







最近又把muduo网络库仔细研究了一遍,收获良多。本文将对muduo中的设计思想以及关键的技术细节进行总结和分析,当然由于篇幅的原因这里更多的是对关键技术的简略提及,具体细节还需要读者自己去查找学习资料。
muduo/base
- Date类
- 日期类的封装,使用Julian(儒略日)可以方便的计算日期差。具体公式和思想见 儒略日的计算
- Exception类
- 异常类的封装,对外提供what()输出错误信息和stacktrace()函数进行栈追踪,使用时需要
throw muduo::Exception("oops");,外部使用catch (const muduo::Exception& ex)捕获并使用ex.what()/stackTrace()获取详细信息。
- 异常类的封装,对外提供what()输出错误信息和stacktrace()函数进行栈追踪,使用时需要
- Atomic类
- 原子性操作比锁的开销小,所以我们可以使用gcc提供的自增自减原子操作;最小的执行单元是汇编语句,不是语言语句。
- CountDownLatch类
- 既可用于所有子线程等待主线程发起“起跑”,也可用于主线程等待子线程初始化完毕才开始工作。其中使用RAII技法封装MutextLockGuard,hodler表示锁属于哪一个线程。
- TimeStamp类
- TimeStamp 继承至
less_than_comparable<>,使用模板元编程,只需要实现<,可自动实现>,<=,>=。
- TimeStamp 继承至
-
BlockingQueue
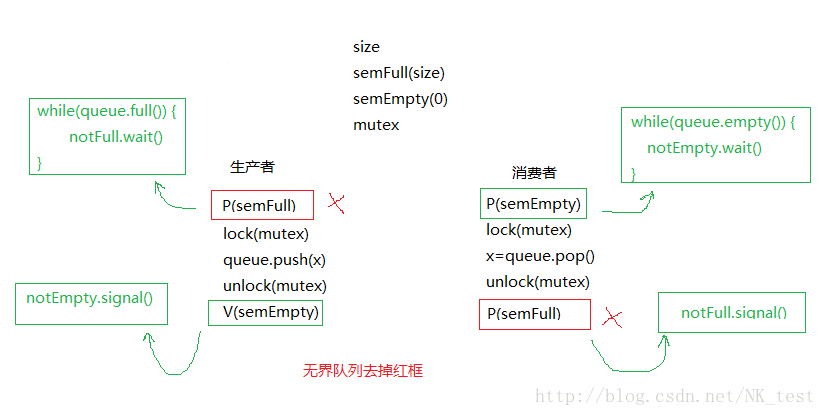
- BlockingQueue和BoundedBlockingQueue分别是无界有界队列,本质上是生产者消费者问题,使用信号量或者条件变量解决。ThreadPool的本质也是生产者消费者问题,任务队列中是任务函数(生产者),线程队列就相当于消费者。基本流程如下图:
- BlockingQueue和BoundedBlockingQueue分别是无界有界队列,本质上是生产者消费者问题,使用信号量或者条件变量解决。ThreadPool的本质也是生产者消费者问题,任务队列中是任务函数(生产者),线程队列就相当于消费者。基本流程如下图:
-
异步日志类
- 对于一般的日志类的实现,(1) 重载<<格式化输出 (2)级别处理 (3)缓冲区。
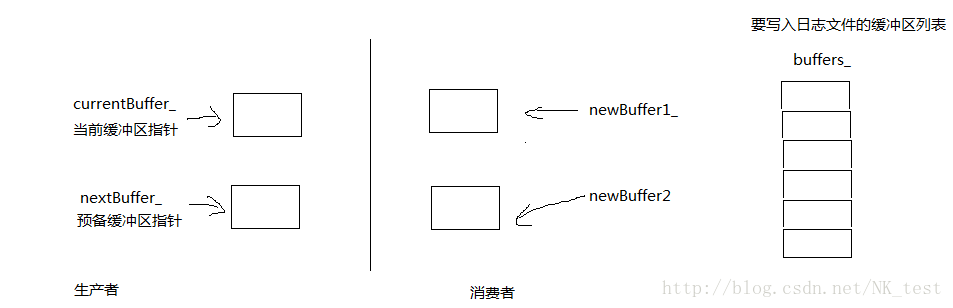
- 为了提高效率并防止阻塞业务线程,用一个背景线程负责收集日志消息,并写入日志文件,其他业务线程只管往这个日志线程发送日志消息,这称为异步日志。基本实现仍然是生产者(业务线程)与消费者(日志线程)和缓冲区,但是这样简单的模型会造成写文件操作比较频繁,因为每一次signal我们就需要进行写操作,将消息全部写入文件,效率较低。muduo使用多缓冲机制,即mutliple buffering,使用多个缓冲区,当一块缓冲区写满或者时间超时才signal;如果发生消息堆积,会丢弃只剩2块内存块。另外使用swap公共缓冲区来避免竞争,一次获得所有的消息并写入文件。
- __type_traits技法
- StringPiece是google的一个高效字符串类,其中使用了
__type_traits对不同类型进行了进一步优化。在STL中为了提供通用的操作而又不损失效率,traits就是通过定义一些结构体或者类,并利用模板给类型赋予一些特性,这些特性根据类型的不同而异。在程序设计中可以使用这些traits来判断一个类型的一些特性,实现同一种操作因类型不同而异的效果。可以参照 这篇文章了解。
- StringPiece是google的一个高效字符串类,其中使用了
muduo/net
-
reactor
- reactor+线程池适合CPU密集型,multiple reactors适合突发I/O型,一般一个千兆网口一个rector;multiple rectors(线程) + thread pool 更能适应突发I/O和密集计算。其中multiple reactors中的main reactor只注册OP_ACCEPT事件,并派发注册I/O事件到sub reactor上监听,多个sub reactor采用round-robin的机制分配。具体实现见EventLoopThread.
-
TcpConnection
- TcpConnection是对已连接套接字的抽象;Channnel是selectable IO channel,负责注册和响应IO事件,但并不拥有file descriptor,
Channel是Acceptor、Connector、EventLoop、TimerQueue、TcpConnection的成员,生命期由后者控制。
- TcpConnection是对已连接套接字的抽象;Channnel是selectable IO channel,负责注册和响应IO事件,但并不拥有file descriptor,
- TimerQueue类
- timers_和activeTimers_保存的是相同的数据,timers_是按到期时间排序,activeTimers_按照对象地址排序,并且timerQueue只关注最早
的那个定时器,所以当发生可读事件的时候,需要使用getExpired()获取所有的超时事件,因为可能有同一时刻的多个定时器。
- timers_和activeTimers_保存的是相同的数据,timers_是按到期时间排序,activeTimers_按照对象地址排序,并且timerQueue只关注最早
- runInLoop
- runInLoop的实现:需要使用eventfd唤醒的两种情况 (1) 调用queueInLoop的线程不是当前IO线程。(2)是当前IO线程并且正在调用pendingFunctor。
- rvo优化
- C++的函数返回vector之类或者自定义类型可以避免产生额外的拷贝构造函数、析构函数开销,返璞归真。
- shared_from_this()
- 获得自身对象的shared_ptr对象,直接强制转换会导致引用计数+1
- TcpConnection生命周期
- TcpConnection对象不能由removeConnection销毁,因为如果此时Channel中的
handleEvent()还在执行的话,会造成core dump,我们使用shared_ptr管理引用计数为1,在Channel中维护一个weak_ptr(tie_),将这个shared_ptr对象赋值给tie_,引用技术仍为1;当连接关闭,在handleEvent中将tie_提升,得到一个shared_ptr对象,引用计数就为2。
- TcpConnection对象不能由removeConnection销毁,因为如果此时Channel中的
- Buffer类
- 自己设计的可变缓冲区,成员变量
vector<char>、readIndex、writeIndex,同时处理粘包问题。Buffer::readFd()中的extraBuffer通过堆上和栈上空间的结合,避免了内存资源的巨额开销。先加入栈空间再扩充和直接扩充的区别就是明确知道多少数据,避免巨大的buffer浪费并且减少read系统调用。
- 自己设计的可变缓冲区,成员变量
muduo/examples
-
chargen测试服务器的吞吐量;千兆网卡跑满大概100M/s(1000M/8),机械硬盘的读写速度也就差不多也是这样,固态硬盘可以达到500M/s。
-
Filetransfer文件传输的时候,每次发送64k,然后再设置WriteCompleteCallback_再小块发送可以避免应用层缓冲区占用大量内存。
-
chat 多人聊天室,mutex保护vector,多条消息不能并行发送,存在较高的锁竞争。优化一:使用shared_ptr实现
copy_on_write,通过建立副本,达到并行发送消息的目的。优化二:消息到达第一个客户端和最后一个客户端之间有延迟,可以放在自己的IO线程中发送。 -
NTP网络时间同步
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其他关键技术点
- volatile
- 防止编译器对代码进行优化,对于用这个关键字声明的变量,系统总是从它所在的内存读取数据,不会使用寄存器中的备份。在Atomic.h中使用。
- __thread
- __thread修饰的变量是线程局部存储的,仅限于POD类型和类的指针;非POD类型可以使用线程特定数据TSD。
- 单例模式
- 一个类只有一个实例,并提供一个访问他的全局访问点。(1)私有构造函数。(2)类定义中含有该类的静态私有对象。(3)静态公有函数获取
静态私有对象。
- 一个类只有一个实例,并提供一个访问他的全局访问点。(1)私有构造函数。(2)类定义中含有该类的静态私有对象。(3)静态公有函数获取
- 异步回调的理解
- 所谓的异步回调,主线程使用poll/epoll进行事件循环,事件包括各种IO时间和timerfd实现的定时器事件。没有事件发生时阻塞在poll/epoll处,有事件发生时会对activeChannel进行遍历调用其中的回调函数。至于定时器是使用硬件时钟中断实现的,与sleep这种软件阻塞不同。所以我们常说的通过写消息来唤醒线程的含义就是触发一个IO事件,使得poll/epoll解除阻塞,向下得以执行回调函数。
- CAS无锁操作
- CAS原语有三个参数,内存地址,期望值,新值。如果内存地址的值==期望值,表示该值未修改,此时可以修改成新值。否则表示修改失败,返回false。无锁队列的实现可参照CoolShell。
- 注意无锁结构不一定比有锁结构更快,锁指令本身很简单,真正影响性能的是锁争用(Lock Contention)。当contention发生的时候,有锁的情况会陷入内核睡觉,无锁情况会不断spin,其中陷入内核睡觉是有开销的,这个开销当临界区很小的时候所占的比重就很大,这也就是lockfree在这种情况下性能提高很高的原因。lockfree的意义不在于绝对的高性能,他比mutex的有点是使用lockfree可以避免死锁/活锁,优先级翻转等问题,但是ABA problem、memory order等问题使得lockfree比mutex难实现得多。除非瓶颈已经确定,否则最好还是老老实实的使用mutex+condvar吧。
- 避免重复include多余头文件
- 在头文件中使用引用或者指针,而不是使用值的,使用前置声明,而不是直接包含他的头文件。
- 使用impl手法,简单来说就是类里面包含类的指针,在cpp里面实现。
- (void)ret
- 防止编译警告,变量未使用(限于release版本中 int n = …; assert(n==6))
- vim行首添加注释
- % 1,10s/^/#/g 在1-10行首添加#注释
参考资料
- muduo源码
- muduo使用手册
- 《linux多线程服务端编程》














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









