







转自CSDN July 原文http://blog.csdn.net/v_JULY_v/archive/2010/12/23/6093380.aspx
感谢大佬
算法研究系列:精选24个经典的算法[一、A*搜索算法]
----July/编写
==============
接下来,本人将写一经典算法研究系列,仅供各位和我自己学习、研究和参考之用。
有误之处,还望各位不吝指正。
本文主要参考:Google、算法导论。
转载,请注明出处。永远,向您的厚道致敬。谢谢。
欢迎,各位,与我一同学习探讨,交流研究。
有误之处,不吝指正。
-------------------------------------------
1.A* 搜寻算法
1968年,的一篇论文,“P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths in graphs. IEEE Trans. Syst. Sci. and Cybernetics, SSC-4(2):100-107, 1968”。从此,一种精巧、高效的算法------A*算法横空出世了,并在相关领域得到了广泛的应用。
DFS和BFS在展开子结点时均属于盲目型搜索,也就是说,它不会选择哪个结点在下一次搜索中更优而去跳转到该结点进行下一步的搜索。在运气不好的情形中,均需要试探完整个解集空间, 显然,只能适用于问题规模不大的搜索问题中。
那么,作为启发式算法中的A*算法,又比它们高效在哪里呢?
首先要来谈一下什么是启发式算法。所谓启发式搜索,与DFS和BFS这类盲目型搜索最大的不同,就在于当前搜索结点往下选择下一步结点时,可以通过一个启发函数来进行选择,选择代价最少的结点作为下一步搜索结点而跳转其上(遇到有一个以上代价最少的结点,不妨选距离当前搜索点最近一次展开的搜索点进行下一步搜索)。一个经过仔细设计的启发函数,往往在很快的时间内就可得到一个搜索问题的最优解,对于NP问题,亦可在多项式时间内得到一个较优解。
是的,关键就是如何设计这个启发函数。
A*算法,作为启发式算法中很重要的一种,被广泛应用在最优路径求解和一些策略设计的问题中。而A*算法最为核心的部分,就在于它的一个估值函数的设计上:
f(n)=g(n)+h(n)
其中f(n)是每个可能试探点的估值,它有两部分组成:
一部分为g(n),它表示从起始搜索点到当前点的代价(通常用某结点在搜索树中的深度来表示)。
另一部分,即h(n),它表示启发式搜索中最为重要的一部分,即当前结点到目标结点的估值,
h(n)设计的好坏,直接影响着具有此种启发式函数的启发式算法的是否能称为A*算法。
一种具有f(n)=g(n)+h(n)策略的启发式算法能成为A*算法的充分条件是:
1)搜索树上存在着从起始点到终了点的最优路径。
2)问题域是有限的。
3)所有结点的子结点的搜索代价值>0。
4)h(n)=<h*(n) (h*(n)为实际问题的代价值)。
当此四个条件都满足时,一个具有f(n)=g(n)+h(n)策略的启发式算法能成为A*算法,并一定能找到最优解。([1]P89给出了相关的证明)
对于一个搜索问题,显然,条件1,2,3都是很容易满足的,而
条件4): h(n)<=h*(n)是需要精心设计的,由于h*(n)显然是无法知道的,
所以,一个满足条件4)的启发策略h(n)就来的难能可贵了。
不过,对于图的最优路径搜索和八数码问题,有些相关策略h(n)不仅很好理解,而且已经在理论上证明是满足条件4)的,从而为这个算法的推广起到了决定性的作用。不过h(n)距离h*(n)的呈度不能过大,否则h(n)就没有过强的区分能力,算法效率并不会很高。对一个好的h(n)的评价是:h(n)在h*(n)的下界之下,并且尽量接近h*(n).
继续深入之前,再来看下维基百科对本A*搜索算法的解释:
A*搜寻算法,俗称A星算法。这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法。常用于游戏中的NPC的移动计算,或线上游戏的BOT的移动计算上。
该算法像Dijkstra算法一样,可以找到一条最短路径;也像BFS一样,进行启发式的搜索。
在此算法中,g(n)表示从起点到任意顶点n的实际距离,h(n)表示任意顶点n到目标顶点的估算距离。因此,A*算法的公式为:f(n)=g(n)+h(n)。这个公式遵循以下特性:
如果h(n)为0,只需求出g(n),即求出起点到任意顶点n的最短路径,则转化为单源最短路径问题,即Dijkstra算法
如果h(n)<=n到目标的实际距离,则一定可以求出最优解。而且h(n)越小,需要计算的节点越多,算法效率越低。
ok,来看下,此A*搜寻算法的算法实现:
closedset := the empty set //已经被估算的节点集合
openset := set containing the initial node //将要被估算的节点集合
g_score[start] := 0 //g(n)
h_score[start] := heuristic_estimate_of_distance(start, goal) //f(n)
f_score[start] := h_score[start]
while openset is not empty
x := the node in openset having the lowest f_score[] value
if x = goal
return reconstruct_path(came_from,goal)
remove x from openset
add x to closedset
for each y in neighbor_nodes(x)
if y in closedset
continue
tentative_g_score := g_score[x] + dist_between(x,y)
if y not in openset
add y to openset
tentative_is_better := true
else if tentative_g_score < g_score[y]
tentative_is_better := true
else
tentative_is_better := false
if tentative_is_better = true
came_from[y] := x
g_score[y] := tentative_g_score
h_score[y] := heuristic_estimate_of_distance(y, goal)
f_score[y] := g_score[y] + h_score[y]
return failure
function reconstruct_path(came_from,current_node)
if came_from[current_node] is set
p = reconstruct_path(came_from,came_from[current_node])
return (p + current_node)
else
return the empty path
再看下,A*搜寻算法核心部分的算法实现之C语言版本:
A*算法流程:
首先将起始结点S放入OPEN表,CLOSE表置空,算法开始时:
1、如果OPEN表不为空,从表头取一个结点n,如果为空算法失败
2、n是目标解吗?是,找到一个解(继续寻找,或终止算法);
3、将n的所有后继结点展开,就是从n可以直接关联的结点(子结点),如果不在CLOSE表中,就将它们放入OPEN表,并把S放入CLOSE表,同时计算每一个后继结点的估价值f(n),将OPEN表按f(x)排序,最小的放在表头,重复算法,回到1。
最短路径问题,Dijkstra算法与A*
A*是求这样一个和最短路径有关的问题,那单纯的最短路径问题当然可以用A*来算,对于g(n)就是[S,n],在搜索过程中计算,而h(n)我想不出很好的办法,对于一个抽象的图搜索,很难找到很好的h(n),因为h(n)和具体的问题有关。只好是h(n)=0,退为有序搜索,举一个小小的例子:
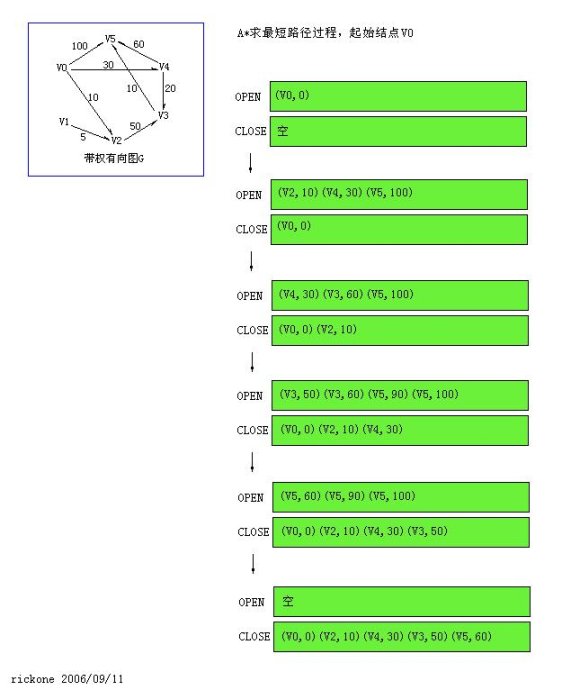
//是的,图片是引用rickone 的。
与结点写在一起的数值表示那个结点的价值f(n),
当OPEN表为空时CLOSE表中将求得从V0到其它所有结点的最短路径。
考虑到算法性能,外循环中每次从OPEN表取一个元素,共取了n次(共n个结点),每次展开一个结点的后续结点时,需O(n)次,同时再对OPEN表做一次排序,OPEN表大小是O(n)量级的,若用快排就是O(nlogn),乘以外循环总的复杂度是O(n^2logn),
如果每次不是对OPEN表进行排序,因为总是不断地有新的结点添加进来,所以不用进行排序,而是每次从OPEN表中求一个最小的,那只需要O(n)的复杂度,所以总的复杂度为O(n*n),这相当于Dijkstra算法。
在这个算法基础之上稍加改进就是Dijkstra算法。OPEN表中常出现这样的表项:(Vk,fk1)(Vk,fk2)(Vk,fk3),而从算法上看,只有fk最小的一个才有用,于是可以将它们合并,整个OPEN表表示当前的从V0到其它各点的最短路径,定长为n,且初始时为V0可直接到达的权值(不能到达为INFINITY),于是就成了Dijkstra算法。
本文完。以下内容不纳入本文范围。
----------------------------
附:
A*搜索算法 在八数码问题中应用,c 实现源码(欢迎指正):
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
//节点结构体
typedef struct Node
{
int data[9];
double f,g;
struct Node * parent;
}Node,*Lnode;
//OPEN CLOSED 表结构体
typedef struct Stack
{
Node * npoint;
struct Stack * next;
}Stack,* Lstack;
//选取OPEN表上f值最小的节点,返回该节点地址
Node * Minf(Lstack * Open)
{
Lstack temp = (*Open)->next,min = (*Open)->next,minp = (*Open);
Node * minx;
while(temp->next != NULL)
{
if((temp->next ->npoint->f) < (min->npoint->f))
{
min = temp->next;
minp = temp;
}
temp = temp->next;
}
minx = min->npoint;
temp = minp->next;
minp->next = minp->next->next;
free(temp);
return minx;
}//判断是否可解
int Canslove(Node * suc, Node * goal)
{
int a = 0,b = 0,i,j;
for(i = 1; i< 9;i++)
for(j = 0;j < i;j++)
{
if((suc->data[i] > suc->data[j]) && suc->data[j] != 0)
a++;
if((goal->data[i] > goal->data[j]) && goal->data[j] != 0)
b++;
}
if(a%2 == b%2)
return 1;
else
return 0;
}
//判断节点是否相等 ,1相等,0不相等
int Equal(Node * suc,Node * goal)
{
for(int i = 0; i < 9; i ++ )
if(suc->data[i] != goal->data[i])
return 0;
return 1;
}//判断节点是否属于OPEN表 或 CLOSED表,是则返回节点地址,否则返回空地址
Node * Belong(Node * suc,Lstack * list)
{
Lstack temp = (*list) -> next ;
if(temp == NULL)
return NULL;
while(temp != NULL)
{
if(Equal(suc,temp->npoint))
return temp -> npoint;
temp = temp->next;
}
return NULL;
}
//把节点放入OPEN 或CLOSED 表中
void Putinto(Node * suc,Lstack * list)
{
Stack * temp;
temp =(Stack *) malloc(sizeof(Stack));
temp->npoint = suc;
temp->next = (*list)->next;
(*list)->next = temp;
}//计算f值部分-开始
double Fvalue(Node suc, Node goal, float speed)
{
//计算f值
double Distance(Node,Node,int);
double h = 0;
for(int i = 1; i <= 8; i++)
h = h + Distance(suc, goal, i);
return h*speed + suc.g;
//f = h + g;
//speed值增加时搜索过程以找到目标为优先因此可能不会返回最优解
}double Distance(Node suc, Node goal, int i)
{
//计算方格的错位距离
int k,h1,h2;
for(k = 0; k < 9; k++)
{
if(suc.data[k] == i)h1 = k;
if(goal.data[k] == i)h2 = k;
}
return double(fabs(h1/3 - h2/3) + fabs(h1%3 - h2%3));
}//计算f值部分-结束
//扩展后继节点部分的函数-开始
int BelongProgram(Lnode * suc ,Lstack * Open ,Lstack * Closed ,Node goal ,float speed)
{
//判断子节点是否属于OPEN或CLOSED表 并作出相应的处理
Node * temp = NULL;
int flag = 0;
if((Belong(*suc,Open) != NULL) || (Belong(*suc,Closed) != NULL))
{
if(Belong(*suc,Open) != NULL)
temp = Belong(*suc,Open);
else
temp = Belong(*suc,Closed);
if(((*suc)->g) < (temp->g))
{
temp->parent = (*suc)->parent;
temp->g = (*suc)->g;
temp->f = (*suc)->f;
flag = 1;
}
}
else
{
Putinto(* suc, Open);
(*suc)->f = Fvalue(**suc, goal, speed);
}
return flag;
}//判断空格可否向该方向移动1,2,3,4表示空格向上向下向左向右移
int Canspread(Node suc, int n)
{
int i,flag = 0;
for(i = 0;i < 9;i++)
if(suc.data[i] == 0)break;
switch(n)
{
case 1:if(i/3 != 0)
flag = 1;break;
case 2:
if(i/3 != 2)
flag = 1;break;
case 3:
if(i%3 != 0)
flag = 1;break;
case 4:
if(i%3 != 2)
flag = 1;break;
default:break;
}
return flag ;
}
//扩展child节点的字节点n表示方向0,1,2,3表示空格向上向下向左向右移
void Spreadchild(Node * child,int n)
{
int i,loc,temp;
for(i = 0;i < 9;i++)
child->data[i] = child->parent->data[i];
for(i = 0;i < 9;i++)
if(child->data[i] == 0)
break;
if(n==0)
loc = i%3+(i/3 - 1)*3;
else if(n==1)
loc = i%3+(i/3 + 1)*3;
else if(n==2)
loc = i%3-1+(i/3)*3;
else
loc = i%3+1+(i/3)*3;
temp = child->data[loc];
child->data[i] = temp;
child->data[loc] = 0;
}
//扩展后继节点总函数
void Spread(Lnode * suc, Lstack * Open, Lstack * Closed, Node goal, float speed)
{
int i;
Node * child;
for(i = 0; i < 4; i++)
{
if(Canspread(**suc, i+1))
//判断某个方向上的子节点可否扩展
{
//扩展子节点
child = (Node *) malloc(sizeof(Node));
child->g = (*suc)->g +1;
//算子节点的g值
child->parent = (*suc);
//子节点父指针指向父节点
Spreadchild(child, i);
//向该方向移动空格生成子节点
if(BelongProgram(&child, Open, Closed, goal, speed))
// 判断子节点是否属于OPEN或CLOSED表并作出相应的处理
free(child);
}
}
}//扩展后继节点部分的函数-结束
Node * Process(Lnode * org, Lnode * goal, Lstack * Open, Lstack * Closed, float speed)
{
//总执行函数
while(1)
{
if((*Open)->next == NULL)return NULL;
//判断OPEN表是否为空,为空则失败退出
Node * minf = Minf(Open);
//从OPEN表中取出f值最小的节点
Putinto(minf, Closed);
//将节点放入CLOSED表中
if(Equal(minf, *goal))return minf;
//如果当前节点是目标节点,则成功退出
Spread(&minf, Open, Closed, **goal, speed);
//当前节点不是目标节点时扩展当前节点的后继节点
}
}//递归显示从初始状态到达目标状态的移动方法
int Shownum(Node * result)
{
if(result == NULL)return 0;
else
{
int n = Shownum(result->parent);
for(int i = 0; i < 3; i++)
{
printf("/n");
for(int j = 0; j < 3; j++)
{
if(result->data[i*3+j] != 0)
printf(" %d ",result->data[i*3+j]);
else printf(" ");
}
}
printf("/n");
return n+1;
}
}
//检查输入
void Checkinput(Node *suc)
{
int i = 0,j = 0,flag = 0;
char c;
while(i < 9)
{
while(((c = getchar()) != 10))
{
if(c == ' ')
{
if(flag >= 0)flag = 0;
}
else if(c >= '0' && c <= '8')
{
if(flag == 0)
{
suc->data[i] = (c-'0');
flag = 1;
for(j =0; j < i; j++)
if(suc->data[j] == suc->data[i])flag = -2;
i++;
}
else if(flag >= 0)flag = -1;
}
else
if(flag >= 0)flag = -1;
}
if(flag <0 || i < 9)
{
if(flag < 0)
{
if(flag == -1)
printf("含有非法字符或数字!/n请重新输入:/n");
else if(flag == -2)
printf("输入的数字有重复!/n请重新输入:/n");
}
else if(i < 9)
printf("输入的有效数字不够!/n请重新输入:/n");
i = 0;
flag = 0;
}
}
}void main()
{
//主函数
//初始操作,建立open和closed表
Lstack Open = (Stack *) malloc(sizeof(Stack));
Open->next = NULL;
Lstack Closed = (Stack *) malloc(sizeof(Stack));
Closed->next = NULL;
Node * org = (Node *) malloc(sizeof(Node));
org->parent = NULL; //初始状态节点
org->f =1;
org->g =1;
Node * goal = (Node *) malloc(sizeof(Node)); //目标状态节点
Node * result;
float speed = 1;//speed搜索速度
char c;
printf("0-8 9个数字以空格隔开,回车表示输入结束/n");
printf("-----------------------------------/n");
printf("首先,请输入初始状态:/n");
Checkinput(org);
printf("然后,请输入目标状态:/n");
Checkinput(goal);
if(Canslove(org, goal))
{
//A*算法开始,先将初始状态放入OPEN表
printf("请输入搜索速度(默认速度是1):");
scanf("%f",&speed);
while((c = getchar()) != 10);
printf("搜索中,请耐心等待....../n");
Putinto(org,&Open);
result = Process(&org, &goal, &Open, &Closed, speed); //进行剩余的操作
printf("总步数:%d,搜索速度:%f/n",Shownum(result),speed);
printf("/n");
printf("Press Enter key to exit!");
while((c = getchar()) != 10);
}
else
printf("程序认定该起始状态无法道达目标状态!/n");
}作者声明:
本人July对本博客所有任何内容和资料享有版权,转载请注明作者本人July及出处。
永远,向您的厚道致敬。谢谢。July、二零一零年十二月二十三日。














 2118
2118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









