个而不是单个系统调用,使用select的优势在于可以等待多个描述符就绪。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
(四)信号驱动式IO模型
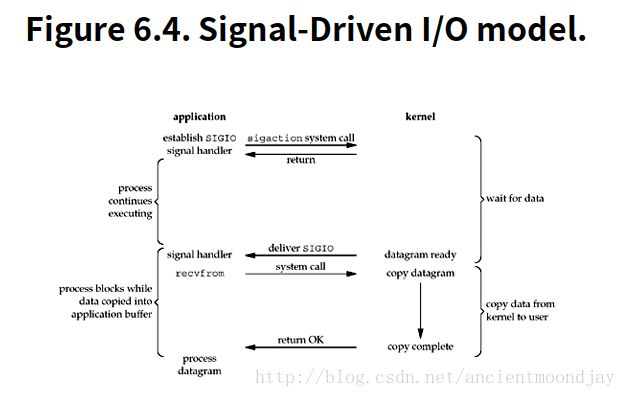
用户进程首先开启套接字的信号驱动式IO功能,并通过sigaction系统调用安装一个信号处理函数。该系统调用将立即返回,用户进程可以继续做其它的事,也就是说它没有被阻塞。当数据报准备好供读取时,内核就为该进程产生一个SIGIO信号。用户进程随后在信号处理函数中调用recvfrom直接让内核将数据拷贝到用户空间。
(五)异步IO模型
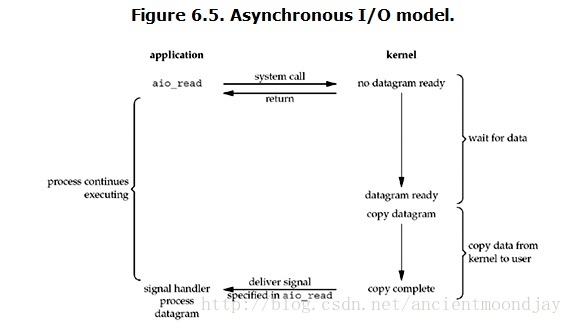
用户进程发起aio_read操作之后,立刻就可以开始做其它的事。在这期间,内核会在整个操作(包括等待数据和将数据从内核拷贝到用户空间)完成后给用户进程发送一个信号来通知。这种模型与信号驱动式IO模型的主要区别在于:信号驱动式IO是由内核通知用户进程何时可以启动一个IO操作,而异步IO模型是由内核通知用户进程IO操作何时完成了。
最后贴出5种IO模型的直观比较:

三、select函数
select函数允许进程指示内核等待多个事件中的任何一个发生,并只在有一个或多个事件发生或经历一段指定的时间后才唤醒它。
(一)select函数及参数说明:
#include <sys/select.h>
#include <sys/time.h>
int select(int maxfdp1, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
//返回:若有就绪描述符则返回就绪描述符的数目,若超时返回0,若出错返回-1 1.timeout:告知内核等待指定描述符中任何一个就绪花费的最长时间,其timeval结构用于指定秒数和微妙数。
//timeval结构:
struct timeval
{
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
}; 这个参数有以下三种可能:
timeout== NULL:永远等待下去,即仅当一个描述符准备好I/O时才返回。
timeout->tv_sec != 0 || tvptr->tv_usec !=0:等待一段固定的时间,超时返回0;在这段时间内如果有描述符准备好就返回。
timeout->tv_sec == 0 && tvptr->tv_usec == 0:根本不等待,即检查描述符后立即返回,这称为轮询(非阻塞式I/O就是轮询)。
2.中间的三个参数:指定要让内核测试读、写、异常的描述符,若对某一个不感兴趣可置为NULL。
这三个参数都是值-结果参数,调用函数时,用于指定所关心的描述符的值;函数返回时,结果将指示哪些描述符已经就绪。该函数返回后,使用FD_ISSET宏来测试fd_set数据类型中的描述符。描述符集内任何与未就绪描述符对应的位返回时均清为0。为此,每次重新调用select函数时,我们都得再次把所有描述符集内所关心的位均置为1.
select使用描述符集,通常是一个整数数组,其中每个整数的一位对应一个描述符。举例来说,假设使用32位整数,那么该数组的第一个元素对应于描述符0~31,第二个元素对应于描述符32~63,依此类推。所有这些实现细节都与应用程序无关,它们隐藏在为fd_set的数据类型和以下四个宏中:
FD_CLR(int fd, fd_set *set); //关闭fd_set中的fd位
FD_ISSET(int fd, fd_set *set); //测试该位是否打开,如果为1则该位对应描述符就绪
FD_SET(int fd, fd_set *set); //打开该fd位
FD_ZERO(fd_set *set); //清空所有位 如下打开描述符1、4位:
fd_set rset;
FD_ZERO(&rset); //清空所有,每次调用select都要清空为0
FD_SET(1,&rset); //打开描述符1
FD_SET(4,&rset); //打开描述符43.maxfdp1参数指定待测试的描述符的个数,其值为最大待测试描述符加1。例如上例打开1、4描述符,那么这里maxfdp1值为5。
(二)select的特点
1.最大并发数限制:因为一个进程所打开的 FD (文件描述符)是有限制的,由 FD_SETSIZE 设置,默认值是 1024,因此 Select 模型的最大并发数就被相应限制了。如果要改变FD_SIZE的大小需要重新编译内核。
2.效率问题:select 每次调用都会线性扫描全部的 FD 集合,花费时间为O(n),这样效率就会呈现线性下降,即使将 FD_SETSIZE 改大其性能也会很差。
3. 内核/用户空间内存拷贝问题:select 采取了内存拷贝方法让内核把 FD 消息通知给用户空间。
4.事件集:select的参数类型fd_set没有将文件描述符和事件绑定,它仅仅是一个文件描述符的集合,因此select需要提供3个“值-结果”类型的参数分别传入和输出可读、可写和异常等事件(调用该函数时,指定所关心的描述符的值,函数返回时,结果将指示哪些描述符已经就绪),也就是select函数会修改指针readset、writeset、exceptset所指向的描述符集。
一方面,使得select不能处理更多类型的事件,所能处理的事件类型只有读写异常三类;
另一方面,描述符集内任何与未就绪描述符对应的位返回时都会被清空,因此每次重新调用select时,都需要再次把所有的描述符集内所关心的位置为1。
5.select函数的定时是由函数的最后一个参数决定的,它是一个timeval结构体,用于指定这段时间的秒数和微秒数。
四、poll函数
(一)poll函数及其参数说明
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
//返回:如有就绪描述符就返回其数目,超时返回0,若出错返回-1.1.第一个参数是指向一个结构数组第一个元素的指针。每个元素是一个pollfd结构,用于指定测试某个给定描述符fd的条件。
//pollfd结构体
struct pollfd
{
int fd; /* file descriptor :要测试的描述符*/
short events; /* requested events: 要测试的事件 */
short revents; /* returned events : 返回该描述符的状态*/
}; pollfd结构的成员events和revents避免了使用值-结果参数。这点与select不同。
用于指定这两个成员的一些常值如下:

2.第二个参数nfds:指定第一个参数结构数组中元素的个数。
3.第三个参数timeout:指定poll函数返回前等待多长时间。

INFTIM常值被定义为一个负值。
当发生错误时,poll函数的返回值为-1,若定时器到时之前没有任何描述符就绪,则返回0,否则返回就绪描述符的个数,即revents成员值非0的描述符个数。
如果我们不关心某个特定描述符,那么可以把与它对应的pollfd结构的fd成员设置成一个负值。poll函数将忽略这样的pollfd结构的events成员,返回时将它们的revents成员的值置为0。
(二)poll的特点
1.最大并发数限制:poll的第二个参数nfds是第一个参数指示的结构数据的元素个数,这个nfds并没有select的限制,它只受限于系统的内存空间(可以达到系统所允许打开的最大描述符的个数,即65535)。
2.效率问题:效率和select类似。
3.内核/用户空间内存拷贝问题:和select类似。
4.事件集:poll比select要“聪明”,它将描述符和事件定义在一起,任何事件都被统一处理,编程接口简洁许多。
一方面,poll可以监听的事件类型就可以更细分为很多种。
另一方面,而且内核每次修改的是pollfd结构体的revents成员,而events成员不变,因此下次重新调用poll无需重置pollfd类型中的事件集参数(避免了类似于select使用的的“值-结果”参数)。
5.poll的定时也是由函数的最后一个参数给出,但是它是一个int类型(指定函数要等待的毫秒数),而不是timeval结构体。
五、epoll函数
(一)epoll类的三个函数
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); 1.int epoll_create(int size);
创建一个epoll的句柄,之后的所有操作将通过这个句柄来进行操作。size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数那样给出最大监听的fd+1的值。自从linux2.6.8之后,size参数是被忽略的,只要它比0大就可以。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2.int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









